阿里云ODPS系列产品以MaxCompute、DataWorks、Hologres为核心,致力于解决用户多元化数据的计算需求问题,实现存储、调度、元数据管理上的一体化架构融合,支撑交通、金融、科研、等多场景数据的高效处理,是目前国内最早自研、应用最为广泛的一体化大数据平台。
DataWorks新重点能力介绍
- 新产品-DataWorks增强分析
- 新产品-DataWorks智能数据建模个人版
- 新功能-DataWorks支持EMR on ACK(Spark)
- 新功能-DataWorks数据集成入湖
- 新功能-DataWorks数据治理中心支持EMR
新产品
新产品-DataWorks增强分析
DataWorks与DataV-Card合作推出的AI增强分析产品,一站式完成从数据查询、分析、可视化、共享的完整链路。1分钟即可形成数据报告,帮助互联网、金融、政务等各个行业客户表达数据观点,讲好数据故事。
应用场景:
- 简化程序,降低成本: 以往数据分析工作流中,从数据仓库取数查询、到数据可视化、数据共享,需要要横跨多个产品,致使用户使用步骤繁琐,产品学习成本高。
- 海量数据查询: 基于MaxCompute等计算引擎强大的分析计算能力,DataWorks可直接针对海量数仓数据进行SQL取数查询,分析结果同时在DataWorks增强分析中进行可视化,形成数据「报告」并进行结果共享,极大提高了企业数据分析的效率。
功能特性:
- 数据查询: 基于MaxCompute等具有强大分析计算能力计算引擎,支持用户面向海量数仓数据进行SQL取数查询,具有追求极致简便、轻量化等特点。
- 数据卡片: 卡片内置常见图表,词云等组件。其作为数据运行结果的可视化资产,支持用户将观点备注至数据卡片中,形成专属数据可视化知识库,具有个性化,持久化等特点。
- 数据报告: 由多个数据卡片组成的数据可视化报告可以调整卡片顺序,挑选合适的报告主题。报告链接适配不同的展示需求,支持各行业用户表达自身数据观点,讲好数据故事,具有灵活性,多样化等特点。
产品demo演示-DataWorks增强分析
以公共数据集为例,浏览数仓数据进行SQL取数查询——开启DataWorks增强分析,对于查询数据结果经过图表,主题等调整,保存为可视化的数据卡片——卡片备注自身数据灵感,挑选数据卡片搭建数据报告,形成专属个人知识库——数据报告一键分享。
点击链接查看:
新产品-DataWorks智能数据建模个人版
DataWorks智能数据建模产品,从数仓规划、数据标准、维度建模、数据指标四个方面,以业务视角对业务的数据进行诠释,让数据仓库的建设向规范化,可持续发展方向演进。产品内置零售电子商务数据仓库行业模型模板,个人可以一键导入模板,DataWorks智能数据建模个人版6个月60元,开通后可以免费获取零售模型模板,并按照文档进行学习操作 。
应用场景:
- 找数用数: 解决业务指标出现“同名不同义,同义不同名”,业务找数难,找到的数不会不敢用,从而导致业务无法通过数据决策任务等用户痛点,并且解决数据异常,无法快速定位等业务问题。
- 降低成本: 数仓建模启动初期工作量巨大,人力成本高;线下建模效率低,缺少合适的工具;模型设计与数据研发、数据查找、数据消费工作脱节等痛点针对性解决。
功能特性:
- 与企业版功能一致: 数仓分层/维度建模/数据指标等功能与企业版功能均无区别,仅限主账号使用,为用户个人学习建模提供服务。
- 内置免费行业模型模版: 提供免费零售电子商务模型模板,数仓建模理论与实践结合,为用户个人学习数仓建模提供便利,提升学习效率。
- 与数据开发流程集成: 一站式模型设计与数据开发,多种建模方式,为用户个人快速完成多引擎模型物化与模型架构图绘制,自动生成ETL代码。
产品demo演示-基于零售电商模板实操流程
登录阿里云官网打开DataWorks智能数据建模寻找行业模型模板——载入模板,查看数仓分层查看数据域,查看数据集市和主题域——在维度建模中可以看到从模板导入的模型。也可选择创建模型,抑或通过代码模式来修改模型——将模型与数据开发打通,通过模型物化的物理表可以自动生成模型对应的ETL代码。
点击链接查看:
新功能
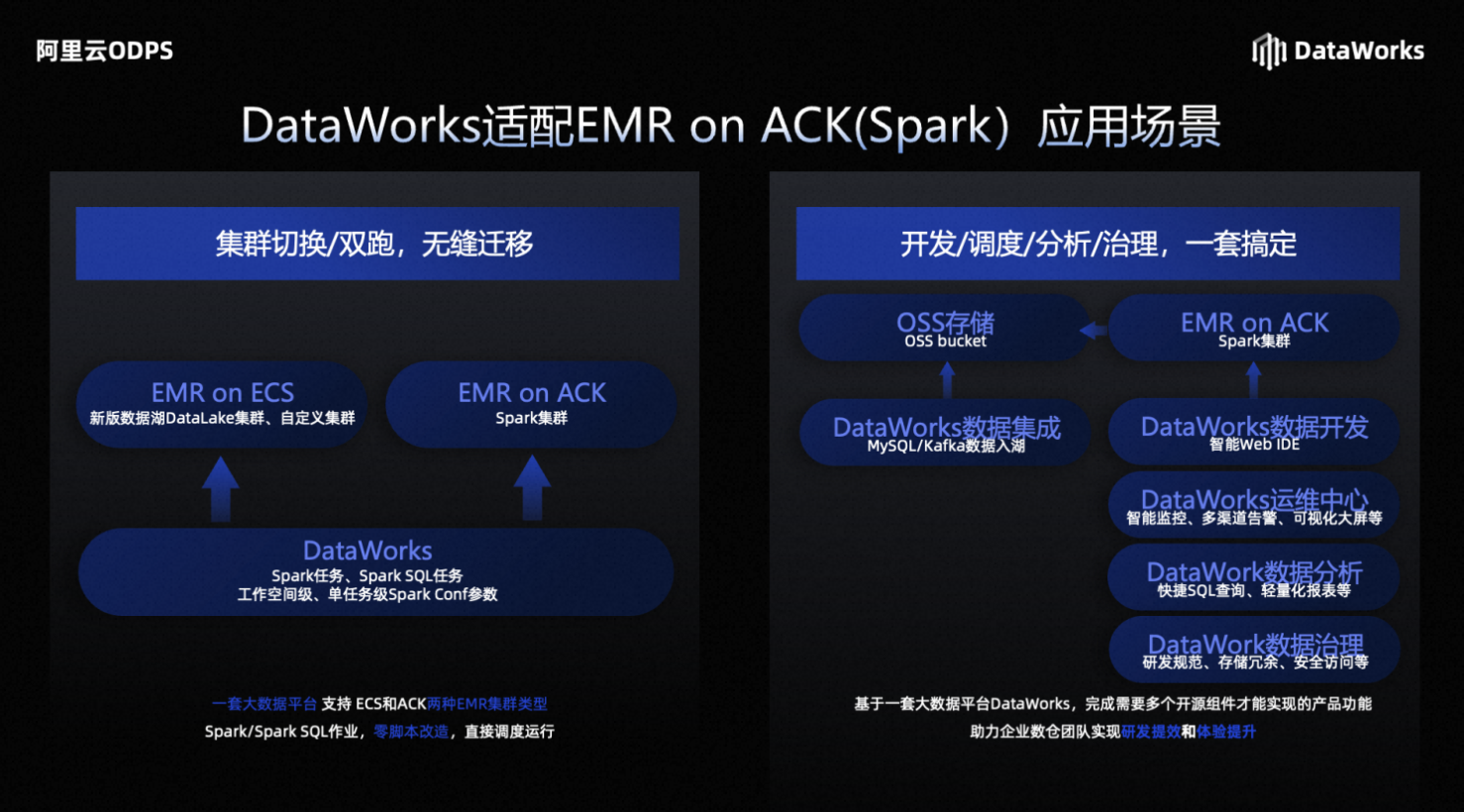
新功能-DataWorks支持EMR on ACK(Spark)
存量已适配EMR on ECS(DataLake/Custom)以及开源
应用场景
集群切换或者双跑可以进行任务的无缝迁移: 如果用户之前用的是ECS集群,想切换成ACK集群,或者两种集群同时运行,Spark任务都可以平滑的运行在这两种集群之上。
大数据的开发调度、分析和治理: 只需要开通一个DataWorks,就可以形成这个大数据的全家桶的生态。数据集成模块可以实现数据入户、数据开发和调度、数据分析和治理等等,一应俱全,可以完成需要多个开源组件才能实现的产品功能,来助力企业的数仓团队实现研发的提效和体验的提升。
![]()
功能特性:
DataWorks适配EMR on ACK(Spark)具有以下特性
根据ACK容器服务弹性能力按需灵活调整计算资源 ,若之前已保有ACK服务支撑在线服务和应用,那么本次就无需为大数据引擎单独购买ACK;
EMR Spark集群部署在ACK容器服务中,在创建EMR集群直接选择已经有的ACK,实现大数据服务和在线应用程序共享集群资源 ;
ACK容器服务本身具备良好弹性扩展能力,无论是水平、定时还是垂直伸缩,都能够通过丰富的弹性扩容方案来充分应对计算高峰期,整体达到资源合理利用、节省成本的效果。
专注Spark原生开发模式,无需关心底层集群差异 ;
支持多种调度周期,提供超大规模稳定调度,每日可以支撑千万量级的实力调度,并提供丰富的任务运维手段帮助用户及时处理任务执行异常,并发送相应监控告警;
基于ECS Spot抢占式实例进行调度适配与优化,本次DataWorks适配Spark集群,根据ACK抢占式实例做了专门的调度优化。
DataWorks数据治理中心提供丰富检查项,融入大数据开发流程,并且涵盖研发、存储、计算等多个方面的治理建议,形成了可量化的健康分指标,可以帮助企业在整个大数据过程中进行持续治理优化。
DataWorks相比开源大数据组件优势
DataWorks作为阿里云一站式开发和管理平台,是一款云上全托管产品,可以即开即用,无需像开源一样经过前期产品部署、环境部署等繁琐的流程。DataWorks相比开源具有以下几点优势:
数据集成 (DataX / Sqoop) :
- 基于DataX构建离线同步链路
- 基于Flink构建实时同步链路
- 封装多样化数据同步解决方案:提供多样化数据同步解决方案,覆盖整库同步、一次性全量同步、周期性增量同步等场景
- 数据通道丰富,配置链路简单,网络方案完备:在各种数据类型之间构建数据同步通道,让数据工具不再复杂和繁琐。
开发与调度(DolphinScheduler / Airflow):
- 丰富的原子任务类型 : DataWorks面向各种计算引擎提供多样化的任务类型
- 智能Web IDE + 可视化工作流编排:开发者可以通过可视化拖拽方式快速构建任务运行工作流,通过智能Web IDE高效编写任务代码
- 细粒度调度计划:对任务配置灵活的调度计划,无论是调度频率、重跑策略、复杂场景的依赖关系等等,都提供了非常完善和细致的功能;
- 全局运维大屏 & 单任务运维详情:任务上线以后,还可以通过运维大屏和运维手段来监控和处理运行的情况。
- 智能基线及时捕捉生产链路的异常
- 数据质量功能—严格监控控制脏数据污染下游
数据治理(Atalas等):
- 全面元数据纳管(技术/业务/操作元数据等)
- 支持系统自动解析/用户自助上报数据血缘
- 数据目录加强数据管理/提升找数效率
- 提供健康分量化体系、多维评估治理成效
- 敏感数据有效识别与保护等这一系列丰富产品功能和生态来形成组合拳的效果
新功能-DataWorks数据集成入湖
离线及实时同步数据至OSS/Hive
应用场景:
运维层面: 解决flink/spark streaming/kafka等运维优化调优,湖文件的管理:compaction, 清理历史文件, 清理过期分区,整个作业的实施性和高吞吐保障,开发/调试/部署/运维全生命周期等等都需要用户管理,运维难度大的痛点。
学习成本: 降低数据库binlog多样性解析需要专业知识储备,任务运维管理,flink、spark、kafka等技术引擎用户学习成本。
功能特性:
DataWorks数据集成入湖OSS具有以下特性
- MySQL整库同步至Hive: 支持实例模式、全量数据与增量过滤,增量过滤靠增量条件拉取增量,增量条件做出MySQL的VR条件过滤数据,其数据可以设置同步周期,用户也可以按照需求拉取数据。
- 上手简单: 全白屏向导化操作 ,支持用户直观入湖同步配置。
- 元数据自动打通: 与阿里云DLF深度打通融合 ,数据可以在入湖同步时自动注入DLF中,无需用户人为干预。
- 实时同步: 支持数据实时同步至OSS湖中,实现秒级延迟 ,并且支持用户同步过程中进行数据处理。
DataWorks入湖OSS能力支持的链路特性
支持MySQL数据增量实时入湖,秒级延迟
支持MySQL历史存量数据离线入湖,可以控制同步速率,避免影响源端业务
支持MySQL实例级别配置任务,同时同步一个实例下多库多表
支持按照正则感知MySQL端的库表变化,将增加的库表自动加入OSS湖端
支持OSS湖端自动建立元数据表
支持对接阿里云DLF,入湖元数据自动导入,实时可查
支持自定义OSS湖端存储路径
支持OSS湖端分区按日期自定义赋值
支持Kafka数据增量实时入湖,秒级延迟
支持数据中间进行简单的数据处理,包括数据过滤、脱敏、字符串替换等
支持字段级别赋值操作
支持kafka非结构化的JSON数据,可以根据同步过程中实时的数据,进行动态增加字段
支持OSS湖端自动建立元数据表
支持对接阿里云DLF,入湖元数据自动导入,实时可查
支持自定义OSS湖端存储路径
产品demo演示-MySQL入湖OSS
DataWorks控制台新建任务,输入任务名称,选择来源和去向,——demo演示中选择MySQL到OSS,选择整个入湖,选择mysql数据源,资源组,OSS数据源,然后进行联通测试。——测试完后,可以进入整个任务配置中,在任务配置中选取的来源需要同步表,选择外在存储路径,可以自动勾选是否同步到DIF中——确定之后建立一个OSS的分区。演示demo中按时间分区,配置运行中高级参数——点击完成配置整个任务配置完成
点击链接查看:
新功能-DataWorks 数据治理中心支持EMR
湖仓一体数据治理能力评估与优化
应用场景:
面向数据体量高速增长背景下,所需要完成的各类增效降本的治理场景,用户可通过DataWorks数据治理中心,面向存储、计算维度进行治理,系统提供数据计算任务优化、数据存储优化等治理功能,可帮助用户持续分析和优化数据存储及加工计算成本。
功能特性:
DataWorks数据治理中心 on EMR 具有以下特性
- 综合型治理健康分评估: 基于阿里云E-MapReduce及DLF衔接, 形成衡量全局、团队及个人的数据治理健康体系,让用户以统一的标准来明确数据治理的现状与需要达成的治理目标。
- 多维度治理问题发现: 综合性的治理健康系统覆盖研发、存储、安全、质量等多治理维度,并提供各维度下内置治理项规则,让用户持续发现同步任务、调度任务、数据表的各类问题并解决。
- 主动式治理问题拦截: 深度打通DataWorks数据开发链路, 在开发的任务提交、发布环节,主动帮助用户发现潜在数据治理问题,及时进行问题预防,实现数据治理与数据开发流程的融合,
产品demo演示-基于EMR进行数据成本优化场景实操
通过DataWorks控制台进入数据治理中心,了解总体治理健康分数及各维度健康情况——通过治理中心使用分析查看数据链路对于各类资源的总体消耗及数据调度任务的资源明细,在资源的明细里能针对EMR各类型任务去进行一个筛选,来查看具体资源消耗情况。——重点关注有大量资源异动消耗的任务,切换知识库查看系统当前支持的数据治理项,发现对应治理问题——定位问题进行事前检查,配置管理选择到对应工作空间,一键开启对应智力检查项——对于检查无法通过,拦截任务的提交,点击操作检查具体查看不符合治理规范内容,从而进行修复。
点击链接查看: