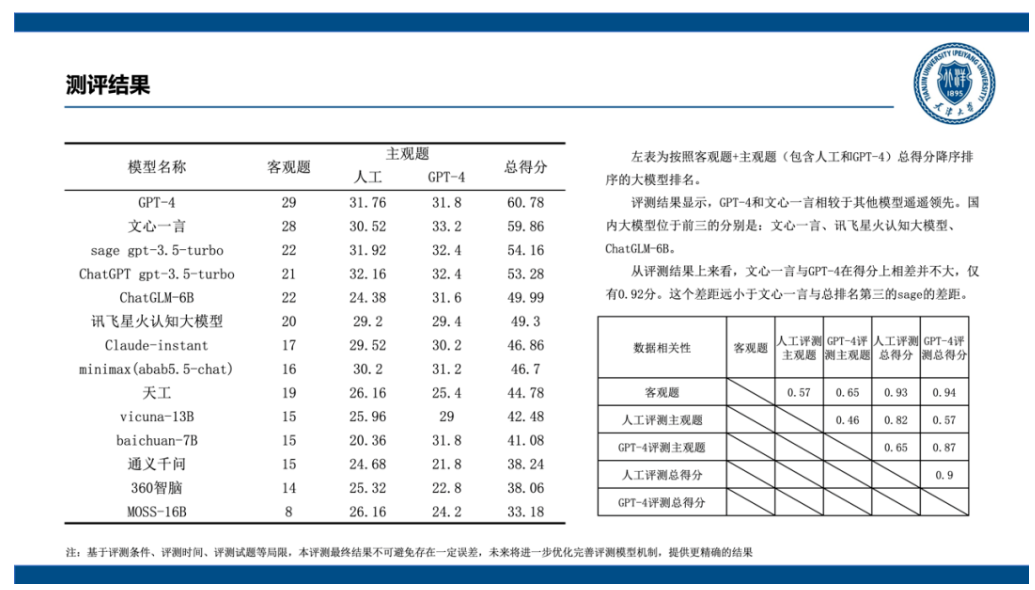
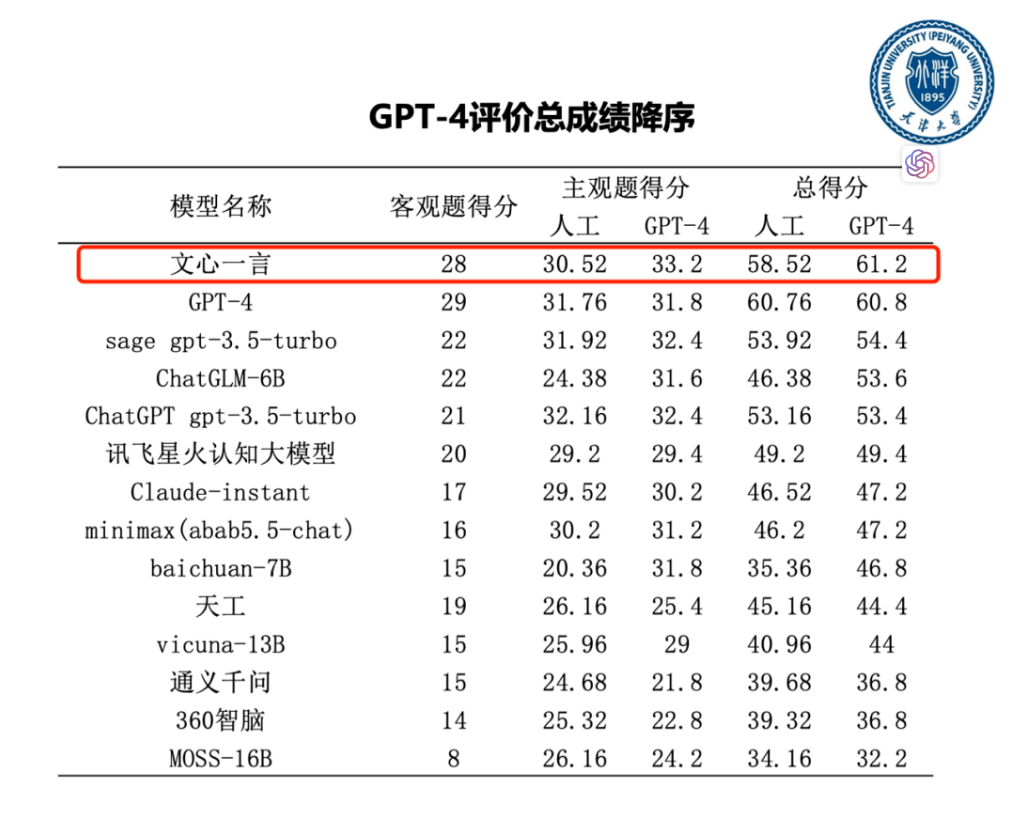

新国标支持带来了哪些变化?一文读懂
在社区GBCharactersEncoding SIG组的主导下,openKylin 1.0版本实现了对中文编码字符集国家标准GB18030-2022的全面支持。 近期社区很多小伙伴反馈不太了解新版国标支持具体会带来什么变化以及与老版国标的兼容性问题,因此社区专门邀请了GBCharactersEncoding SIG来为大家做一期讲解! 一、GB18030-2022升级概述 GB18030-2022的升级内容分为两类。 1、一类是新增编码字符,属于非破坏性变动。包含以下方面: 新增了CJK统一汉字新增的66个汉字字符; 新增CJK统一汉字扩充C,D,E,F汉字字符; 新增了康熙部首。 上述新增字符对应的编码在2005版本国标中已经存在,这次新增实际上只是将编码的对应位置填上字形,理论上对兼容性没有影响。 2、另一类是修改删除编码字符,属于破坏性变动。包含以下方面: 修改了10个竖排标点,8个汉字构件对应Unicode编码。 删除了6个汉字构件。 删除了9个汉字。 使用了这部分字符的程序,由于2022新标准的变更,理论上有可能出现无法显示,无法搜索等兼容性问题。 二、升级说明 上述...