在社区GBCharactersEncoding SIG组的主导下,openKylin 1.0版本实现了对中文编码字符集国家标准GB18030-2022的全面支持。
近期社区很多小伙伴反馈不太了解新版国标支持具体会带来什么变化以及与老版国标的兼容性问题,因此社区专门邀请了GBCharactersEncoding SIG来为大家做一期讲解!
一、GB18030-2022升级概述
GB18030-2022的升级内容分为两类。
1、一类是新增编码字符,属于非破坏性变动。包含以下方面:
- 新增了CJK统一汉字新增的66个汉字字符;
- 新增CJK统一汉字扩充C,D,E,F汉字字符;
- 新增了康熙部首。
上述新增字符对应的编码在2005版本国标中已经存在,这次新增实际上只是将编码的对应位置填上字形,理论上对兼容性没有影响。
2、另一类是修改删除编码字符,属于破坏性变动。包含以下方面:
- 修改了10个竖排标点,8个汉字构件对应Unicode编码。
- 删除了6个汉字构件。
- 删除了9个汉字。
使用了这部分字符的程序,由于2022新标准的变更,理论上有可能出现无法显示,无法搜索等兼容性问题。
二、升级说明
上述a中的改动使GB18030到Unicode的映射关系不再使用Unicode BMP的PUA编码,而是使用Unicode BMP的标准编码。这部分改动最大,影响编码转换、显示、字体、输入法和搜索等功能。
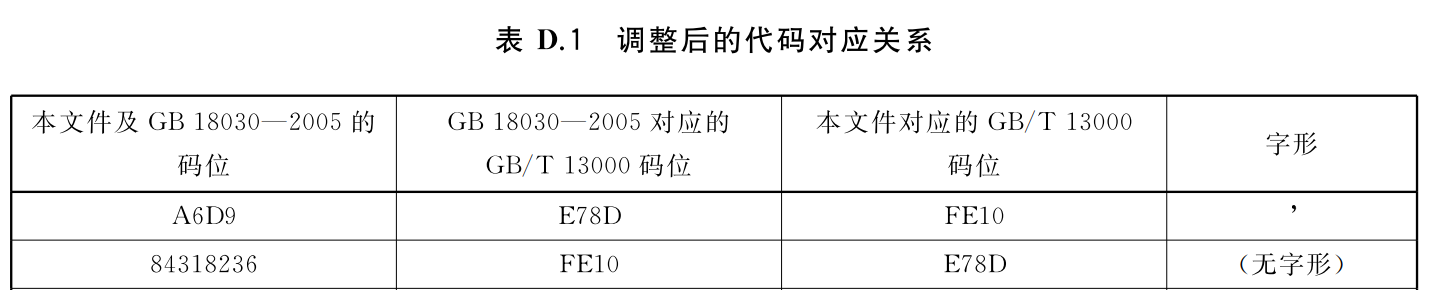
以国标编码A6D9和84318236为例。其对应关系变更如下所示:
从表中可知以下几点:
- 国标编码与字形的对应关系没有变。
- 国标编码对应的Unicode编码发生变化。
- 国标编码不再使用Unicode PUA编码表示逗号,而是与Unicode标准编码保持一致。
- Unicode编码FE10表示逗号。
- Unicode编码E78D不定义字形。
上述b中的改动是为了跟UNICODE标准保持一致,不再使用UNICODE BMP的PUA编码,相当于去掉了私有实现。主要影响字体、输入法和搜索。因为同一个字符既有标准编码,又有PUA编码,一般来说,使用标准编码的可能性更大一些。
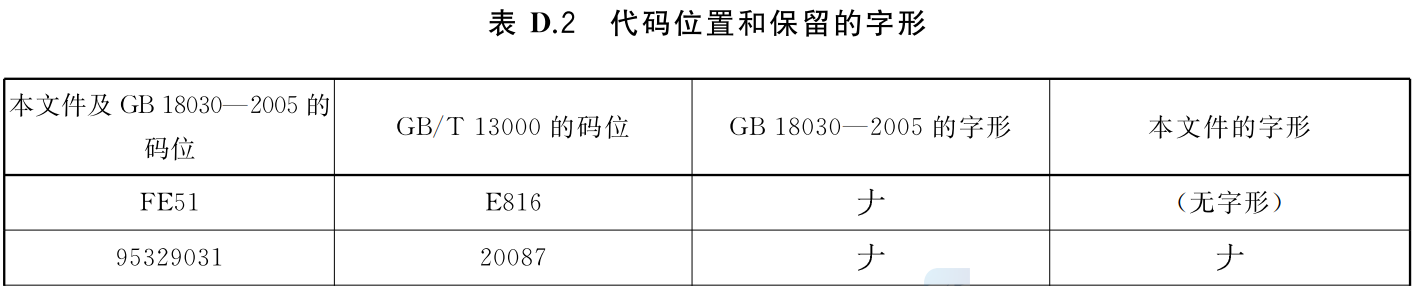
以国标编码FE51和95329031为例。其对应关系变更如下所示:
- 国标编码与字形的对应关系发生了变化,FE51没有了字形。
- 国标编码与Unicode编码的对应关系没有变。
- 国标编码不再使用Unicode PUA编码表示,而是与Unicode标准编码保持一致。
- Unicode编码20087表示。
- Unicode编码E816不定义字形。
而对于上述c中的改动,GB18030-2022和UNICODE的映射关系没有变化,主要是删除了对应的字符。但是,UNICODE还是有对应的字符的。此改动主要影响字体、输入法和搜索。
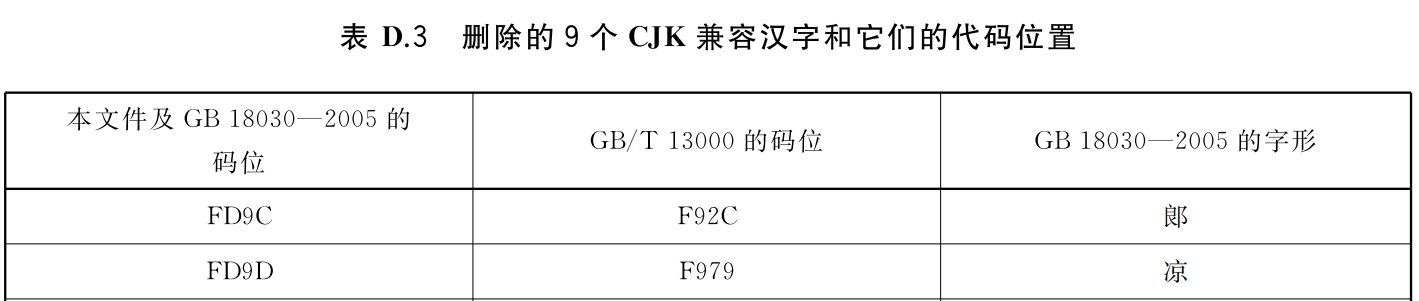
以国标编码FD9C为例。其对应关系变更如下所示:
- 国标编码与字形的对应关系发生了变化,FD9C没有了字形。
- 国标编码与Unicode编码的对应关系没有变。
- Unicode编码F92C依然表示CJK兼容汉字。
三、兼容性评估
1、升级后的系统对旧系统旧国标有较好的兼容性
在未升级系统上创建的GB18030-2005编码文档以及UTF-8编码文档,使用升级后系统中的常用程序可以正常显示和查找。显示效果和查找功能与未升级系统保持一致。
针对2022版国标的三个破坏性改动,系统的字体回落机制会保证系统的兼容性,2005和2022定义的字符均可完整支持。
2、可能存在的问题
由于升级后的系统对2005和2022定义的字符均可显示,并且2005定义的字符编码和2022标准之间存在冲突,这使得用户容易产生混淆。特别是当用户使用GB18030输入法输入了D1或D2中的字符去文档里面进行查找时,发现尽管存在该字符但会有无法找到的情况。
出现这种情况的原因就是GB18030输入法使用的是2022的编码标准,而文档则可能使用2005的标准显示了相同的字符。
四、关于GBCharactersEncoding SIG
openKylin社区GBCharactersEncoding SIG组持续关注新国标的落地施行,欢迎各位爱好者加入我们,为中文信息化世界添砖加瓦。
- GBCharactersEncoding SIG主页:
- https://gitee.com/openkylin/community/tree/master/sig/GBCharactersEncoding