简介
AbstractRoutingDataSource是Spring框架中的一个抽象类,可以实现多数据源的动态切换和路由,以满足复杂的业务需求和提高系统的性能、可扩展性、灵活性。
应用场景
- 多租户支持:对于多租户的应用,根据当前租户来选择其对应的数据源,实现租户级别的隔离和数据存储。
- 分库分表:为了提高性能和扩展性,将数据分散到多个数据库或表中,根据分片规则来选择正确的数据源,实现分库分表。
- 读写分离:为了提高数据库的读写性能,可能会采用读写分离的方式,根据读写操作的类型来选择合适的数据源,实现读写分离。
- 数据源负载均衡:根据负载均衡策略来选择合适的数据源,将请求均匀地分配到不同的数据源上,提高系统的整体性能和可伸缩性。
- 多数据库支持:在一些场景下,可能需要同时连接多个不同类型的数据库,如关系型数据库、NoSQL数据库等。根据业务需求选择不同类型的数据源,实现对多数据库的支持。
实现原理
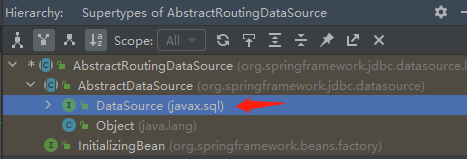
1.AbstractRoutingDataSource实现了DataSource接口,作为一个数据源的封装类,负责路由数据库请求到不同的目标数据源
![AbstractRoutingDataSource hierarchy.png]()
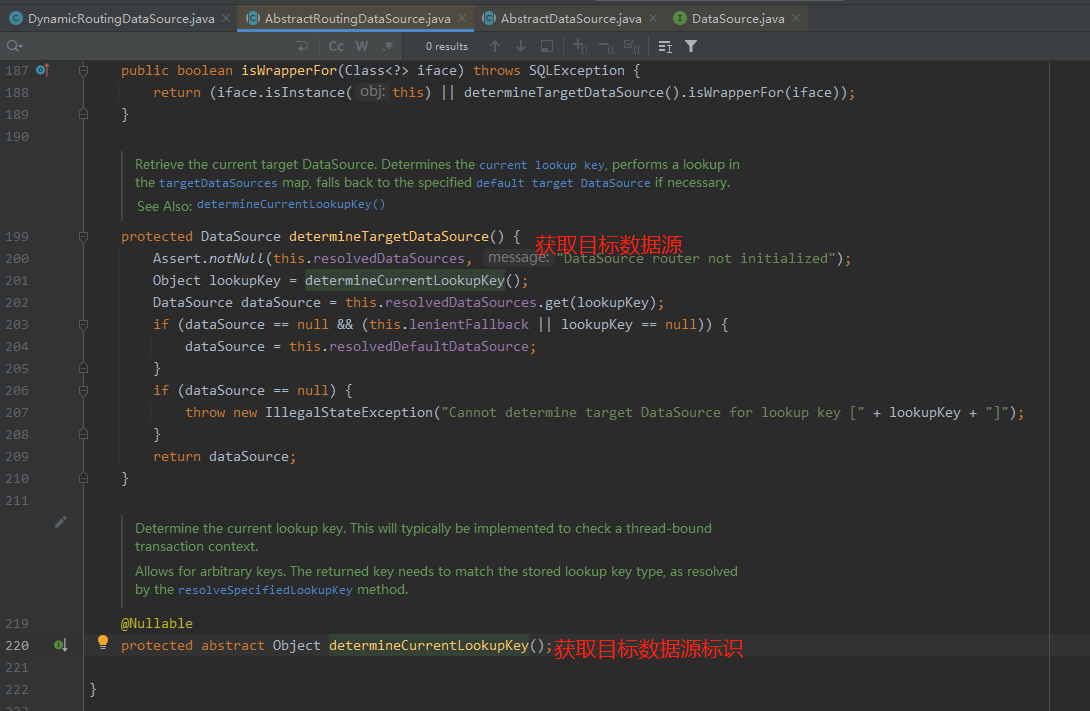
2.该类中定义了一个determineTargetDataSource方法,会获取当前的目标数据源标识符,进而返回真正的数据源;
值得注意的是:其中determineCurrentLookupKey为抽象方法,明显是要让用户自定义实现获取数据源标识的业务逻辑。
![determineTargetDataSource.png]()
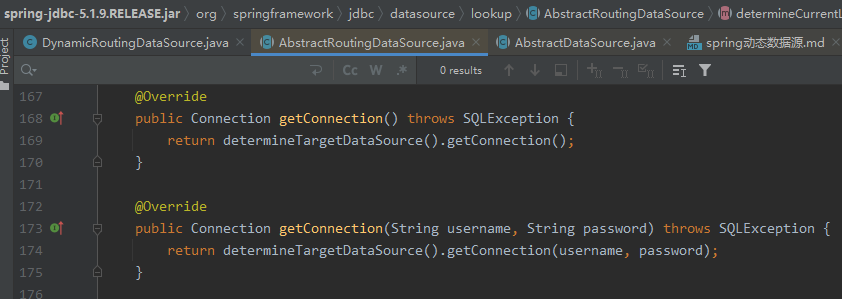
3.当系统执行数据库操作之前,会先获取数据源链接,即调用getConnection方法,该类重写的getConnection方法,会获取到真正的目标数据源,进而将数据库操作委托给目标数据源进行处理。
![getConnection.png]()
读写分离实现V1版
- yml中配置主从数据库连接信息
spring:
datasource:
business-master:
url: jdbc:mysql://ip1:3306/xxx
username: c_username
password: p1
business-slaver:
url: jdbc:mysql://ip2:3306/xxx
username: c_username
password: p2
2.读取yml中的主从数据源配置
@Data
@ConfigurationProperties(prefix = "spring.datasource")
@Component
public class DataSourcePropertiesConfig {
/**
* 主库配置
*/
DruidDataSource businessMaster;
/**
* 从库配置
*/
DruidDataSource businessSlaver;
}
3.自定义动态数据源类DynamicRoutingDataSource,继承AbstractRoutingDataSource类,并重写determineCurrentLookupKey方法,定义获取目标数据源标识的逻辑。
此处的逻辑为:定义一个DataSourceHolder类,将数据源标识放到ThreadLocal中,当需要时从ThreadLocal中获取。
public class DynamicRoutingDataSource extends AbstractRoutingDataSource {
/**
* 获取目标数据源标识
*/
@Override
protected Object determineCurrentLookupKey() {
return DataSourceHolder.getDbName();
}
}
public class DataSourceHolder {
/**
* 当前线程使用的 数据源名称
*/
private static final ThreadLocal<String> THREAD_LOCAL_DB_NAME = new ThreadLocal<>();
/**
* 设置数据源名称
*/
public static void setDbName(String dbName) {
THREAD_LOCAL_DB_NAME.set(dbName);
}
/**
* 获取数据源名称,为空的话默认切主库
*/
public static String getDbName() {
String dbName = THREAD_LOCAL_DB_NAME.get();
if (StringUtils.isBlank(dbName)) {
dbName = DbNameConstant.MASTER;
}
return dbName;
}
/**
* 清除当前数据源名称
*/
public static void clearDb() {
THREAD_LOCAL_DB_NAME.remove();
}
}
4.创建动态数据源DynamicRoutingDataSource对象,并注入到容器中。这里创建了主从两个数据源,并进行了初始化,分别为其设置了数据源标识并放到了DynamicRoutingDataSource对象中,以便后面使用。
若为多个数据源,可参考此处进行批量定义。
@Configuration
public class DataSourceConfig {
@Autowired
private DataSourcePropertiesConfig dataSourcePropertiesConfig;
/**
* 主库数据源
*/
public DataSource masterDataSource() throws SQLException {
DruidDataSource businessDataSource = dataSourcePropertiesConfig.getBusinessMaster();
businessDataSource.init();
return businessDataSource;
}
/**
* 从库数据源
*/
public DataSource slaverDataSource() throws SQLException {
DruidDataSource businessDataSource = dataSourcePropertiesConfig.getBusinessSlaver();
businessDataSource.init();
return businessDataSource;
}
/**
* 动态数据源
*/
@Bean
public DynamicRoutingDataSource dynamicRoutingDataSource() throws SQLException {
DynamicRoutingDataSource dynamicRoutingDataSource = new DynamicRoutingDataSource();
Map<Object, Object> targetDataSources = new HashMap<>(2);
targetDataSources.put("master", masterDataSource());
targetDataSources.put("slaver", slaverDataSource());
dynamicRoutingDataSource.setDefaultTargetDataSource(masterDS);
dynamicRoutingDataSource.setTargetDataSources(targetDataSources);
dynamicRoutingDataSource.afterPropertiesSet();
return dynamicRoutingDataSource;
}
}
5.自定义一个注解,指定数据库。
可以将一些常用的查询接口自动路由到读库,以减轻主库压力。
@Documented
@Inherited
@Target({ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface DataSourceSwitch {
/**
* 数据源名称,默认主库
*/
String dbName() default "master";
}
6.定义一个切面,拦截所有Controller接口,使用DataSourceSwitchRead注解的方法,将统一路由到读库查询
@Aspect
@Component
@Slf4j
public class DataSourceAspect {
/**
* 切库,若为多个从库,可在这里添加负载均衡策略
*/
@Before(value = "execution ( * com.jd.gyh.controller.*.*(..))")
public void changeDb(JoinPoint joinPoint) {
Method m = ((MethodSignature) joinPoint.getSignature()).getMethod();
DataSourceSwitch dataSourceSwitch = m.getAnnotation(DataSourceSwitch.class);
if (dataSourceSwitch == null) {
DataSourceHolder.setDbName(DbNameConstant.MASTER);
log.info("switch db dbName = master");
} else {
String dbName = dataSourceSwitch.dbName();
log.info("switch db dbName = {}", dbName);
DataSourceHolder.setDbName(dbName);
}
}
}
作者:京东科技 郭艳红
来源:京东云开发者社区