每一周,我们的同事都会向社区的成员们发布一些关于 Hugging Face 相关的更新,包括我们的产品和平台更新、社区活动、学习资源和内容更新、开源库和模型更新等,我们将其称之为「Hugging News」,本期 Hugging News 有哪些有趣的消息,快来看看吧!
重要更新
最新音频课程现已发布
![]()
近期,我们发布了一个音频处理课程,旨在让学员学习使用 transformers 处理音频,涵盖了包括音频数据处理技术、不同任务的 transformers 模型应用(如音频分类和语音识别)、音频 transformers 模型的架构和音频任务实践等一系列内容。通过学习这个课程,你将获得在音频数据处理方面的扎实基础,并能够将这些技术应用于各种音频相关任务中。
我们的第三四单元已经发布了,接下来的时间我们将于 6 月 28 日 发布第五单元、7 月 5 日发布第六单元,以及 7 月 12 日发布最后两个单元,如果你在 7 月底之前完成课程的学习和练习,还有机会获得官方的证书,快来学习吧! https://hf.co/learn/audio-course
邀请参与全球开源 AI 游戏开发挑战赛
![]()
还有 11 天,已经有 900 多名参与者报名!借助人工智能工具释放你的创造力,一起打破游戏开发的边界。本挑战赛将在北京时间 2023 年 7 月 8 日凌晨 1 点到 10 日凌晨 1 点间举行,限时 48 小时,查看 这篇文章 了解更多。
参与 OpenVINO™ DevCon 中国系列工作坊活动
![]()
生成式 AI 领域一直在快速发展,许多潜在应用随之而来,这些应用可以从根本上改变人机交互与协作的未来。邀请各位社区成员们参加我们和英特尔联合举办的 OpenVINO™ DevCon 中国系列工作坊活动!这是一次线上活动,时间是 6 月 30 日下午 13:30-14:50,请使用下面这个链接注册活动,或者查看我们 过去的文章 了解更多活动详细内容。
注册活动: https://huggingface.link/devcon
开源生态更新
gradio deploy 直接将你的 Gradio 应用部署到 Hugging Face!
![]()
这是把 Gradio 应用从本地部署到 🤗Spaces 的最快方法: gradio deploy,快来试试看吧!
🧨Diffusers 库支持 UniDiffuser pipeline
![]()
UniDiffuser 是清华大学朱军老师团队提出的一个为多模态设计的概率建模框架,你可以在机器之心的这篇文章里了解更多《清华朱军团队开源首个基于 Transformer 的多模态扩散大模型,文图互生、改写全拿下》,感谢社区成员 dg845 的贡献,现在你已经可以在 🧨Diffusers 中使用支持 UniDiffuser。
查看文档: https://hf.co/docs/diffusers/main/en/api/pipelines/unidiffuser 查看 UniDiffuser 开源代码: https://github.com/thu-ml/unidiffuser
PerSAM
![]()
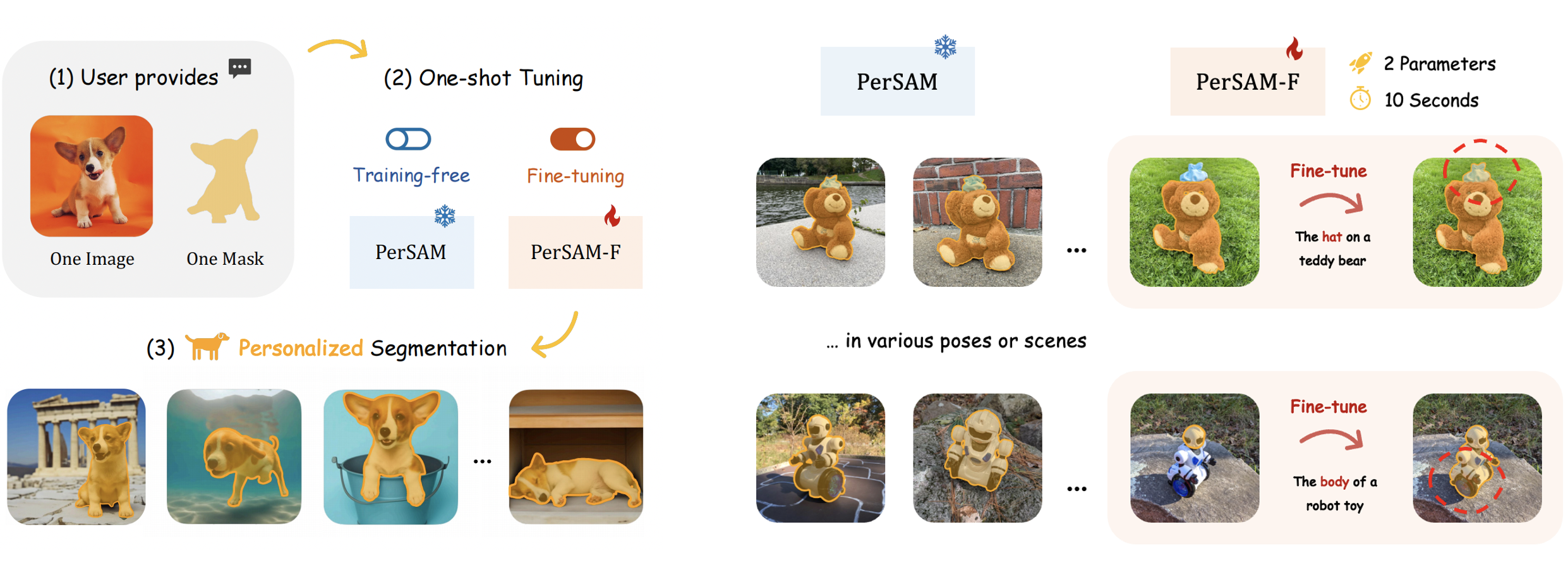
只需提供一张包含目标物体和参考掩码的图像,PerSAM (Personalization Segment Anything Model) 就可以在其他图像或视频中准确地分割目标物体,无需额外的训练。PerSAM 旨在自动对 Segment Anything Model (SAM) 进行个性化定制,以在照片相册中自动分割特定的视觉概念,例如你的宠物狗狗。
论文页面: https://hf.co/papers/2305.03048 Space 应用: https://hf.co/spaces/justin-zk/Personalize-SAM Notebooks 链接: https://github.com/NielsRogge/Transformers-Tutorials/tree/master/PerSAM GitHub 链接: https://github.com/ZrrSkywalker/Personalize-SAM
MQA 技术: 更长的文本、更少的内存占用
![]()
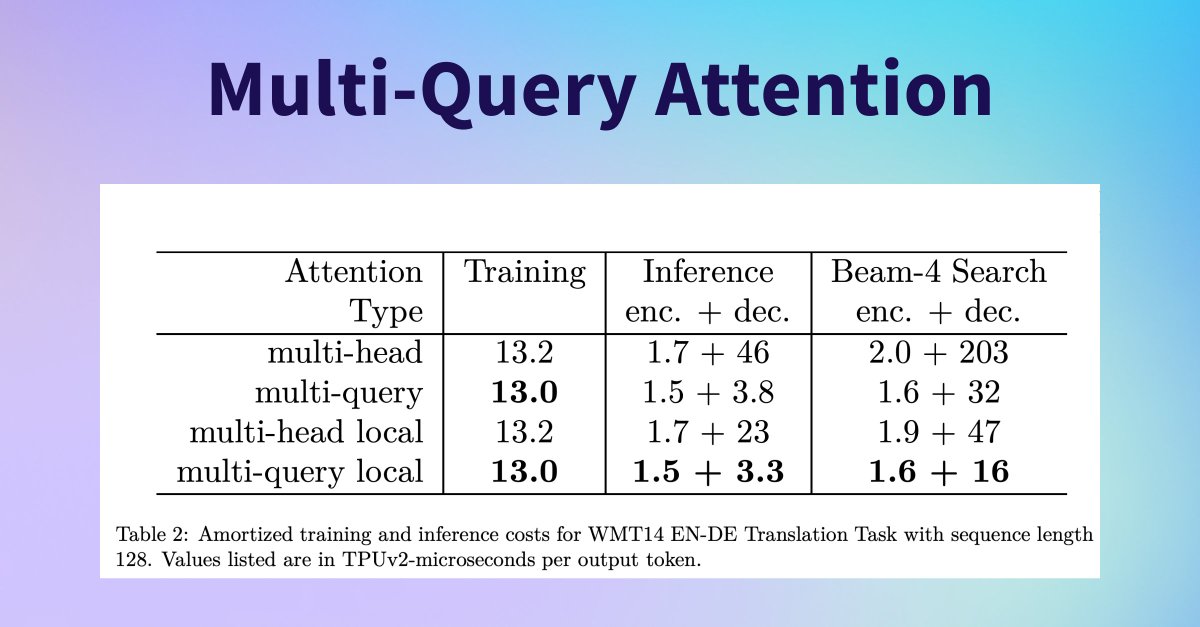
由于在多头注意力机制之间共享关键矩阵和值矩阵,MQA (Multi-query attention) 可以使用更少的内存能够生成更长的文本,这个技术的出现为使用大型语言模型带来了更多的可能性,生成更长的文本变得更加高效和便捷,现在已经有两个采用了 MQA 的语言模型: StarCoder 14B 和 Falcon 7B/40B。
查看论文: https://hf.co/papers/1911.02150
开源生态压轴出场
baichuan-7B: 免费可商用大语言模型
![]()
baichuan-7B 是由百川智能开发的一个开源的大规模预训练模型。基于 Transformer 结构,在大约 1.2 万亿 tokens 上训练的 70 亿参数模型,支持中英双语,上下文窗口长度为 4096。在标准的中文和英文权威 benchmark (C-EVAL/MMLU) 上均取得同尺寸较好的效果。
即刻体验百川-7B 模型: https://hf.co/spaces/ysharma/baichuan-7B
ChatGLM2-6B 重磅发布,荣登 Hugging Face 趋势榜单之首!
![]()
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,在保留了初代模型对话流畅、部署门槛较低等众多优秀特性的基础之上,ChatGLM2-6B 具有更强大的性能、更长的上下文和更高效的推理。
了解更多: https://hf.co/THUDM/chatglm2-6b
以上就是上周的 Hugging News,新的一周开始了,我们一起努力!