我国电力行业发展迅速,电表作为测电设备经历了普通电表、预付费电表和智能电表三个阶段的发展。在产业场景中,表的种类多达十几种,过去依赖人工抄表,成本很高。如果能够采集到大量电表图片,借助人工智能技术批量检测和识别,将会大幅提升效率。
本次飞桨产业实践范例库开源电表读数识别场景应用,提供了从数据准备、技术方案、模型训练优化,到模型部署的全流程可复用方案,降低产业落地门槛。
⭐项目链接⭐
https://github.com/PaddlePaddle/awesome-DeepLearning
所有源码及教程均已开源,欢迎大家使用,star鼓励~
基于深度学习技术
实现电表读数识别
本场景要解决多类别电表识别任务,从技术上需要对多种类别的电表表数和表号进行检测再识别,从数据到模型面临着多重问题。
项目难点:
本项目将一一解决这些难点。
![125c26eee2a802a3851070750a5137cf.png]()
项目方案:
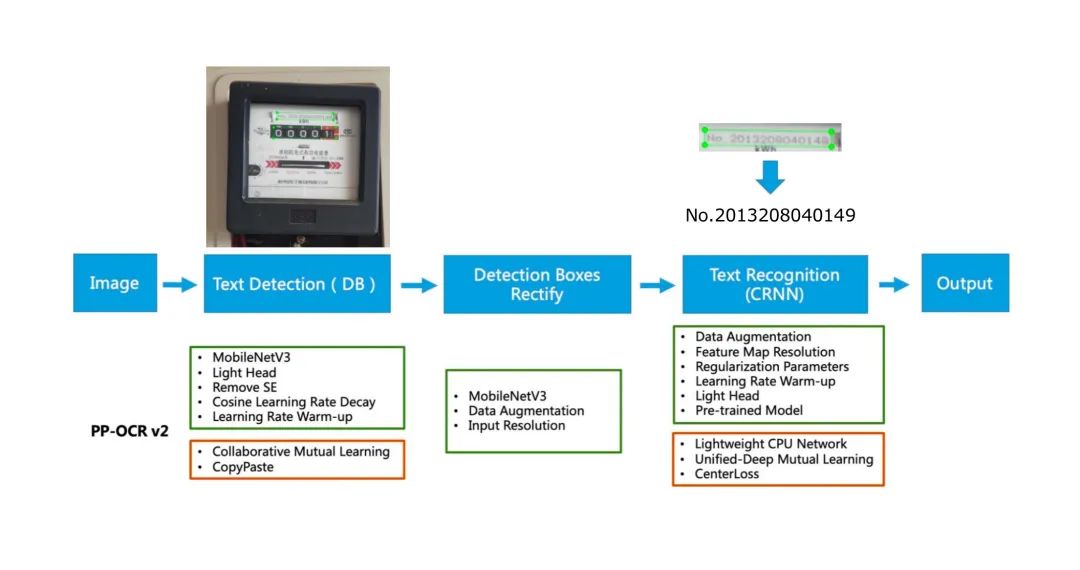
基于上述难点,飞桨开发者技术专家不断进行尝试,最终选用了飞桨文字识别套件PaddleOCR中的PP-OCR模型进行了微调与优化,其检测部分基于DB的分割方法实现,直接解决了电表数据中的倾斜问题,通过再造数据集来扩充识别数据集,训练识别模型。PP-OCR模型经过大量实验,其泛化性也足以支撑复杂垂类场景下的效果。
![55ebe92b02890daa80f56babde0fcb4d.png]()
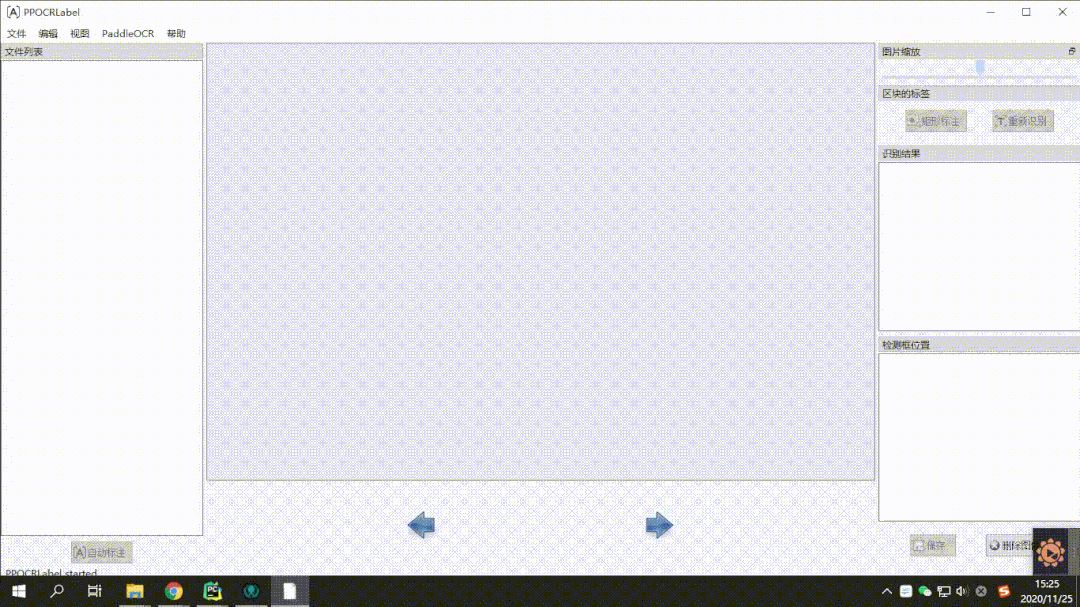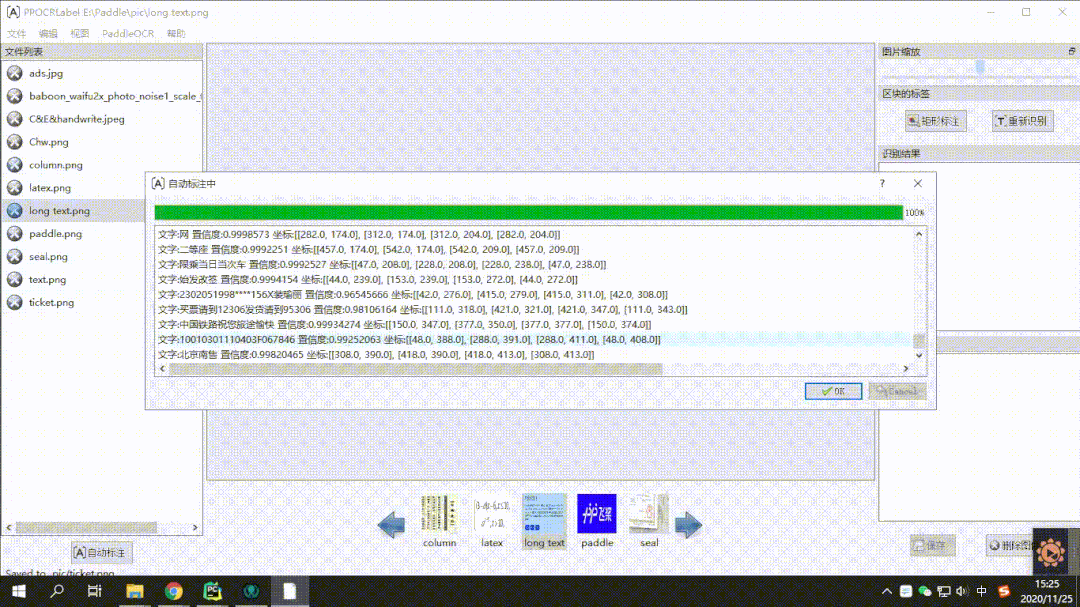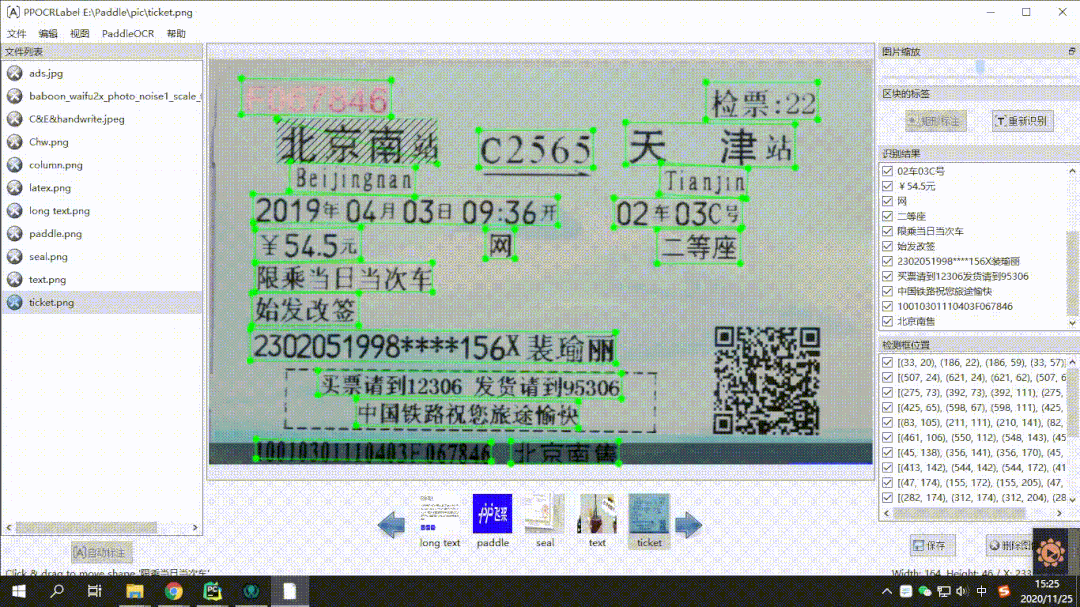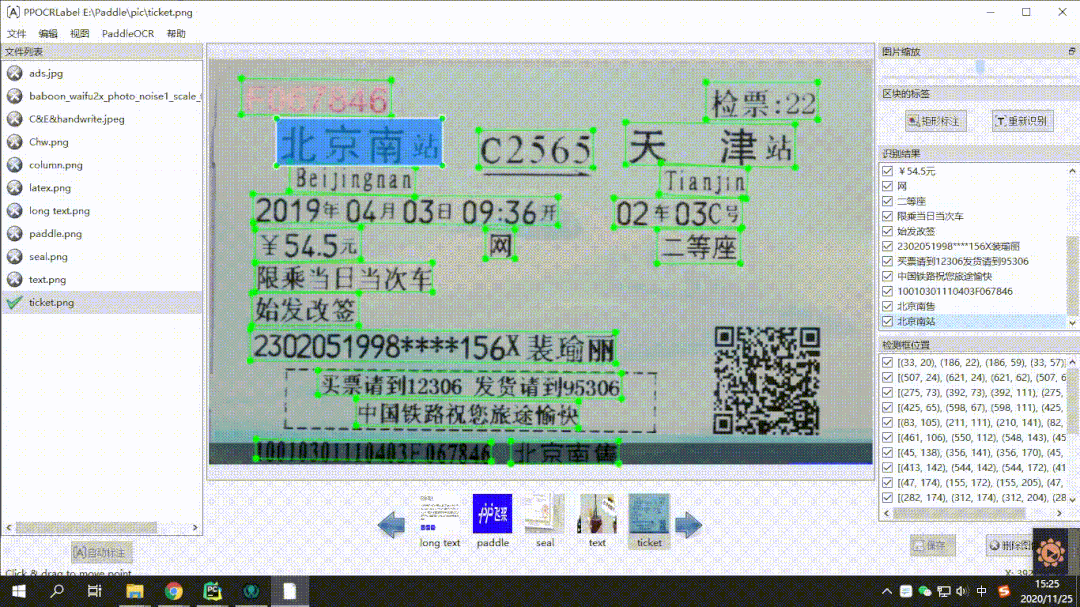
在数据标注工具上,使用PPOCRLabel实现半自动标注,内嵌PP-OCR模型,一键实现机器自动标注,且具有便捷的修改体验。支持四点框、矩形框标注模式,导出格式可直接用于PaddleOCR训练,标注效率显著提升。
![35c5c6480ef1a85410b026df8c695fa5.gif]()
方案优化:
在优化方面,首先对PP-OCR模型的检测部分进行初步微调,然后通过对数据的进一步分析,发现原始图像分辨率较大,进而调整EastRandomCropData的尺寸,放大输入模型前的图像尺度。通过CopyPaste数据增强解决数据量小的问题,并且根据实际情况调小学习率。
项目效果:
最终在评测数据集上从原先的Hmeans=0.3优化到0.85。除此之外,本项目也尝试了一部分目标检测算法。具体的优化过程和详细解释,欢迎大家关注直播!
![fe71824572d54f911ac1cf1b91a68de6.png]()
微调前后对比
部署方面使用飞桨原生推理库Paddle Inference完成,满足用户批量预测、数据安全性高、延迟低的需求,快速在本地完成部署方案。
产业实践范例教程
助力企业跨越AI落地鸿沟
飞桨产业实践范例,致力于加速AI在产业落地的前进路径,减少理论技术与产业应用的差距。范例来源于产业真实业务场景,通过完整的代码实现,提供从数据准备到模型部署的方案过程解析,堪称产业落地的“自动导航”。
精彩课程预告
为了让小伙伴们更便捷地应用电表读数范例教程,我们邀请了飞桨开发者技术专家于3月3日20:30-21:00为大家深度解析从数据准备、方案设计到模型优化部署的开发全流程,手把手教大家进行代码实践。
欢迎小伙伴们扫码进群,免费获取直播课和回放视频链接,更有机会获得覆盖智慧城市、工业制造、金融、互联网等行业的飞桨产业实践范例手册!也欢迎感兴趣的企业和开发者与我们联系,交流技术探讨合作。
扫码报名直播课,加入技术交流群
![422788e11e8ebba17e6942d7e4c761dd.png]()
![00f828ea664fe528a38b47cf1b35c74a.png]()
![5c469cdc880278f435b1b2c5c6635b90.gif]()
关注飞桨公众号,获取更多技术内容~