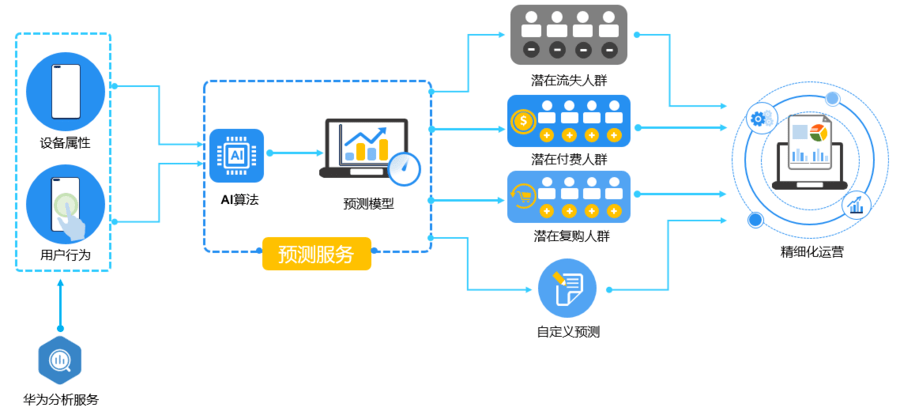
预测服务基于华为分析服务(Analytics Kit)上报的用户行为数据和属性,结合机器学习技术,实现特定目标人群的精准预测。针对预测生成的细分受众群体,开展和优化相关运营举措,如通过A/B测试评估运营活动效果、远程配置特定受众群体的专属套餐等,可有效帮助产品提高用户留存,增加转化。
![]()
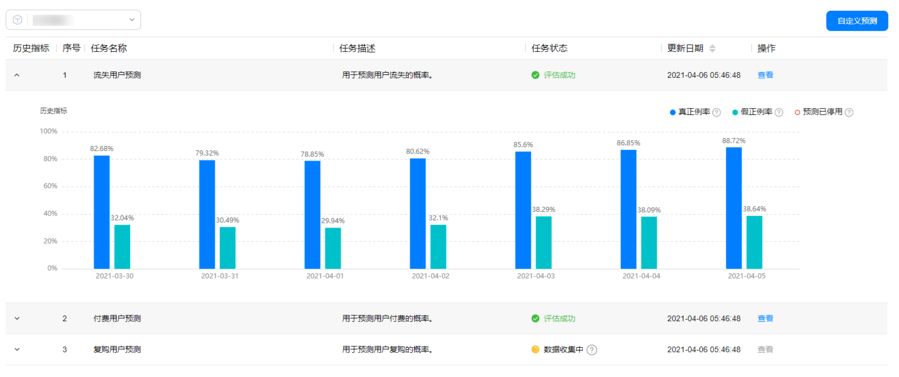
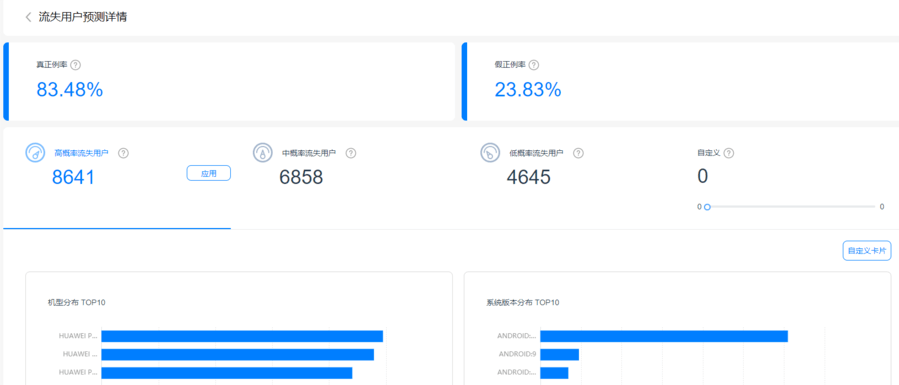
使用预测服务前,需要先集成华为分析服务的SDK,这样系统才可以顺利开展流失、付费、复购以及自定义预测任务。在详情界面可以查看相关预测人群的高中低概率对应人群数量,及其相应的属性分布(比如详情页的高概率流失人群,表示该人群在未来7日内有较高概率流失,您可以通过相关卡片,观察其行为特点并制定针对性运营计划)。
预测任务和预测详情界面如下所示:
![]()
![]()
*数据为模拟
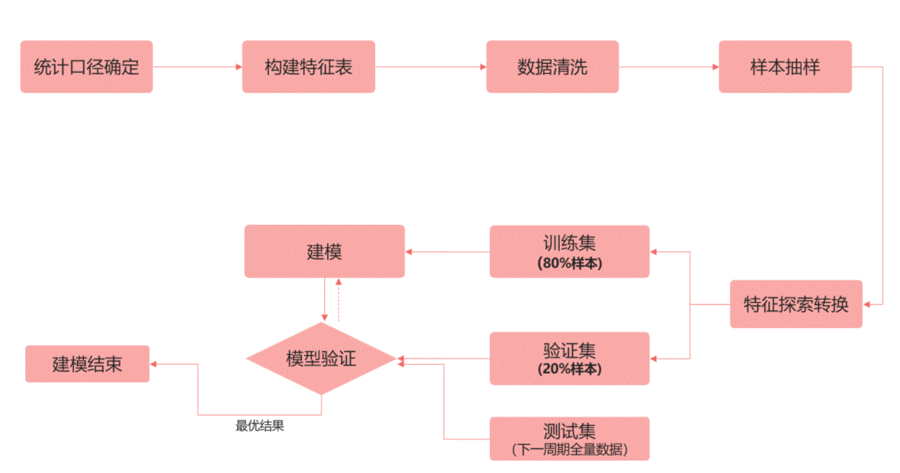
预测模型构建流程
在构建预测模型的时候,首先是确定我们要预测什么,即确立预测的统计口径,然后根据统计口径围绕用户特点寻找对应相关的特征,通过清洗和采样得到数据集。我们把数据集二八分得到训练集和验证集,在线下进行不断实验找到最优特征和参数,最后根据相关数据在线上调度训练预测任务。
具体流程图如下所示:
![]()
特征、模型选择和调优
特征探索
项目初期,我们分析数据,从属性、行为、需求三方面入手,寻找与业务有可能相关的变量,构建特征表,比如用户近7天的活跃天数、使用时长等行为数据。
在确定特征之后,下一步就是在实验中进行模型的选择和调优了,业界常用的树形模型有xgboost、随机森林、GBDT等,把我们的数据集用这几种模型进行训练,发现在随机森林上效果较好,其采用bagging策略提高模型拟合能力和泛化能力。
除了模型参数,也要考虑采样比,尤其是对于付费预测这种正负样本悬殊的情况(大约1:100),综合考虑Accuracy和Recall, 付费训练时将正负样本比例采样至1.5:1, 以提高模型付费用户召回率。
超参与特征确立
训练出了合适的模型,但并非所有特征都是有用的,无用特征除了可能会影响模型效果,也会减慢训练速度。在初期版本中,通过实验确定合适的超参和特征,特征按照特征重要性排序选择权重较大的,在线上版本中配置对应的超参和特征。
在版本上线之后还需要不断观察数据、分析数据、补充特征,我们在后续版本中主要新增了事件特征与趋势特征,补充后总计400+特征。
自动超参搜索
在挖掘出更多的特征之后,如果都是全量特征训练可能效果未必会好,而且也会非常耗时。同时,可能每个App训练时可能最优的超参和特征并不相同,最好是每个App分开训练且使用自己最优的超参和特征。
为了解决这些问题,我们增加了自动的超参搜索,可以在配置好的参数空间里搜索,找到并保存合适的训练参数。搜索完之后的最优超参保存在如下结构的hive表中。
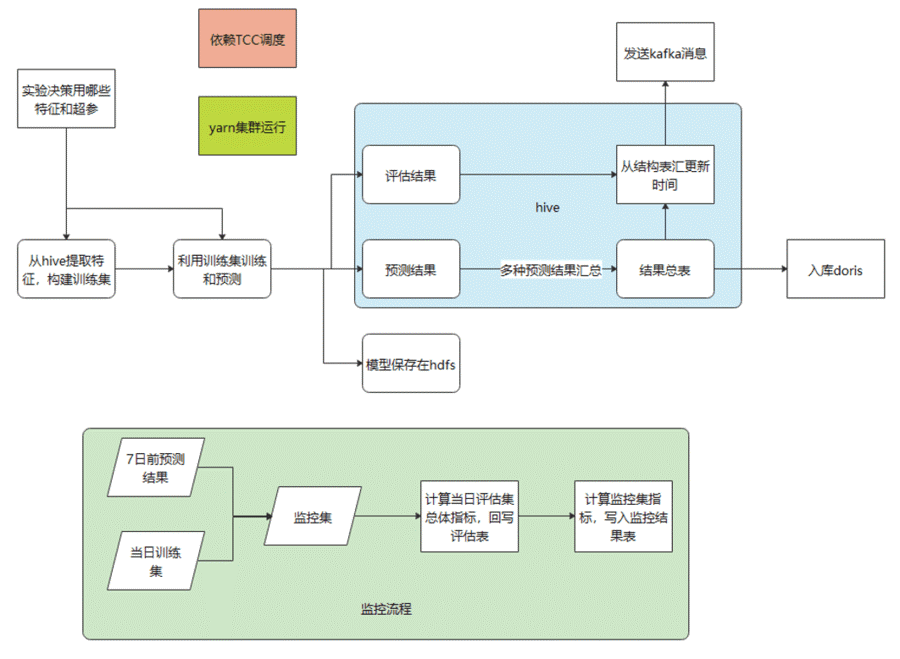
当前的整体流程以及外部依赖如下所示:
![]()
未来方向
在未来提高模型效果上,我们也有很多思考,预研的方向大致如下:
当前的特征规模不断扩大(400+),而用户行为的规律又十分复杂,除了使用原有的树形模型,也在尝试利用神经网络强大的表达能力,结合行为特征训练出更准确的预测模型。
对于各App、各租户数据不可互通的问题,可以通过横向联邦学习联合各个App、各个租户间的模型,在数据不互通的前提下协同训练。
不同App的用户每周上报数百个事件(涵盖1000+种类),访问近百个页面,通过这些时序数据可以构造出不同用户的长短期行为特征,提高不同场景预测的准确率。用户访问页面的行为有较高的时序特点,可以加工成时间序列特征,有较高的研究价值。
对目前的特征集扩充、补充,一方面挖掘更多的相关特征比如平均使用间隔、设备属性、安装渠道、国家省市等特征。另一方面基于现有特征通过离散化、归一化、开方、平方、笛卡尔积、多重笛卡尔积等等方法构造更多新特征。
>>了解更多华为预测服务详情
>>访问华为开发者联盟官网,了解更多相关内容
>>获取开发指导文档
>>华为移动服务开源仓库地址:GitHub、Gitee
点击右上角头像右方的关注,第一时间了解华为移动服务最新技术