引言
蓝鲸容器服务(Blueking Container Service,以下简称BCS)是腾讯 IEG 互动娱乐事业群的容器上云平台,底层基于腾讯云容器服务(Tencent Kubernetes Engine, TKE),为 IEG 的自研游戏业务上云提供容器化和微服务化的建设工作。 区别于一般互联网业务,腾讯游戏业务具有大规模、低时延、网络敏感、超高可靠性要求等一系列众多特点,大量使用共享内存通信等技术,对云原生上云是一个巨大的挑战。BCS 在服务于各游戏业务的容器上云过程中,结合业务需求与社区方案,开发了两个增强版的 Kubernetes 工作负载 operator:GameStatefulSet 和 GameDeployment,更贴近业务场景,满足复杂多样的容器上云需求。
游戏业务特性的复杂性
游戏类业务具有多种类型,如房间类游戏、MMO 游戏。无论是哪种类型的游戏,都有诸如大规模的在线玩家、对网络时延和抖动异常敏感、多区多服等特点,游戏后台服务在设计时为了满足这些需求,天然地会追求实时高速通信、性能最大化,大量地使用了进程间共享内存通信、数据预加载进内存、跨主机 TCP 通信等技术,极少使用远程数据、RPC,这其实与微服务的要求有点背道而驰。 结合容器化上云的需求,总结来说,游戏类服务一般具有以下特性:
- 大量地使用共享内存技术,偏有状态服务。
- 超大规模,分区分服,需要能做到分批灰度发布,为减少运维难度,最好能实现智能式控制,控制发布规模、速度、步骤。
- 实例扩缩容或更新时需要进行数据搬迁,不能马上退出服务。
- 缩容一个实例前,需要先完成路由变更。如微服务名字通信网格,在缩容一个实例前先要跟名字通信网格的 controller 进行交互,确认是否已完成路由变更,再决定是否删除实例。
- 开房间对局类游戏在缩容或更新前,需要等待实例上的所有对局结束后,再退出服务。
- 为了保证平滑升级,有些游戏后台服务使用了进程 reload 技术,reload 过程中新版本的进程接替旧版本的进程提供服务,内存数据不丢失,升级过程中玩家无感知。
所有这些特点,对于 Kubernetes 和云原生上云都是巨大的挑战。Kubernetes 原生适合微服务架构,把所有实例当作牲畜而不是宠物。即便是推出了 StatefulSet(最开始起名为 PetSet) 来支持有状态服务,也只是给每个实例设定一个网络和存储的编号,即使实例挂了,拉起一个相同编号的实例代替即可,并不涉及到共享内存丢失、数据搬迁、路由变更等复杂的流程。这也是后来 PetSet 被改名为 StatefulSet 的原因。 要支持游戏这类复杂业务的上云,我们需要更进一步,开发更贴合业务场景的 workload,降低业务接入的门槛和成本。
BCS New Workload: GameDeployment & GameStatefulSet
BCS 在服务于腾讯 IEG 众多不同类型的包括但不限于游戏业务的容器上云过程中,与各游戏业务及平台探讨业务场景,抽象业务共性和需求,同时积极学习和借鉴云原生社区的优秀开源项目如 OpenKruise,argo-rollouts,flagger 等,在 Kubernetes 原生及其它开源项目的基础上,研发了 bcs-gamedeployment-operator 和 bcs-gamestatefulset-operator 两个 operator,分别对应 GameDeployment 和 GameStatefulSet 两个增强版的 Kubernetes 工作负载,在原生的 Deployment 和 StatefulSet 基础上实现了一系列增强的特性和性能提升,以满足复杂业务的云原生上云需求。 GameDeployment 和 GameStatefulSet 虽然是在服务于游戏业务的的场景中产生,但我们为其抽象出来的特性,其实能契合大多数类型业务特别是复杂业务的需求,更强的可控性,更贴近业务的研发和运维发布场景,能极大提升云原生上云的能力。
GameDeployment
Kubernetes 原生的 Deployment 是面向无状态服务的工作负载,其底层是基于 ReplicaSet 来实现,一个 Deployment 通过控制底层多个版本的 ReplicaSet 的版本数量来实现应用的滚动更新和回滚。 虽然是无状态服务,大多数应用仍有 pod 原地升级、pod 镜像热更新(下文单独)等其它一些需求,而原生的 Deployment 由于是基于多个版本的 ReplicaSet 迭代来实现,实现较为复杂,想要在其中添加原地升级等功能比较困难。 我们在借鉴原生的 Deployment 和 StatefulSet 的代码实现的基础上,参考了其它开源项目,研发实现了一个增强版的 Deployment: GameDeployment,以满足复杂的无状态应用的更多高阶需求。 相比 Deployment,GameDeployment 具有以下一些核心特性:
- 支持滚动更新 RollingUpdate。
- 支持 pod 原地升级
- 支持 pod 容器镜像热更新
- 支持 partition 灰度发布
- 支持智能式分步骤灰度发布,可在灰度发布步骤中加入 hook 校验
- 支持删除或更新 pod 前的 hook 校验,以实现优雅的 pod 退出
- 支持原地重启前的镜像预拉取,以加快原地重启的速度
apiVersion: tkex.tencent.com/v1alpha1
kind: GameDeployment
metadata:
name: test-gamedeployment
labels:
app: test-gamedeployment
spec:
replicas: 5
selector:
matchLabels:
app: test-gamedeployment
template:
metadata:
labels:
app: test-gamedeployment
spec:
containers:
- name: python
image: python:3.5
imagePullPolicy: IfNotPresent
command: ["python"]
args: ["-m", "http.server", "8000" ]
ports:
- name: http
containerPort: 8000
preDeleteUpdateStrategy:
hook:
templateName: test
updateStrategy:
type: InplaceUpdate
partition: 1
maxUnavailable: 2
canary:
steps:
- partition: 3
- pause: {}
- partition: 1
- pause: {duration: 60}
- hook:
templateName: test
- pause: {}
inPlaceUpdateStrategy:
gracePeriodSeconds: 30
以上是一个示例的 GameDeployment yaml 配置,与 Deployment 的配置差别不大,大部分继承 Deployment 的参数含义。我们将逐个介绍不同或新增之处:
- updateStrategy/type 更新类型,支持 RollingUpdate(滚动更新),InplaceUpdate(原地升级),HotPatchUpdate(镜像热更新)三种更新策略。RollingUpdate 与 Deployment 的定义相同,下文我们将单独介绍 InplaceUpdate 和 HotPatchUpdate。
- updateStrategy/partition 相比 Deployment 新增的参数,用于实现灰度发布,含义同 StatefulSet 的 partition。
- updateStrategy/maxUnavailable 指在更新过程中每批执行更新的实例数量,在更新过程中这批实例是不可用的。比如一共有 8 个实例,maxUnavailable 设置为 2 ,那么每批滚动或原地重启 2 个实例,等这 2 个实例更新完成后,再进行下一批更新。可设置为整数值或百分比,默认值为 25% 。
- updateStrategy/maxSurge 在滚动更新过程中,如果每批都是先删除 maxUnavailable 数量的旧版本 pod 数,再新建新版本的 pod 数,那么在整个更新过程中,总共只有 replicas - maxUnavailable 数量的实例数能够提供服务。在总实例数较小的情况下,会影响应用的服务能力。设置 maxSurge 后,会在滚动更新前先多创建 maxSurge 数量的 pod,然后再逐批进行更新,所有实例更新完后再删掉 maxSurge 数量的 pod ,这样就能保证整个更新过程中可服务的总实例数量。 maxSurge 默认值为 0 。 因 InplaceUpdate 和 HotPatchUpdate 不会重启 pod ,因此建议在这两种更新策略的情况下无需设置 maxSurge 参数,只在 RollingUpdate 更新时设置。
- updateStrategy/inPlaceUpdateStrategy 原地升级时的 gracePeriodSeconds 时间,详见下文“InplaceUpdate 原地升级”的介绍。
- updateStrategy/canary 定义分批灰度发布的步骤,详见下文“自动化分步骤灰度发布”。
- preDeleteUpdateStrategy 删除或更新前 pod 前的 hook 策略,实现优雅地退出 pod。详见下文“PreDeleteHook:优雅地删除和更新 Pod”。
GameStatefulSet
Kubernetes 原生的 StatefulSet 是面向有状态应用的工作负载,每个应用实例都有一个单独的网络和存储编号,实例在更新和缩容时是有序进行的。StatefulSet 为了面对上文描述的一些更为复杂的有状态应用的需求,我们在原生的 StatefulSet 的基础上,开发实现了增强版本: GameStatefulSet。 相比 StatefulSet, GameStatefulSet 主要包含以下新增特性:
- 支持 pod 原地升级
- 支持 pod 容器镜像热更新
- 支持并行更新,以提升更新(包括滚动更新、原地升级和镜像热更新)速度
- 支持智能式分步骤灰度发布,可在灰度发布步骤中加入 hook 校验
- 支持删除或更新 pod 前的 hook 校验,以实现优雅的 pod 退出
- 支持原地重启前的镜像预拉取,以加快原地重启的速度
apiVersion: tkex.tencent.com/v1alpha1
kind: GameStatefulSet
metadata:
name: test-gamestatefulset
spec:
serviceName: "test"
podManagementPolicy: Parallel
replicas: 5
selector:
matchLabels:
app: test
preDeleteUpdateStrategy:
hook:
templateName: test
updateStrategy:
type: InplaceUpdate
rollingUpdate:
partition: 1
inPlaceUpdateStrategy:
gracePeriodSeconds: 30
canary:
steps:
- partition: 3
- pause: {}
- partition: 1
- pause: {duration: 60}
- hook:
templateName: test
- pause: {}
template:
metadata:
labels:
app: test
spec:
containers:
- name: python
image: python:latest
imagePullPolicy: IfNotPresent
command: ["python"]
args: ["-m", "http.server", "8000" ]
ports:
- name: http
containerPort: 8000
以上是一个 GameStatefulSet 的 yaml 示例,相关参数介绍如下:
- podManagementPolicy 支持 "OrderedReady" 和 "Parallel" 两种方式,定义和 StatefulSet 一致,默认为 OrderedReady。与 StatefulSet 不同的是,如果配置为 Parallel, 那么不仅实例扩缩容是并行的,实例更新也是并行的,即自动并行更新。
- updateStrategy/type 支持 RollingUpdate, OnDelete, InplaceUpdate, HotPatchUpdate 四种更新方式,相比原生 StatefulSet,新增 InplaceUpdate, HotPatchUpdate 两种更新模式。
- updateStrategy/rollingUpdate/partition 控制灰度发布的数量,与 StatefulSet 含义一致。为了兼容,InplaceUpdate 和 HotPatchUpdate 的灰度发布数量也由这个参数配置。
- updateStrategy/inPlaceUpdateStrategy 原地升级时的 gracePeriodSeconds 时间,详见下文“InplaceUpdate 原地升级”的介绍。
- updateStrategy/canary 定义分批灰度发布的步骤,详见下文“智能式分步骤灰度发布”。
- preDeleteUpdateStrategy 删除或更新前 pod 前的 hook 策略,实现优雅地退出 pod。详见下文“PreDeleteHook:优雅地删除和更新 Pod”。
功能特性与场景覆盖
原地升级 InplaceUpdate
GameDeployment 和 GameStatefulSet 都支持 InplaceUpdate 更新策略。 原地升级是指,在更新 pod 版本时,保持 pod 的生命周期不变,只重启 pod 中的一个或多个容器,因而在升级期间,pod 的共享内存 IPC 等能保持不丢失。使用原地升级的实例更新方式,有以下收益:
- pod 中有多个容器,容器之间通过共享内存通信。升级时期望保持 pod 生命周期,只更新其中部分容器,IPC 共享内存不丢失,更新完成后 pod 继续提供服务。
- 原生的滚动升级更新策略需要逐个或分批的删掉旧版本实例,再创建新版本实例,效率很低。使用原地升级的方式,不需要重建 pod 实例,能大为提升发布更新的速度。
Kubernetes 原生的 Deployment 和 StatefulSet 等工作负载都没有直接支持原地升级的更新方式,但 kubelet 组件隐藏地支持了这一能力。针对一个处于 running 状态的 Pod,我们只需要通过 patch 的方式更新 pod spec 中的 image 版本,kubelet 监控到了这一变化后,就会自动地杀掉对应的旧版本镜像的容器并拉起一个新版本镜像的容器,即实现了 Pod 的原地升级。 我们通过 ReadinessGate 和 inPlaceUpdateStrategy/gracePeriodSeconds 的结合,来实现原地升级当中的流量服务的平滑切换。
原地升级的更新策略下,可以配置 spec/updateStrategy/inPlaceUpdateStrategy/gracePeriodSeconds 参数,假设配置为 30 秒,那么 GameStatefulSet/GameDeployment 在原地更新一个 pod 前,会通过 ReadinessGate 先把这个 pod 设置为 unready 状态,30 秒过后才会真正去原地重启 pod 中的容器。这样,在这 30 秒的时间内因为 pod 变为 unready 状态,k8s 会把该 pod 实例从 service 的 endpoints 中剔除。等原地升级成功后,GameStatefulSet/GameDeployment 再把该 pod 设为 ready 状态,之后 k8s 才会重新把该 pod 实例加入到 service 的 endpoints 当中。 通过这样的逻辑,在整个原地升级过程中,能保证服务流量的无损。 gracePeriodSeconds 的默认值为 0 ,当为 0 时,GameStatefulSet/GameDeployment 会立刻原地升级 pod 中的容器,可能会导致服务流量的丢失。 InplaceUpdate 同样支持灰度发布 partition 配置,用于配置灰度发布的比例。
GameDeployment InplaceUpdate 使用示例 GameStatefulSet InplaceUpdate 使用示例
容器镜像热更新 HotPatchUpdate
原地升级更新策略虽然能保持 pod 的生命周期和 IPC 共享内存,但始终是要重启容器的。对于游戏对局类的 GameServer 容器,如有玩家正在进行对局服务,原地升级 GameServer 容器会中断玩家的服务。 有些业务为了实现不停服更新,使用了服务进程 reload 技术,reload 过程中新版本的进程接替旧版本的进程提供服务,内存数据不丢失,升级过程中玩家无感知。 为了满足这类业务的容器上云需求,我们调研了 docker 镜像 merge 的增量更新策略,修改 docker 源码增加了一个容器镜像热更新的接口。在对一个运行着的容器调用镜像热更新接口进行镜像版本的更新时,容器的生命周期不变,容器内的进程也保持不变,但容器的基础镜像会替换为新的版本。 通过对 docker 的这种改动,对一个运行状态的容器进行镜像热更新后,容器状态不变,但其基础镜像的版本及数据已实现了增量更新。假如容器中的进程实现了 reload 功能,而基础镜像中的 so 文件或配置都已更新为新版本,此时只需要往容器中的进程发送 reload 信号,就能完成服务进程的热更新,实现不停服升级。 为了在 Kubernetes 中实现容器镜像热更新的能力,我们修改了 kubelet 的代码,在 kubelet 原地升级能力的基础上,当 pod 中加了指定的 annotation 时,kubelet 对 pod 的更新就会从原地升级操作变为容器镜像热更新操作,调用 docker 的镜像热更新接口完成容器的镜像热更新。 关于在 docker 和 kubelet 上对容器镜像热更新的详细实现,我们后续将在另外的文章中详细阐述。
GameStatefulSet/GameDeployment 集成了容器镜像热更新的功能,当把 spec/updateStrategy/type 配置为 HotPatchUpdate 时,就会通过更新 pod 中的容器镜像版本并添加 annotation 的方式,联动 kubelet 和docker 完成容器镜像热更新的功能。在整个过程中,pod 及其容器的生命周期都是没有变化的,此后,用户可以通过向容器中进程发送信号的方式,完成业务进程的 reload,保证服务的不中断。 HotPatchUpdate 同样支持灰度发布 partition 配置,用于配置灰度发布的比例。
HotPatchUpdate 的更新策略需要结合我们定制化的 kubelet 和 docker 版本才能生效。 GameDeployment HotPatchUpdate 使用示例 GameStatefulSet HotPatchUpdate 使用示例
基于hook的应用交互式发布
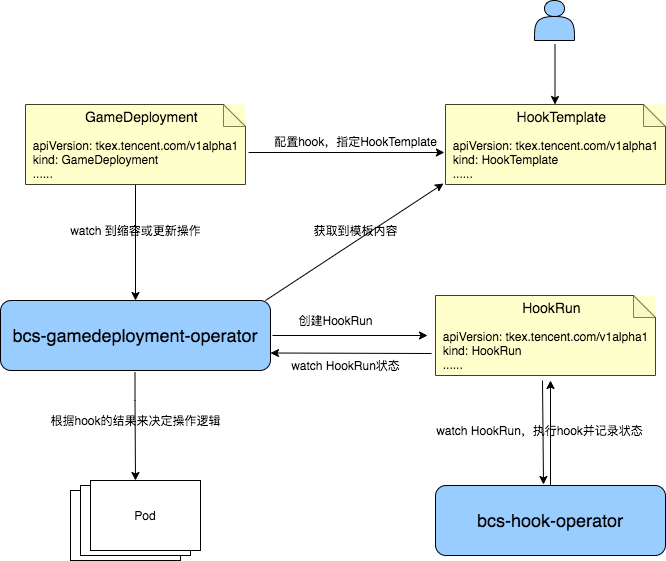
上文中我们提到,多数复杂类应用在发布更新过程中有许多外部依赖或应用本身的数据指标依赖,如上面我们提到的:实例扩缩容或更新前需要进行数据搬迁;缩容一个实例前需要先完成路由变更;实例缩容或更新前需要等待游戏对局结束。此外,在灰度发布时,有时我们需要从 Prometheus 监控数据中查看指标是否符合预期,以决定是否继续灰度更多的实例。 这其实可以看作为应用发布过程中的各种 hook 勾子,通过 hook 的结果来判断是否可以继续下一步的发布流程。无论是面向无状态应用的 GameDeployment 还是面向有状态应用的 GameStatefulSet,都有这种发布需求。 我们在深刻挖掘业务需求和调研解决方案后,在 Kubernetes 层面抽象出了一个通用的 operator: bcs-hook-operator。 bcs-hook-operator 主要职责是根据 hook 模板执行 hook 操作并记录 hook 的状态,GameDeployment 或 GameStatefulSet watch hook 的最终状态,根据 hook 结果来决定下一步执行何种操作。
bcs-hook-operator 定义了两种 CRD:
apiVersion: tkex.tencent.com/v1alpha1
kind: HookTemplate
metadata:
name: test
spec:
args:
- name: service-name
value: test-gamedeployment-svc.default.svc.cluster.local
- name: PodName
metrics:
- name: webtest
count: 2
interval: 60s
failureLimit: 0
successCondition: "asInt(result) < 30"
provider:
web:
url: http://1.1.1.1:9091
jsonPath: "{$.age}"
HookTemplate 用来定义一个 hook 的模板。在一个 HookTemplate 中可以定义多个 metric,每个 metric 都是需要执行的一个 hook。在 metric 中可以定义 hook 的次数、两次之间的间隔、成功的条件、provider等等多个参数。provider 定义的是 hook 的类型,目前支持两种类型的 hook:webhook 和 prometheus。
apiVersion: tkex.tencent.com/v1alpha1
kind: HookRun
metadata:
name: test-gamedeployment-67864c6f65-4-test
namespace: default
spec:
metrics:
- name: webtest
provider:
web:
jsonPath: '{$.age}'
url: http://1.1.1.1:9091
successCondition: asInt(result) < 30
terminate: true
status:
metricResults:
- count: 1
failed: 1
measurements:
- finishedAt: "2020-11-09T10:08:49Z"
phase: Failed
startedAt: "2020-11-09T10:08:49Z"
value: "32"
name: webtest
phase: Failed
phase: Failed
startedAt: "2020-11-09T10:08:49Z"
HookRun 是根据模板 HookTemplate 创建的一个实际运行的 hook CRD,bcs-hook-operator 监测并控制 HookRun 的运行状态和生命周期,根据其 metrics 中的定义来执行 hook 操作,并实时记录 hook 调用的结果。 关于 bcs-hook-operator 的更详细介绍可参考:bcs-hook-operator
GameDeployment/GameStatefulSet 与 bcs-hook-operator 在应用发布过程中使用 hook 时的交互架构图: ![bcs-hook-operator.png]()
自动化分步骤灰度发布
GameDeployment & GameStatefulSet 支持智能化的分步骤分批灰度发布功能,允许用户配置灰度发布的自动化步骤,通过配置多个灰度发布步骤,达到分批发布的目的,自动监测发布的效果,实现灰度发布的智能化控制。 当前,可以在灰度发布步骤中配置以下 4 种步骤:
- 灰度的实例个数,用 partition 来指定
- 永久暂停灰度,除非用户手动触发继续后续步骤
- 暂停指定的时间后再继续后续步骤
- Hook 调用,templateName 指定要使用的 HookTemplate,该 HookTemplate 必须已经在集群中创建。 GameDeployment&GameStatefulSet 会根据 HookTemplate 创建 HookRun,bcs-hook-operator 操纵并执行 HookRun。GameDeployment&GameStatefulSet watch HookRun 的状态,如果结果满足预期,则继续执行后续的灰度步骤,如果返回结果不满足预期,则暂停灰度发布,必须由人工介入来决定是继续后续灰度步骤还是进行回滚操作。 下面的示例中,定义了灰度发布的 6 个步骤:
...
spec:
...
updateStrategy:
type: InplaceUpdate
rollingUpdate:
partition: 1
inPlaceUpdateStrategy:
gracePeriodSeconds: 30
canary:
steps:
- partition: 3 # 该批灰度发布的个数
- pause: {} # 暂停发布
- partition: 1 # 该批灰度发布的个数
- pause: {duration: 60} # 暂停60秒后再继续发布
- hook: # 定义 hook 步骤
templateName: test # 使用名为test的HookTemplate
- pause: {} # 暂停发布
...
在 GameDeployment 和 GameStatefulSet 上进行智能式分步骤灰度发布的配置和使用方式基本一致,详细使用教程可参考:智能式分步骤灰度发布教程
PreDeleteHook:优雅地删除和更新 Pod
在上文 “基于hook的应用交互式发布” 章节我们提到,应用在发布更新过程中有许多外部依赖或应用本身的数据指标依赖。特别是在缩容实例或升级实例版本时,需要删掉旧版本的实例,但往往实例上仍然有服务不能中断,如有玩家在进行游戏对战。此时,实例的缩容或更新是有依赖的,不能马上进行缩容或更新,需要查询条件,当条件满足后再进行缩容或更新。 我们根据 bcs-hook-operator 的抽象,在 GameDeployment 和 GameStatefulSet 上开发了 PreDeleteHook 的功能,实现优雅地删除和更新应用 Pod 实例。
apiVersion: tkex.tencent.com/v1alpha1
...
spec:
preDeleteUpdateStrategy:
hook:
templateName: test # 使用的HookTemplate
updateStrategy:
...
inPlaceUpdateStrategy:
gracePeriodSeconds: 30
在 GameDeployment/GameStatefulSet 的 spec/preDeleteUpdateStrategy 中指定 HookTemplate,那么当缩容或更新 Pod 实例时,针对每一个待删除或更新的 Pod,GameDeployment/GameStatefulSet 都会根据 HookTemplate 模板创建一个 HookRun,然后 watch 这个 HookRun 的状态。bcs-hook-operator 控制 HookRun 的运行并实时记录其状态。当 HookRun 运行完成后,GameDeployment/GameStatefulSet watch 到其最终状态,依据其最终状态来决定是否能正常删除或更新 Pod。
更进一步地,我们在 HookTemplate 和 HookRun 中支持了一些常见参数的自动渲染,如 PodName, PodNamespace, PodIP 等。 例如,假设 PreDeleteHook 中需要运行的 hook 是应用实例本身的一个 http 接口,暴露在容器的 8080 端口,那么我们可以定义这样一个 HookTemplate:
apiVersion: tkex.tencent.com/v1alpha1
kind: HookTemplate
metadata:
name: test
spec:
args:
- name: PodIP
metrics:
- name: webtest
count: 3
interval: 60s
failureLimit: 2
successCondition: "asInt(result) > 30"
provider:
web:
url: http://{{ args.PodIP }}:8080
jsonPath: "{$.age}"
这样,GameDeployment/GameStatefulSet 在针对待删除或更新的 Pod 创建 HookRun 时,会把 Pod IP 渲染进 webhook url 中,最终创建和执行的是对应用 Pod 本身提供的 http 接口的 webhook 调用。
在 GameDeployment 和 GameStatefulSet 上进行 PreDeleteHook 的配置和使用方式基本一致,详细使用教程可参考:PreDeleteHook:优雅地删除和更新 Pod
镜像预热
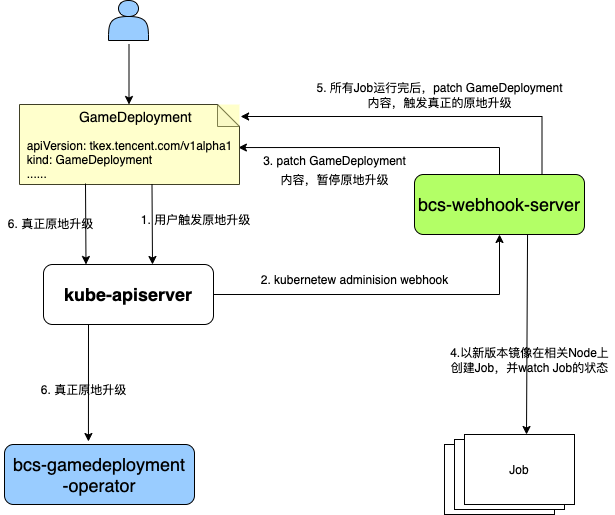
使用 Pod 原地升级是为了最大程度上提升发布的效率,并减少服务中断的时间。但一个 Pod 的原地升级过程中,最大的时间消耗在于拉取新版本镜像的时间,特别是当镜像很大的时候。 因此,业务在使用原地升级的过程中,向我们反馈的最多的问题就是原地升级的速度仍然过慢,与理想中的速度有差距。 基于此,我们与欢乐游戏工作室的公共支持团队合作共建了 GameStatefulSet&GameDeployment 的原地升级镜像预热方案。 以 GameDeployment 为例,镜像预热方案的流程架构如下图所示: ![闀滃儚棰勭儹.png]()
- 1 . 用户触发 GameDeployment 原地升级。
- 2 . kube-apiserver 通过 admission webhook 拦截到请求,交由 bcs-webhook-server 处理。
- 3 . bcs-webhook-server 判断为用户触发原地升级,修改 GameDeployment 的内容,把镜像版本 patch 为原来版本,并在 annotations 中增加一个新版本镜像的 patch。
- 4 . bcs-webhook-server 使用新版本的镜像在所有运行有这个应用实例的节点上创建一个 Job,并 watch 这些 Job 的状态。Job 运行时就会拉取新版本的镜像。
- 5 . bcs-webhook-server 监测到所有 Job 运行结果后,修改 GameDeployment 的内容,把 annotations 中的新版本镜像的 patch 删除,并把镜像版本 patch 为新版本的镜像,触发真正的原地升级。然后,清除掉运行完成的 Job。
- 6 . bcs-gamedeployment-operator watch 到真正的原地升级后,执行原地升级的更新策略。
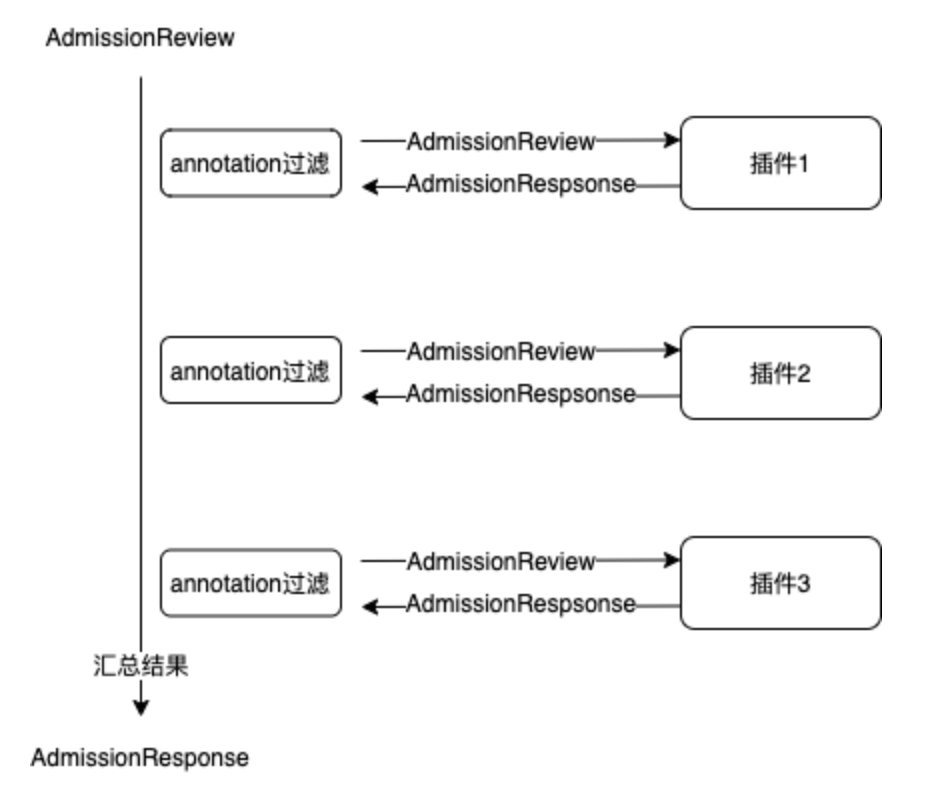
使用这个方案,能保证 Kubernetes 工作负载 GameDeployment&GameStatefulSet 与镜像预热方案的解耦,假设要支持更多的 Kubernetes 工作负载的镜像预热,只需要在 bcs-webhook-server 上添加对这个工作负载 CRD 的支持即可。 基于此,我们重构开发了 bcs-webhook-server,支持以插件化的方式添加 webhook: ![bcs-webhook-server.png]()
镜像预热方案及 bcs-webhook-server 的更多实现细节,请参考:bcs-webhook-server
总结
BCS 团队在基于 TKE 构建云原生上云平台的过程中,与不同业务团队进行探讨,挖掘业务需求,抽象需求共性,并结合社区的开源方案,研发了 GameDeployment 和 GameStatefulSet 这两个 Kubernetes 工作负载。这两个工作负载及其特性虽然是为复杂的游戏业务上云而产生,但基本能覆盖大多数互联网业务的需求,更贴近各种业务的运维和发布场景。 后续,我们也将继续与各业务团队进行探讨和合作,抽象更多需求特性,不断迭代,持续增强 GameStatefulSet 和 GameDeployment 的能力。 蓝鲸容器服务 BCS 已经开源,更多容器上云方案和细节请参考我们的开源项目:BK-BCS
感谢以下协作开发者 Committer
【腾讯云原生】云说新品、云研新术、云游新活、云赏资讯,扫码关注同名公众号,及时获取更多干货!! ![]()