网站首页
es/mysql/mongodb/redis区别
关系型数据库: MySQL
关系型数据库是一种基于关系的数据库,而关系模型可通过二维表来进行表示,所以数据的存储方式是由行列组成的表,每一列是一个字段,每一行是一个记录。在关系型数据库中通常包含了三个概念:数据库(database)、表(table)、记录(record)。在大部分关系型数据库中,都是适用B+树作为索引,比如MySQL。
非关系型数据库:MongoDB、Redis
MongoDB介绍
MongoDB是由c++语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储类似JSON对象,它的字段可以包含其他的文档、数组以及文档数组。MongoDB包含了三个层次概念:数据库(database)、集合(collection)、文档(document)。MongoDB的数据索引是B-树。
MongoDB 在创建数据库的时候,会直接在磁盘上面分配一组数据文件,所有的集合、索引和数据库的其他元数据都保存在这些文件中。
在使用MongoDB中,操作系统会通过mmap将进程所需要的所有数据都映射到虚拟内存中,然后在将当前需要处理的数据映射到内存中。当需要访问的数据不在虚拟内存的时候,会触发page fault,然后os就会硬盘中的数据加载到虚拟内存和内存中。而当内存已满时,会触发swap-out操作,将一些数据写回硬盘。所以有了这种内存映射文件的方法,就会有种好像所有需要访问的数据都在内存里一样。
MongoDB的特点:
提供面向文档存储,操作简单
扩展性强,第三方支持丰富
具有failover机制(失效转移:一种备份操作模式,当一个系统因为一些故障无法完成工作的时候,另一个系统自动接替已失效系统的工作继续执行)
支持大容量存储,内置GridFS(可用于存放大量的小文件)
在高负载的情况下,可以添加更多的节点,保证服务器性能
缺点
适用场景
Redis
Redis是一种内存数据库,所有的数据都是放在内存之中,定期写入磁盘中,当内存不够的时候,可选择指定的LRU算法删除数据。Redis是基于哈希字典建立的,因此其索引方式是哈希。
elasticsearch
1、Elasticsearch和MongoDB/Redis/Memcache一样,是非关系型数据库。是一个接近实时的搜索平台,从索引这个文档到这个文档能够被搜索到只有一个轻微的延迟,企业应用定位:采用Restful API标准的可扩展和高可用的实时数据分析的全文搜索工具。
2、可拓展:支持一主多从且扩容简易,只要cluster.name一致且在同一个网络中就能自动加入当前集群;本身就是开源软件,也支持很多开源的第三方插件。
3、高可用:在一个集群的多个节点中进行分布式存储,索引支持shards和复制,即使部分节点down掉,也能自动进行数据恢复和主从切换。
3、采用RestfulAPI标准:通过http接口使用JSON格式进行操作数据。
4、数据存储的最小单位是文档,本质上是一个JSON 文本;
实际项目开发中,几乎每个系统都会有一个搜索的功能,数据量少时可以直接从主数据库中比如Mysql搜索,但当搜索做到一定程度时,比如系统数据量上了10亿、100亿条的时候,传统的关系型数据库的I/O性能和统计分析性能就难以满足用户需要了。所以很多公司都会把搜索单独做成一个独立的模块,用ElasticSearch等来实现。虽然内存缓存数据库的读写性能很高,但完全把数据放在内存中是不太现实的
需求:使用es做站内搜索
![]()
核心:怎么将mongodb中的数据添加到elasticsearch中,同步哪一些数据?
比如:搜索游记中title和summary中含有广州字样的游记,作为以广州为条件搜索的结果,首先要到mongodb中去把满足条件的数据找到显示出来。
从mongodb中同步条件列数据以及主键id到es中(推荐:因为内存资源宝贵,选择牺牲性能)
先匹配es中条件列搜索满足条件的数据,得到主键id集合,然后以id集合作为条件去mongodb中对应的id数据集合,之后再页面显示;
优点:节省内存空间(数据量小了);
缺点:稍微有损性能(去两个数据库中查询了);
从mongodb中同步页面需要的所有数据(包括条件列数据)以及主键id,把数据都放到es中存起来
先匹配es中条件列搜索满足条件的数据,得到数据集合,直接在页面显示;
优点:查询快(所有的数据都在es中了);
缺点:内存空间消耗大(数据量大了);
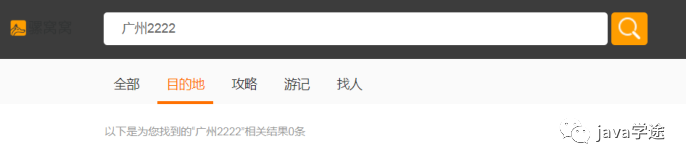
关键字搜索
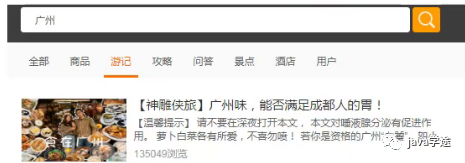
进入首页后,输入关键字, 选择不同搜索维度(默认是全部), 进入搜索页面
![]()
关键字搜索, 也称之站内搜索, 系统暂时仅对攻略, 游记, 目的地, 用户进行关键字查询, 当然也支持全部查询。
1:关键词搜索
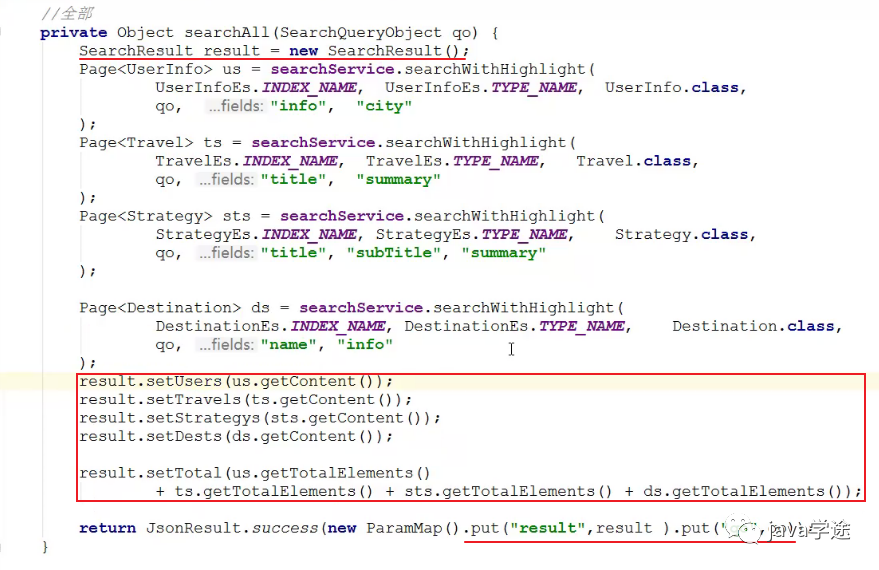
全部搜索, 会对目的地, 攻略, 游记, 用户对象(关键字段)进行全文搜索
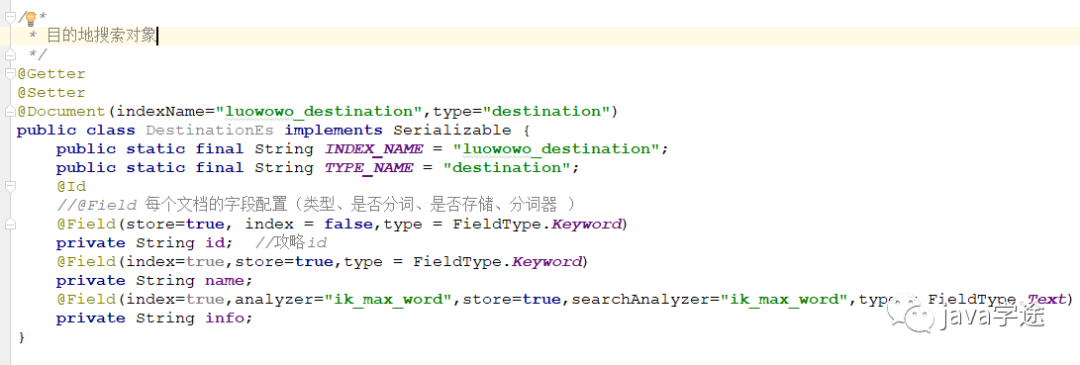
目的地:名称(name), 简介(info)
攻略:标题(title), 副标题(subTitle), 概要(summary)
游记:标题(title), 概要(summary)
用户:简介(info), 城市(city)
查询到的关键词进行高亮显示
添加依赖:
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> <dependency> <groupId>commons-beanutils</groupId> <artifactId>commons-beanutils</artifactId> <version>1.9.3</version> </dependency>
es的配置:
![]()
es中数据的初始化
目的地:
search.domain
![]()
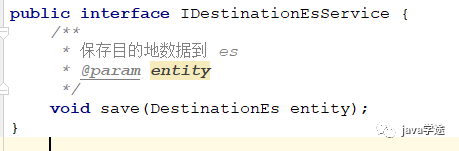
search.repository
![]()
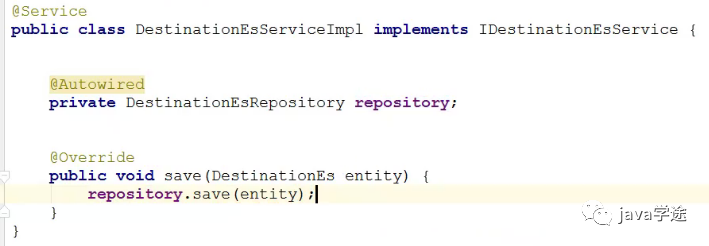
search.service
![]()
![]()
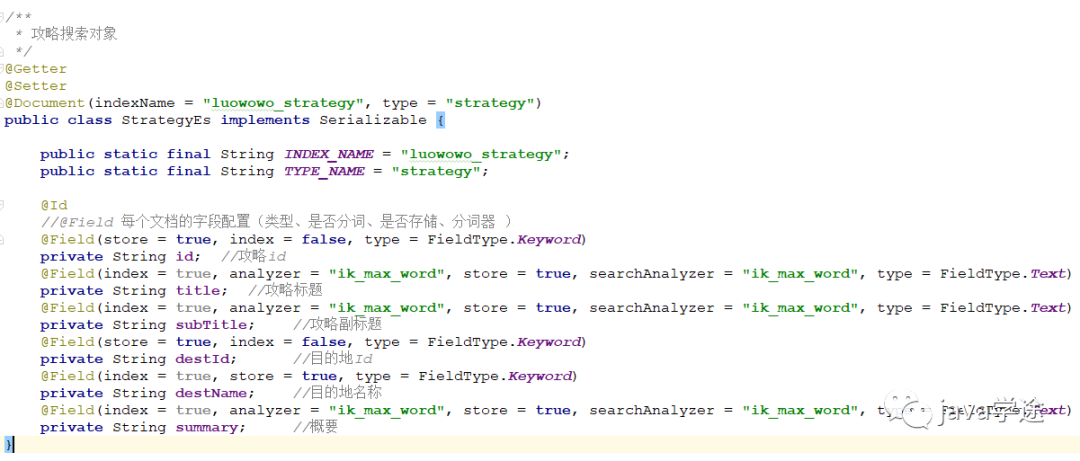
攻略:
![]()
其他组件是一样的,拷贝替换就好;
游记:
![]()
其他组件是一样的,拷贝替换就好;
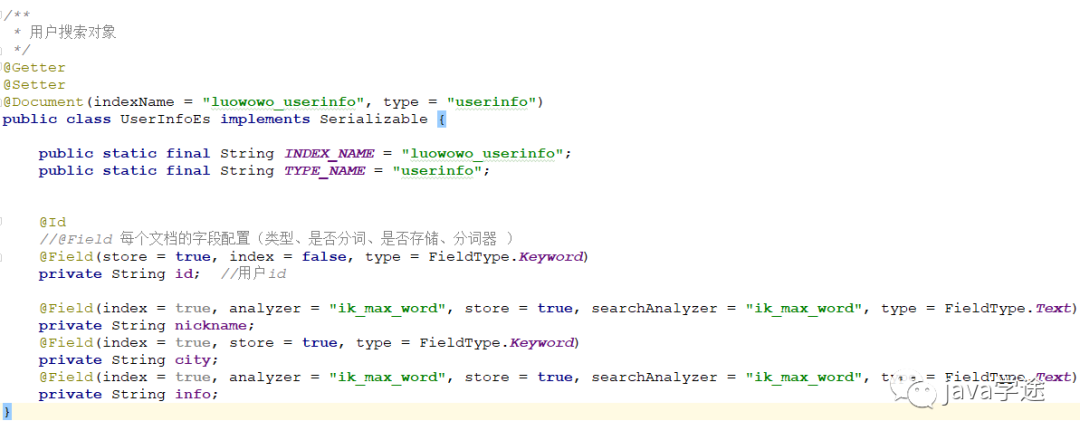
用户:
![]()
其他组件是一样的,拷贝替换就好;
初始化controller
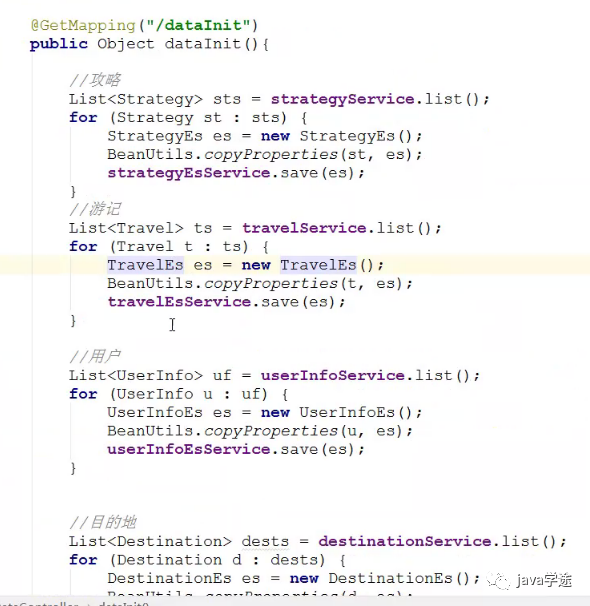
@RestController public class DataController { @Autowired private IDestinationEsService destinationEsService; @Autowired private IStrategyEsService strategyEsService; @Autowired private ITravelEsService travelEsService; @Autowired private IUserInfoEsService userInfoEsService; @Autowired private IDestinationService destinationService; @Autowired private IStrategyService strategyService; @Autowired private ITravelService travelService; @Autowired private IUserInfoService userInfoService; @GetMapping("/dataInit") public Object dataInit() { List<Strategy> sts = strategyService.list(); for (Strategy st : sts) { StrategyEs es = new StrategyEs(); BeanUtils.copyProperties(st, es); strategyEsService.save(es); } List<Travel> ts = travelService.list(); for (Travel t : ts) { TravelEs es = new TravelEs(); BeanUtils.copyProperties(t, es); travelEsService.save(es); } List<UserInfo> uf = userInfoService.list(); for (UserInfo u : uf) { UserInfoEs es = new UserInfoEs(); BeanUtils.copyProperties(u, es); userInfoEsService.save(es); } List<Destination> dests = destinationService.list(); for (Destination d : dests) { DestinationEs es = new DestinationEs(); BeanUtils.copyProperties(d, es); destinationEsService.save(es); } return "ok"; } }
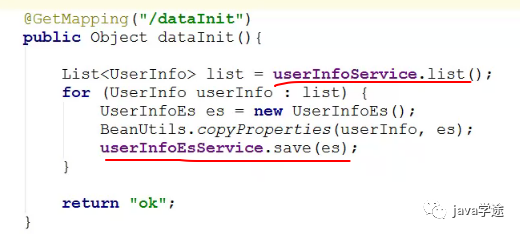
查到数据放到es中:
![]()
![]()
![]()
同理可得,剩下的拷贝。
![]()
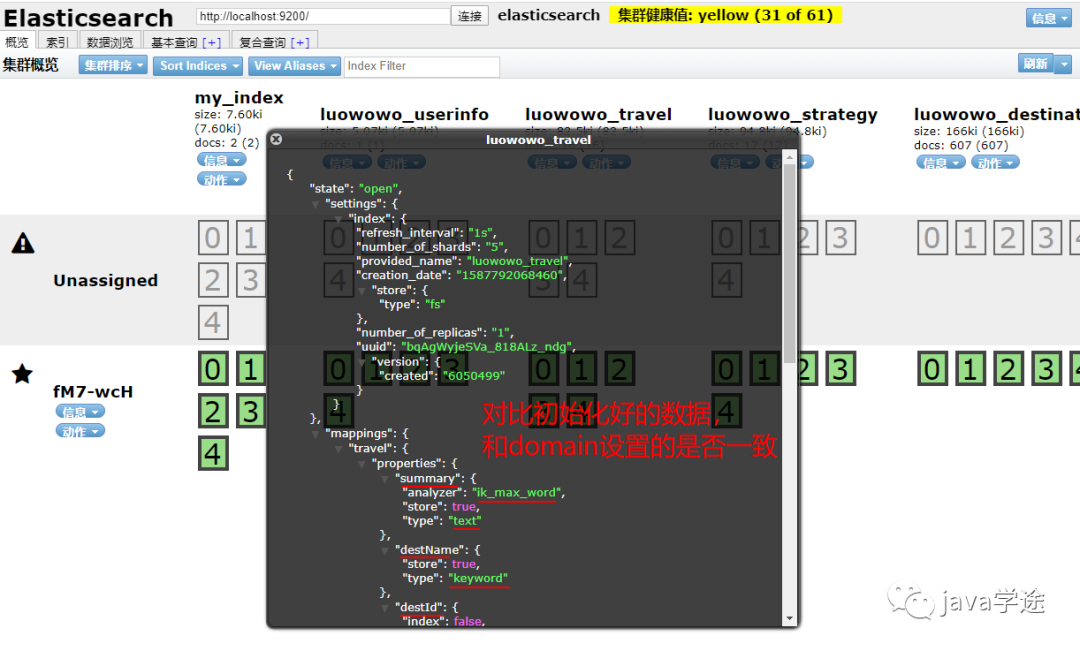
启动服务器:检查head中的数据是否按要求创建好了索引了:
![]()
索引信息一定要和配置的一致;
打开mongodb数据库:必须要保证所有的数据是合法合规的,把自己加的错误的坏的数据删了。
之后再进行数据的初始化:发出初始化数据的请求,刚刚设置的controller
![]()
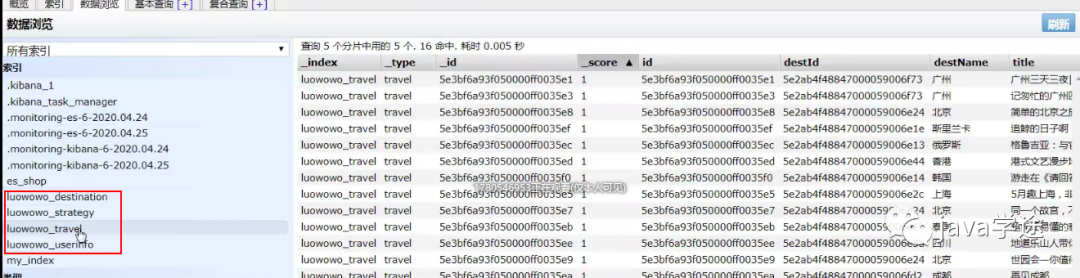
查看初始化完成的数据是否正确:
![]()
关键字搜索
注意:目的地是精确搜索,无高亮显示,找不到就找不到;其他的是全文搜索,关键字高亮显示;
目的地关键词搜索
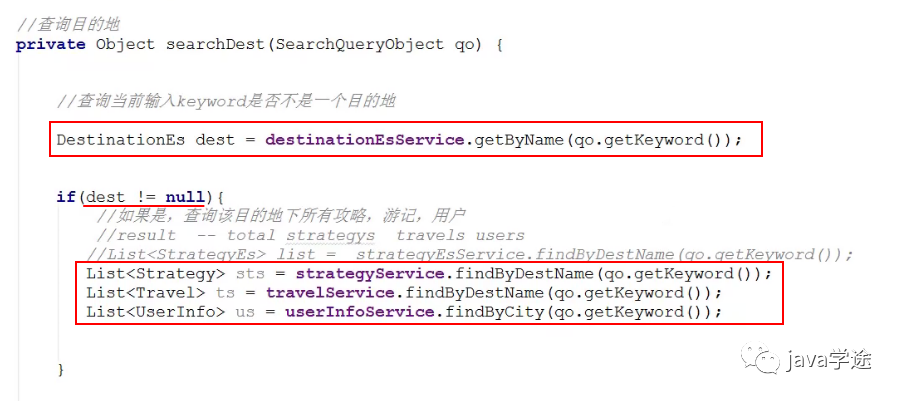
目的查询:输入关键词是精确查询输入的地区, 如果找到, 显示该目的地下所有攻略, 游记, 用户
![]()
如果目的找不到, 显示:
![]()
前端代码:
查看首页前台代码引用了rip-website\js\vue\common.js:
![]()
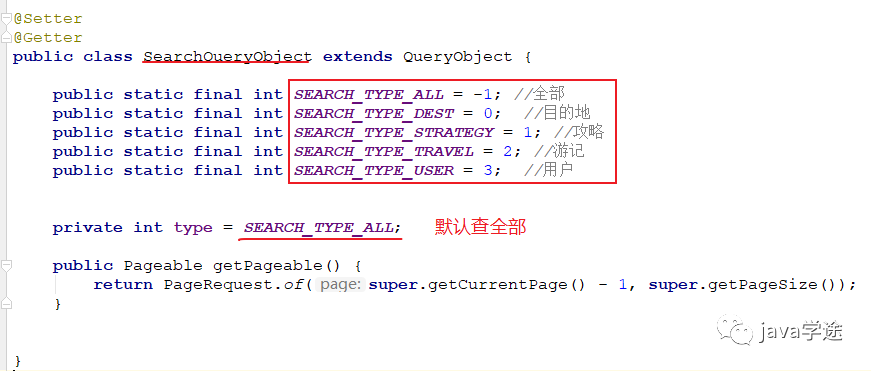
高查条件的封装,后面要用于分页,根据前台以int类型来区分集中不同的搜索目标来设计qo:
![]()
所有的搜索请求都是同一个映射地址:
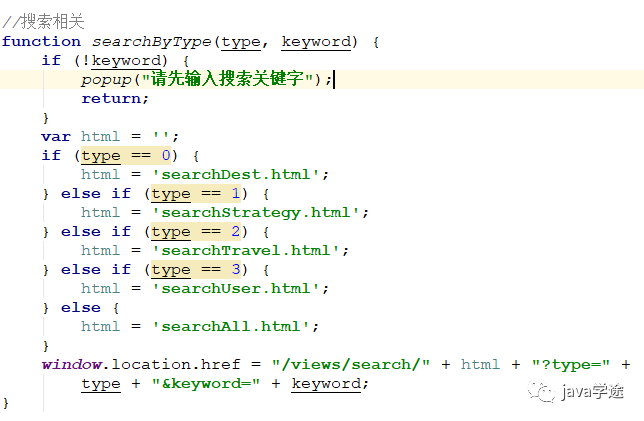
一个方法中完成不同的搜索目的,如何区分?
![]()
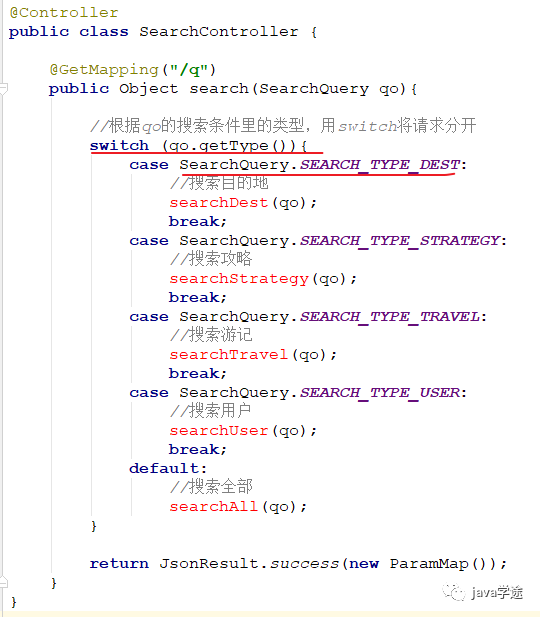
怎么将这些不同的搜索类型区分开:用switch语句
![]()
这样处理还有一个问题:不同的搜索目标类型,请求的返回数据是不一样的;
如何处理:由分支的方法自己来处理;
![]()
![]()
目的地关键词搜索:
system/search/searchDest.js
![]()
页面html:
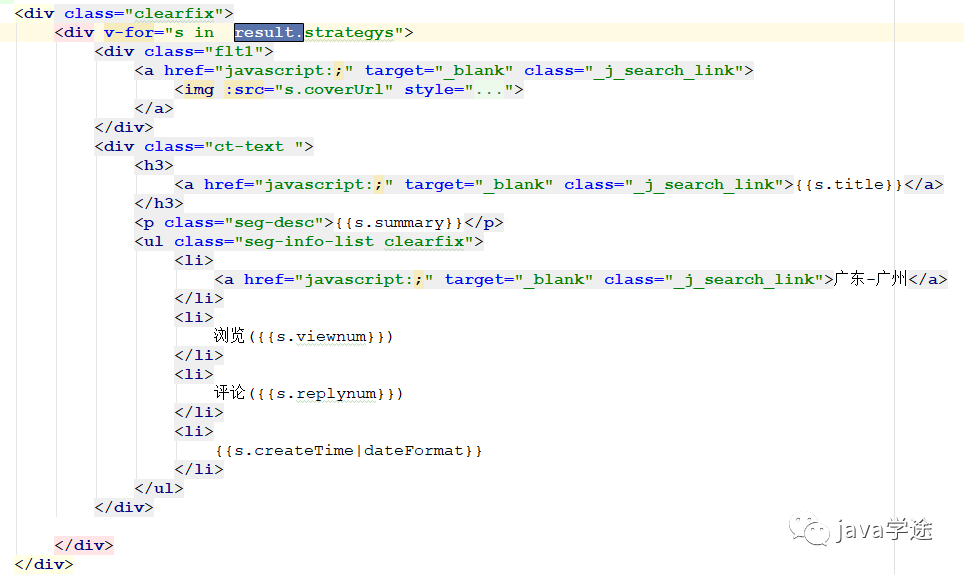
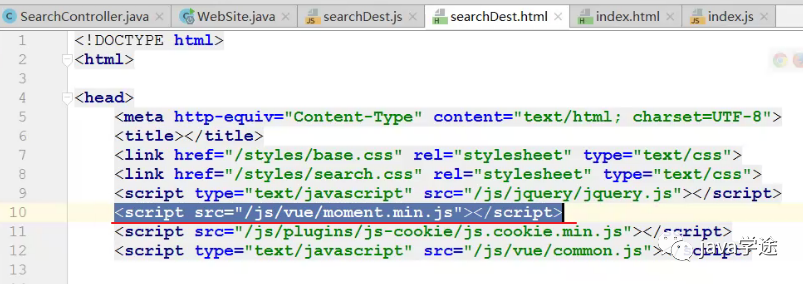
trip-website\views\search\searchDest.html
![]()
![]()
![]()
![]()
![]()
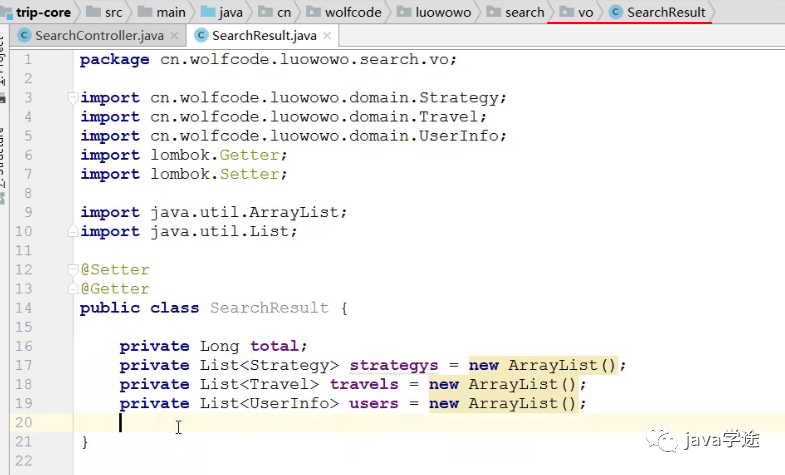
显然result是键值对的存在,使用map还是用对象(类似vo)封装,选择第二种;
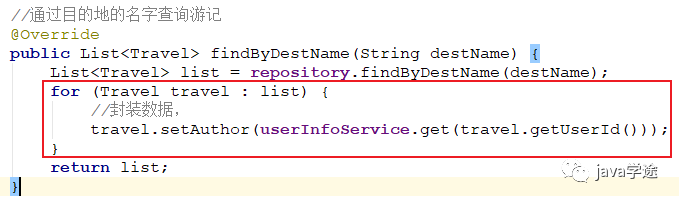
后台:
![]()
![]()
![]()
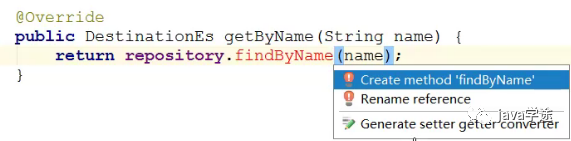
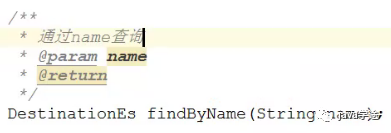
JPA中定义的方法ByXxx()要去检查一下es中是否有Xxx属性,否则报错:
![]()
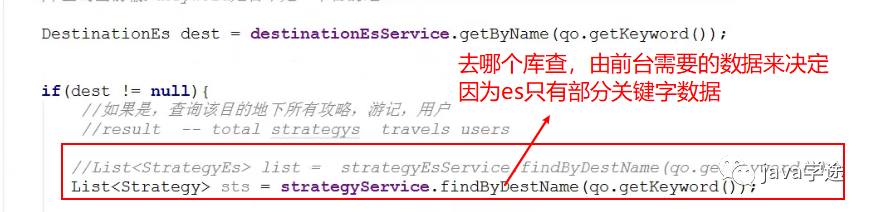
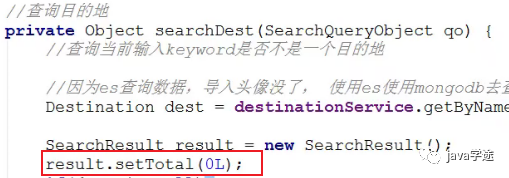
去哪一个数据库查询数据给前台?由前台需要显示的数据来决定。es能不能满足页面所有的显示的数据。
![]()
![]()
![]()
其他的三个查询方式相同;
![]()
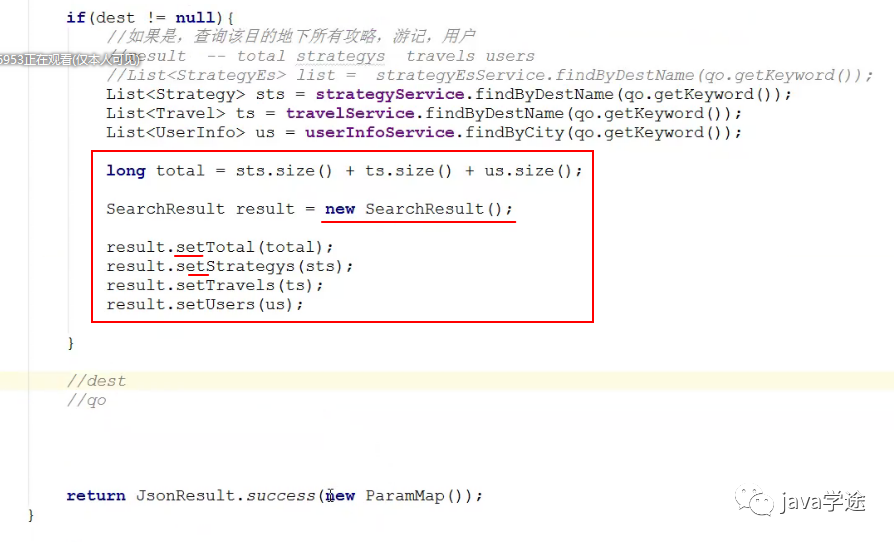
定义封装result数据的类型:
![]()
用result封装数据:
![]()
返回结果
![]()
测试查看查询的数据:
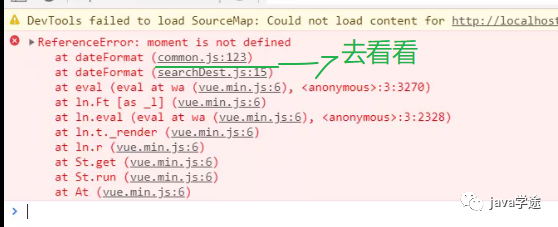
查不到数据:
![]()
get请求的时候:会将中文字符进行编码了,
![]()
后台需要解码,才能转换成中文:
![]()
再测试:
![]()
![]()
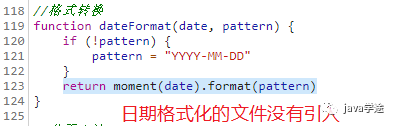
看页面少了引用:
![]()
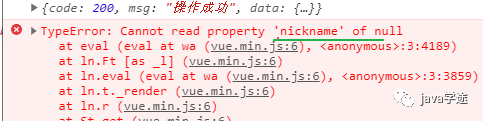
报错:找不到用户昵称,查看数据有没有到后天,查看前台有没有按要求封装数据;
![]()
![]()
头像没了:打印后台传过来的数据,发现没有头像信息;
![]()
![]()
![]()
测试,0条的0没有显示:或者在SearchResultVO中设置total默认值为0;
![]()
攻略全文搜索:
仅仅对攻略进行全文搜索
攻略:标题(title), 副标题(subTitle), 概要(summary)
![]()
拷贝接口:
![]()
拷贝实现类:
修改BeanUtils
![]()
![]()
![]()
为什么这么写:因为查询高亮的接口的定义,对比如下:
![]()
测试:
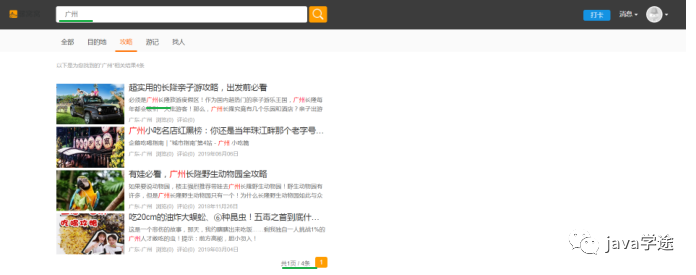
查看攻略查询结果正不正常,有没有高亮显示关键字;
攻略
![]()
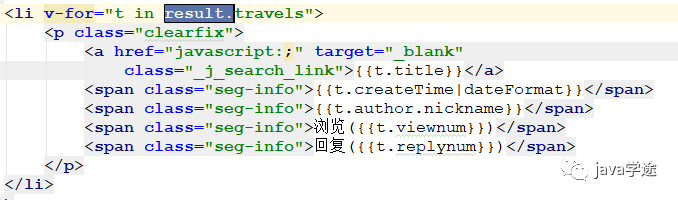
游记
![]()
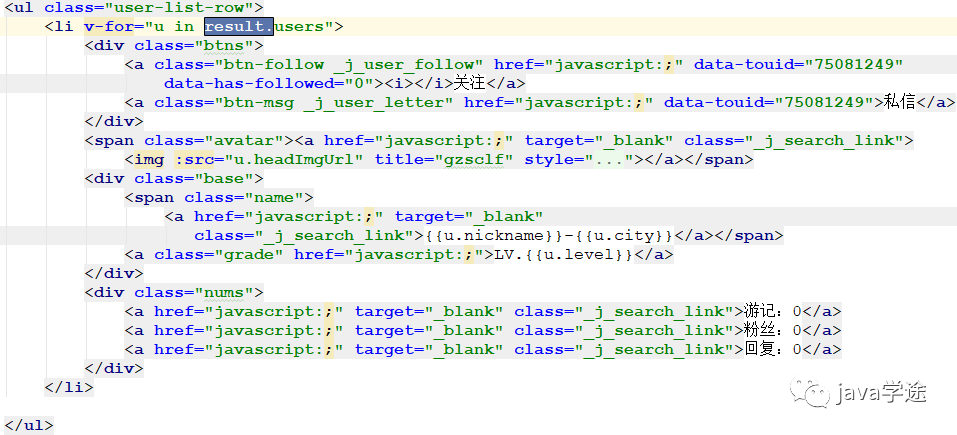
用户
![]()
全部
默认情况下查询全部显示:
![]()
数据的封装:
![]()
测试:
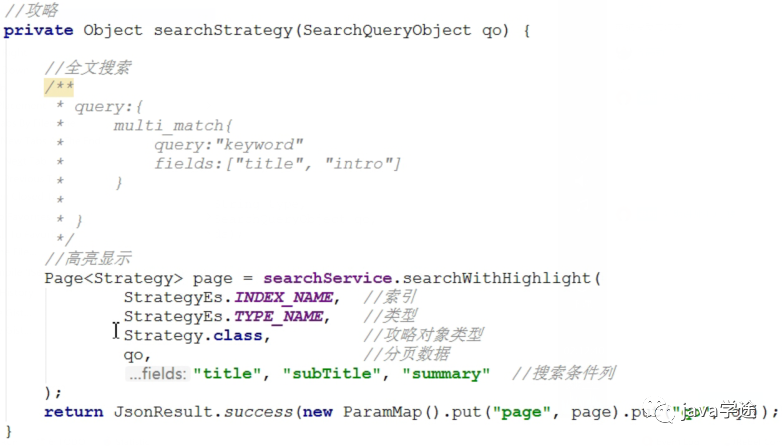
全文搜索方法设计的解释:
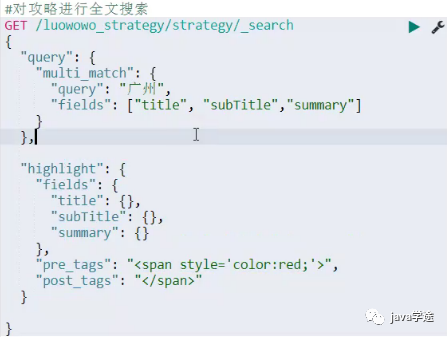
EQL语句全文检索:
![]()
![]()
方法设计:
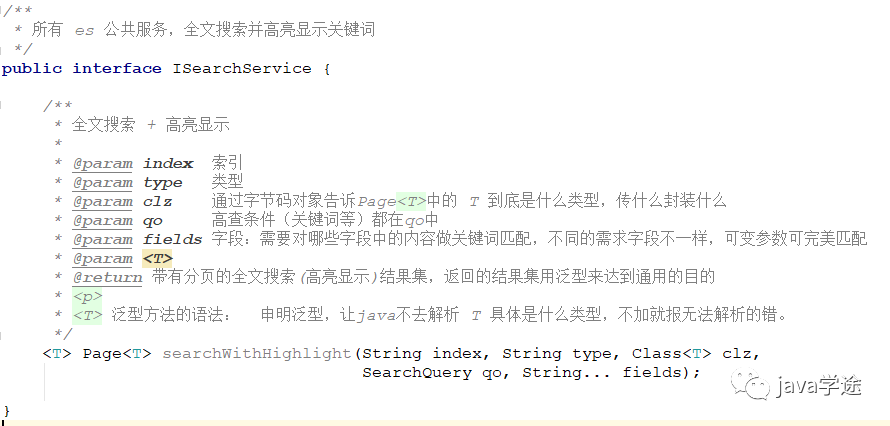
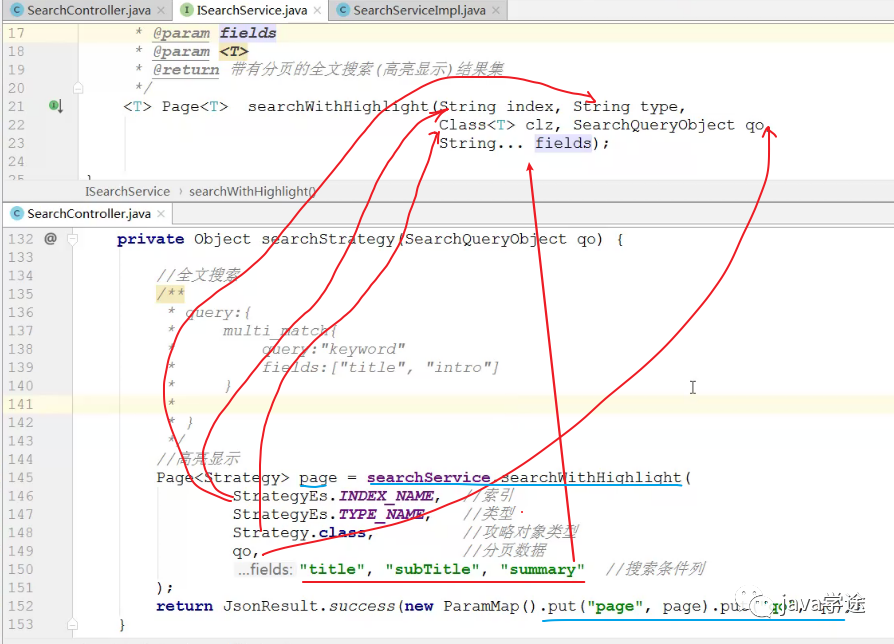
根据上面的语句如何设计全文搜索的方法:这个方法中有重复的操作,怎么保证通用性呢?————使用泛型设计方法,方法的可变参数
public interface ISearchService { <T> Page<T> searchWithHighlight(String index, String type, Class<T> clz, SearchQueryObject qo, String... fields); }
方法中需要做什么:
![]()
EQL语句查询到的响应结果:
![]()
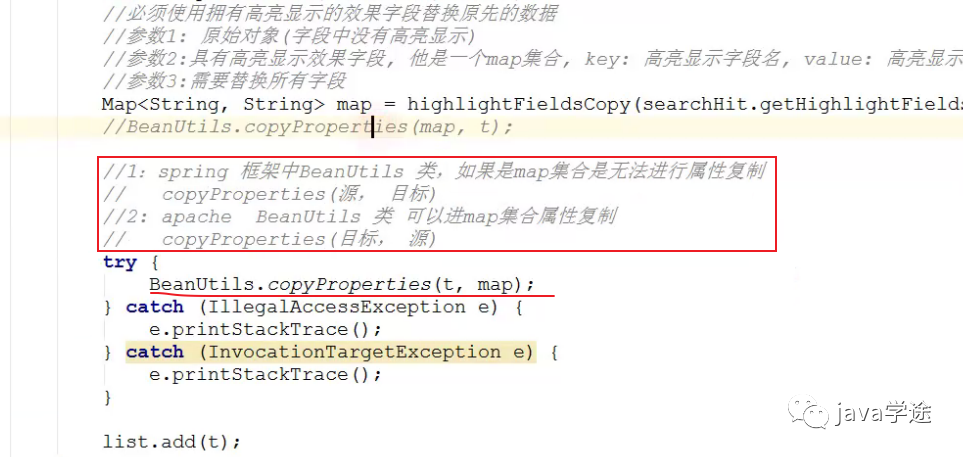
怎么把结果解析成前台认识的页面:
高亮解析:
![]()
![]()
代码:
@Service public class SearchServiceImpl implements ISearchService { @Autowired private IUserInfoService userInfoService; @Autowired private IStrategyService strategyService; @Autowired private ITravelService travelService; @Autowired private IDestinationService destinationService; @Autowired private ElasticsearchTemplate template; @Override public <T> Page<T> searchWithHighlight(String index, String type, Class<T> clz, SearchQuery qo, String... fields) { String preTags = "<span style='color:red;'>"; String postTags = "</span>"; HighlightBuilder.Field[] fs = new HighlightBuilder.Field[fields.length]; for (int i = 0; i < fs.length; i++) { fs[i] = new HighlightBuilder.Field(fields[i]) .preTags(preTags) .postTags(postTags); } NativeSearchQueryBuilder searchQuery = new NativeSearchQueryBuilder(); searchQuery.withIndices(index) .withTypes(type); searchQuery.withQuery(QueryBuilders.multiMatchQuery(qo.getKeyword(), fields)); searchQuery.withPageable(qo.getPageable()); searchQuery.withHighlightFields(fs); return template.queryForPage(searchQuery.build(), clz, new SearchResultMapper() { @Override public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> clazz, Pageable pageable) { List<T> list = new ArrayList<>(); SearchHits hits = response.getHits(); SearchHit[] searchHits = hits.getHits(); for (SearchHit searchHit : searchHits) { T t = mapSearchHit(searchHit, clazz); Map<String, String> map = highlightFieldsCopy(searchHit.getHighlightFields(), fields); try { BeanUtils.copyProperties(t, map); } catch (IllegalAccessException e) { e.printStackTrace(); } catch (InvocationTargetException e) { e.printStackTrace(); } list.add(t); } AggregatedPage<T> result = new AggregatedPageImpl<>(list, pageable, response.getHits().getTotalHits()); return result; } @Override public <T> T mapSearchHit(SearchHit searchHit, Class<T> clz) { String id = searchHit.getSourceAsMap().get("id").toString(); T t = null; if (clz == UserInfo.class) { t = (T) userInfoService.get(id); } else if (clz == Travel.class) { t = (T) travelService.get(id); } else if (clz == Strategy.class) { t = (T) strategyService.get(id); } else if (clz == Destination.class) { t = (T) destinationService.get(id); } else { t = null; } return t; } }); } private Map<String, String> highlightFieldsCopy(Map<String, HighlightField> map, String... fields) { Map<String, String> mm = new HashMap<>(); for (String field : fields) { HighlightField hf = map.get(field); if (hf != null) { Text[] fragments = hf.fragments(); String str = ""; for (Text text : fragments) { str += text; } mm.put(field, str); } } return mm; } }
只分享有用的Java技术资料
扫描二维码关注公众号
笔记|学习资料|面试笔试题|经验分享
如有任何需求或问题欢迎骚扰。微信号:JL2020aini