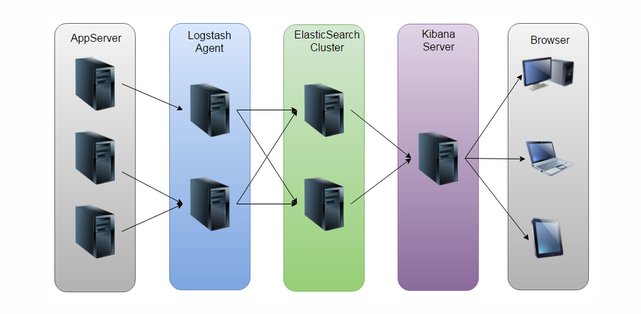
04【在线日志分析】之Flume Agent的3台收集+1台聚合到hdfs的搭建
【log收集】:机器名称 服务名称 用户flume-agent-01: namenode hdfsflume-agent-02: datanode hdfsflume-agent-03: datanode hdfs 【log聚合】:机器名称 用户sht-sgmhadoopcm-01(172.16.101.54) root 【sink到hdfs】:hdfs://172.16.101.56:8020/testwjp/ 1.下载apache-flume-1.7.0-bin.tar.gz[hdfs@flume-agent-01 tmp]$ wget http://www-eu.apache.org/dist/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz--2017-01-04 20:40:10-- http://www-eu.apache.org/dist/flume/1.7.0/apache-flume-1.7.0-bin.tar.gzResolving www-eu.apache.org... 88.198.26.2, 2a01:4f8:130:2192::2Connecting to www-eu.apache.org|88.198.26.2|:80... connected.HTTP request sent, awaiting response... 200 OKLength: 55711670 (53M) [application/x-gzip]Saving to: “apache-flume-1.7.0-bin.tar.gz” 100%[===============================================================================================================================================================================================>] 55,711,670 473K/s in 74s 2017-01-04 20:41:25 (733 KB/s) - “apache-flume-1.7.0-bin.tar.gz” saved [55711670/55711670] 2.解压重命名[hdfs@flume-agent-01 tmp]$ [hdfs@flume-agent-01 tmp]$ tar -xzvf apache-flume-1.7.0-bin.tar.gz [hdfs@flume-agent-01 tmp]$ mv apache-flume-1.7.0-bin flume-ng[hdfs@flume-agent-01 tmp]$ cd flume-ng/conf 3.拷贝flume环境配置和agent配置文件[hdfs@flume-agent-01 tmp]$ cp flume-env.sh.template flume-env.sh[hdfs@flume-agent-01 tmp]$ cp flume-conf.properties.template exec_memory_avro.properties 4.添加hdfs用户的环境变量文件[hdfs@flume-agent-01 tmp]$ cd[hdfs@flume-agent-01 ~]$ ls -latotal 24drwxr-xr-x 3 hdfs hadoop 4096 Jul 8 14:05 .drwxr-xr-x. 35 root root 4096 Dec 10 2015 ..-rw------- 1 hdfs hdfs 4471 Jul 8 17:22 .bash_historydrwxrwxrwt 2 hdfs hadoop 4096 Nov 19 2014 cache-rw------- 1 hdfs hdfs 3131 Jul 8 14:05 .viminfo[hdfs@flume-agent-01 ~]$ cp /etc/skel/.* ./cp: omitting directory `/etc/skel/.'cp: omitting directory `/etc/skel/..'[hdfs@flume-agent-01 ~]$ ls -latotal 36drwxr-xr-x 3 hdfs hadoop 4096 Jan 4 20:49 .drwxr-xr-x. 35 root root 4096 Dec 10 2015 ..-rw------- 1 hdfs hdfs 4471 Jul 8 17:22 .bash_history-rw-r--r-- 1 hdfs hdfs 18 Jan 4 20:49 .bash_logout-rw-r--r-- 1 hdfs hdfs 176 Jan 4 20:49 .bash_profile-rw-r--r-- 1 hdfs hdfs 124 Jan 4 20:49 .bashrcdrwxrwxrwt 2 hdfs hadoop 4096 Nov 19 2014 cache-rw------- 1 hdfs hdfs 3131 Jul 8 14:05 .viminfo 5.添加flume的环境变量[hdfs@flume-agent-01 ~]$ vi .bash_profile export FLUME_HOME=/tmp/flume-ngexport FLUME_CONF_DIR=$FLUME_HOME/confexport PATH=$PATH:$FLUME_HOME/bin[hdfs@flume-agent-01 ~]$ . .bash_profile 6.修改flume环境配置文件[hdfs@flume-agent-01 conf]$ vi flume-env.shexport JAVA_HOME=/usr/java/jdk1.7.0_25 7.将基于Flume-ng Exec Source开发自定义插件AdvancedExecSource的AdvancedExecSource.jar包上传到$FLUME_HOME/lib/http://blog.itpub.net/30089851/viewspace-2131995/ [hdfs@LogshedNameNodeLogcollector lib]$ pwd/tmp/flume-ng/lib[hdfs@LogshedNameNodeLogcollector lib]$ ll AdvancedExecSource.jar -rw-r--r-- 1 hdfs hdfs 10618 Jan 5 23:50 AdvancedExecSource.jar[hdfs@LogshedNameNodeLogcollector lib]$ 8.修改flume的agent配置文件[hdfs@flume-agent-01 conf]$ vi exec_memory_avro.properties# Name the components on this agenta1.sources = r1a1.sinks = k1a1.channels = c1 # Describe/configure the custom exec sourcea1.sources.r1.type = com.onlinelog.analysis.AdvancedExecSourcea1.sources.r1.command = tail -f /var/log/hadoop-hdfs/hadoop-cmf-hdfs1-NAMENODE-flume-agent-01.log.outa1.sources.r1.hostname = flume-agent-01a1.sources.r1.servicename = namenode # Describe the sinka1.sinks.k1.type = avroa1.sinks.k1.hostname = 172.16.101.54a1.sinks.k1.port = 4545 # Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.keep-alive = 60 a1.channels.c1.capacity = 1000000a1.channels.c1.transactionCapacity = 2000 # Bind the source and sink to the channela1.sources.r1.channels = c1a1.sinks.k1.channel = c1 9.将flume-agent-01的flume-ng打包,scp到flume-agent-02/03 和 sht-sgmhadoopcm-01(172.16.101.54)[hdfs@flume-agent-01 tmp]$ zip -r flume-ng.zip flume-ng/* [jpwu@flume-agent-01 ~]$ scp /tmp/flume-ng.zip flume-agent-02:/tmp/[jpwu@flume-agent-01 ~]$ scp /tmp/flume-ng.zip flume-agent-03:/tmp/[jpwu@flume-agent-01 ~]$ scp /tmp/flume-ng.zip sht-sgmhadoopcm-01:/tmp/ 10.在flume-agent-02配置hdfs用户环境变量和解压,修改agent配置文件[hdfs@flume-agent-02 ~]$ cp /etc/skel/.* ./cp: omitting directory `/etc/skel/.'cp: omitting directory `/etc/skel/..'[hdfs@flume-agent-02 ~]$ vi .bash_profileexport FLUME_HOME=/tmp/flume-ngexport FLUME_CONF_DIR=$FLUME_HOME/confexport PATH=$PATH:$FLUME_HOME/bin[hdfs@flume-agent-02 ~]$ . .bash_profile [hdfs@flume-agent-02 tmp]$ unzip flume-ng.zip[hdfs@flume-agent-02 tmp]$ cd flume-ng/conf ##修改以下参数即可[hdfs@flume-agent-02 conf]$ vi exec_memory_avro.propertiesa1.sources.r1.command = tail -f /var/log/hadoop-hdfs/hadoop-cmf-hdfs1-DATANODE-flume-agent-02.log.outa1.sources.r1.hostname = flume-agent-02a1.sources.r1.servicename = datanode ###要检查flume-env.sh的JAVA_HOME目录是否存在 11.在flume-agent-03配置hdfs用户环境变量和解压,修改agent配置文件[hdfs@flume-agent-03 ~]$ cp /etc/skel/.* ./cp: omitting directory `/etc/skel/.'cp: omitting directory `/etc/skel/..'[hdfs@flume-agent-03 ~]$ vi .bash_profileexport FLUME_HOME=/tmp/flume-ngexport FLUME_CONF_DIR=$FLUME_HOME/confexport PATH=$PATH:$FLUME_HOME/bin[hdfs@flume-agent-03 ~]$ . .bash_profile [hdfs@flume-agent-03 tmp]$ unzip flume-ng.zip[hdfs@flume-agent-03 tmp]$ cd flume-ng/conf ##修改以下参数即可[hdfs@flume-agent-03 conf]$ vi exec_memory_avro.propertiesa1.sources.r1.command = tail -f /var/log/hadoop-hdfs/hadoop-cmf-hdfs1-DATANODE-flume-agent-03.log.outa1.sources.r1.hostname = flume-agent-03a1.sources.r1.servicename = datanode ###要检查flume-env.sh的JAVA_HOME目录是否存在 12.聚合端 sht-sgmhadoopcm-01,配置root用户环境变量和解压,修改agent配置文件[root@sht-sgmhadoopcm-01 tmp]# vi /etc/profileexport JAVA_HOME=/usr/java/jdk1.7.0_67-clouderaexport FLUME_HOME=/tmp/flume-ngexport FLUME_CONF_DIR=$FLUME_HOME/conf export PATH=$FLUME_HOME/bin:$JAVA_HOME/bin:$PATH[root@sht-sgmhadoopcm-01 tmp]# source /etc/profile[root@sht-sgmhadoopcm-01 tmp]# [root@sht-sgmhadoopcm-01 tmp]# unzip flume-ng.zip[root@sht-sgmhadoopcm-01 tmp]# cd flume-ng/conf [root@sht-sgmhadoopcm-01 conf]# vi flume-env.shexport JAVA_HOME=/usr/java/jdk1.7.0_67-cloudera ###测试: 先聚合, sink到hdfs端[root@sht-sgmhadoopcm-01 conf]# vi avro_memory_hdfs.properties# Name the components on this agenta1.sources = r1a1.sinks = k1a1.channels = c1 # Describe/configure the sourcea1.sources.r1.type = avroa1.sources.r1.bind = 172.16.101.54a1.sources.r1.port = 4545 # Describe the sinka1.sinks.k1.type = hdfsa1.sinks.k1.hdfs.path = hdfs://172.16.101.56:8020/testwjp/a1.sinks.k1.hdfs.filePrefix = logsa1.sinks.k1.hdfs.inUsePrefix = . a1.sinks.k1.hdfs.rollInterval = 0### roll 16 m = 16777216 bytesa1.sinks.k1.hdfs.rollSize = 1048576a1.sinks.k1.hdfs.rollCount = 0a1.sinks.k1.hdfs.batchSize = 6000 a1.sinks.k1.hdfs.writeFormat = texta1.sinks.k1.hdfs.fileType = DataStream # Use a channel which buffers events in memorya1.channels.c1.type = memorya1.channels.c1.keep-alive = 90 a1.channels.c1.capacity = 1000000a1.channels.c1.transactionCapacity = 6000 # Bind the source and sink to the channela1.sources.r1.channels = c1a1.sinks.k1.channel = c1 13.后台启动[root@sht-sgmhadoopcm-01 flume-ng]# source /etc/profile[hdfs@flume-agent-01 flume-ng]$ . ~/.bash_profile [hdfs@flume-agent-02 flume-ng]$ . ~/.bash_profile [hdfs@flume-agent-03 flume-ng]$ . ~/.bash_profile [root@sht-sgmhadoopnn-01 flume-ng]# nohup flume-ng agent -c conf -f /tmp/flume-ng/conf/avro_memory_hdfs.properties -n a1 -Dflume.root.logger=INFO,console & [hdfs@flume-agent-01 flume-ng]$ nohup flume-ng agent -c /tmp/flume-ng/conf -f /tmp/flume-ng/conf/exec_memory_avro.properties -n a1 -Dflume.root.logger=INFO,console &[hdfs@flume-agent-01 flume-ng]$ nohup flume-ng agent -c /tmp/flume-ng/conf -f /tmp/flume-ng/conf/exec_memory_avro.properties -n a1 -Dflume.root.logger=INFO,console &[hdfs@flume-agent-01 flume-ng]$ nohup flume-ng agent -c /tmp/flume-ng/conf -f /tmp/flume-ng/conf/exec_memory_avro.properties -n a1 -Dflume.root.logger=INFO,console &14.校验:将集群的日志下载到本地,打开查看即可(略) ------------------------------------------------------------------------------------------------------------------------------------------------ 【备注】: 1.错误1 flume-ng安装的机器上没有hadoop环境,所以假如sink到hdfs话,需要用到hdfs的jar包[ERROR - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:146)] Failed to start agent because dependencies were not found in classpath. Error follows.java.lang.NoClassDefFoundError: org/apache/hadoop/io/SequenceFile$CompressionType 只需在其他安装hadoop机器上搜索以下5个jar包,拷贝到$FLUME_HOME/lib目录即可。搜索方法: find $HADOOP_HOME/ -name commons-configuration*.jar commons-configuration-1.6.jarhadoop-auth-2.7.3.jarhadoop-common-2.7.3.jarhadoop-hdfs-2.7.3.jarhadoop-mapreduce-client-core-2.7.3.jarprotobuf-java-2.5.0.jarhtrace-core-3.1.0-incubating.jarcommons-io-2.4.jar 2.错误2 无法加载自定义插件的类 Unable to load source type: com.onlinelog.analysis.AdvancedExecSource2017-01-06 21:10:48,278 (conf-file-poller-0) [ERROR - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:142)] Failed to load configuration data. Exception follows.org.apache.flume.FlumeException: Unable to load source type: com.onlinelog.analysis.AdvancedExecSource, class: com.onlinelog.analysis.AdvancedExecSource 执行hdfs或者root用户的环境变量即可[root@sht-sgmhadoopcm-01 flume-ng]# source /etc/profile[hdfs@flume-agent-01 flume-ng]$ . ~/.bash_profile [hdfs@flume-agent-02 flume-ng]$ . ~/.bash_profile [hdfs@flume-agent-03 flume-ng]$ . ~/.bash_profile