Appium+python自动化27-等待activity出现(android特有的wait_activity)
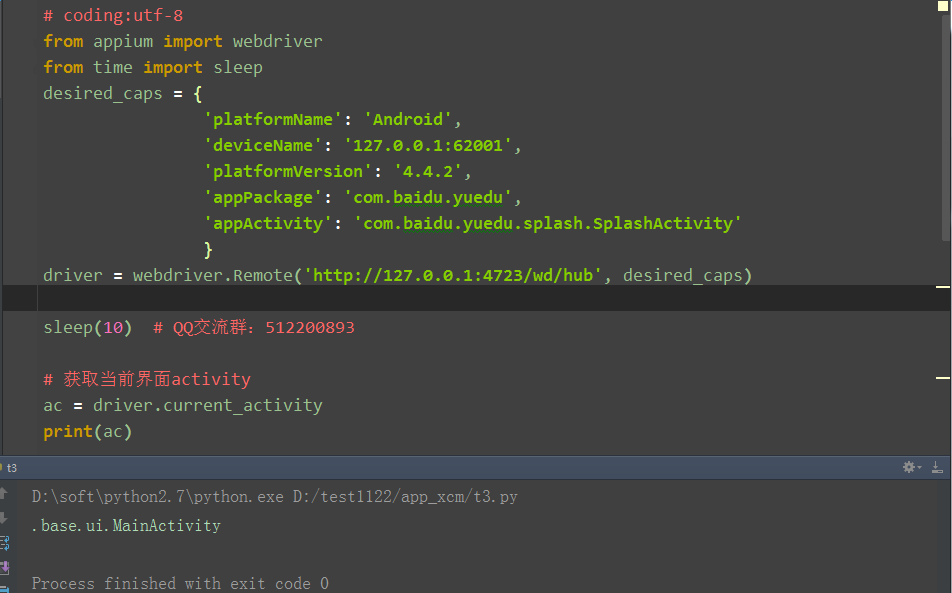
前言 在启动app的时候,如果直接做下一步点击操作,经常会报错,于是我们会在启动完成的时候加sleep。 那么问题来了,这个sleep时间到底设置多少合适呢?设置长了,就浪费时间,设置短了,就会找不到元素报错了。 这个时候我们可以用wait_activity的语法,等到你想点击的页面activity出现了,再点击,可以有效的节省时间。 wait_activity 1.查看源码 def wait_activity(self, activity, timeout, interval=1): """Wait for an activity: block until target activity presents or time out. This is an Android-only method. :Agrs: - activity - target activity - timeout - max wait time, in seconds - interval - sleep interval between retries, in seconds """ try: WebDriverWait(self, timeout, interval).until( lambda d: d.current_activity == activity) return True except TimeoutException: return False 2.解释说明: wait_activity(self, activity, timeout, interval=1): 等待指定的activity出现直到超时,interval为扫描间隔1秒 即每隔几秒获取一次当前的activity android特有的 返回的True 或 False :Agrs: - activity - 需等待的目标 activity - timeout - 最大超时时间,单位是s - interval - 循环查询时间 用法:driver.wait_activity(‘.activity.xxx’,5,2) 获取current_activity 1.打开app后,先sleep10秒,等app完全启动完成进入主页面,然后获取当前界面的activity # coding:utf-8 from appium import webdriver from time import sleep desired_caps = { 'platformName': 'Android', 'deviceName': '127.0.0.1:62001', 'platformVersion': '4.4.2', 'appPackage': 'com.baidu.yuedu', 'appActivity': 'com.baidu.yuedu.splash.SplashActivity' } driver = webdriver.Remote('http://127.0.0.1:4723/wd/hub', desired_caps) sleep(10) # 获取当前界面activity ac = driver.current_activity print(ac) 2.运行结果: 等待activity 1.用sleep太浪费时间了,并且不知道什么时候能启动完成,所以尽量不用sleep 2.上一步已经获取当主页面的activity了,那就可以用wait_activity等它出现了,再做下一步的点击操作 3.参考代码 # coding:utf-8 from appium import webdriver from time import sleep desired_caps = { 'platformName': 'Android', 'deviceName': '127.0.0.1:62001', 'platformVersion': '4.4.2', 'appPackage': 'com.baidu.yuedu', 'appActivity': 'com.baidu.yuedu.splash.SplashActivity' } driver = webdriver.Remote('http://127.0.0.1:4723/wd/hub', desired_caps) # sleep(10) # 不用sleep # 获取当前界面activity ac = driver.current_activity print(ac) # 等主页面activity出现,30秒内 driver.wait_activity(".base.ui.MainActivity", 30) # 点知道了 driver.find_element_by_id("com.baidu.yuedu:id/positive").click()