[雪峰磁针石博客]数据分析工具pandas快速入门教程2-pandas数据结构
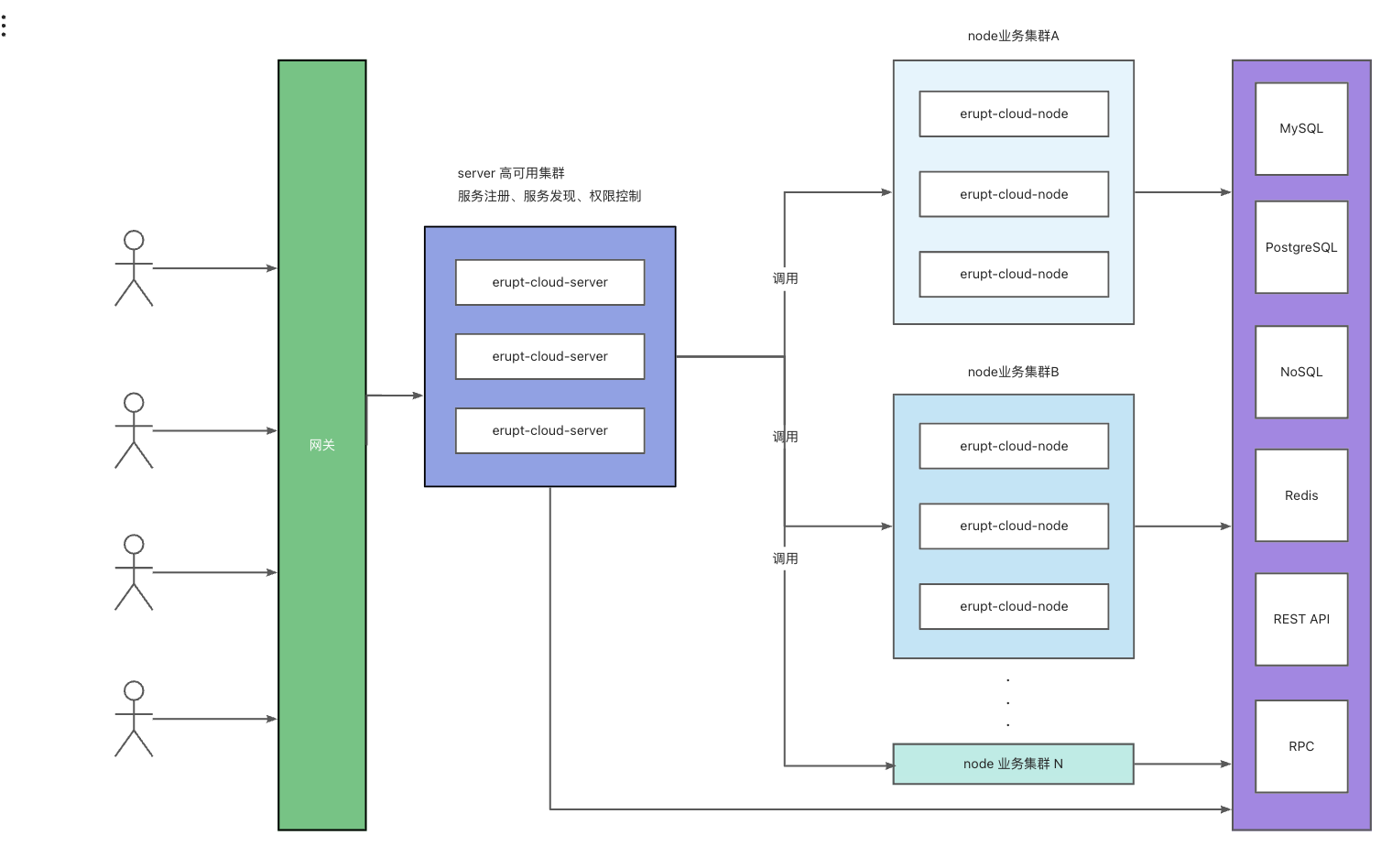
创建数据 Series和python的列表类似。DataFrame则类似值为Series的字典。 create.py #!/usr/bin/env python3 # -*- coding: utf-8 -*- # create.py import pandas as pd print("\n\n创建序列Series") s = pd.Series(['banana', 42]) print(s) print("\n\n指定索引index创建序列Series") s = pd.Series(['Wes McKinney', 'Creator of Pandas'], index=['Person', 'Who']) print(s) # 注意:列名未必为执行的顺序,通常为按字母排序 print("\n\n创建数据帧DataFrame") scientists = pd.DataFrame({ ' Name': ['Rosaline Franklin', 'William Gosset'], ' Occupation': ['Chemist', 'Statistician'], ' Born': ['1920-07-25', '1876-06-13'], ' Died': ['1958-04-16', '1937-10-16'], ' Age': [37, 61]}) print(scientists) print("\n\n指定顺序(index和columns)创建数据帧DataFrame") scientists = pd.DataFrame( data={'Occupation': ['Chemist', 'Statistician'], 'Born': ['1920-07-25', '1876-06-13'], 'Died': ['1958-04-16', '1937-10-16'], 'Age': [37, 61]}, index=['Rosaline Franklin', 'William Gosset'], columns=['Occupation', 'Born', 'Died', 'Age']) print(scientists) 执行结果: $ ./create.py 创建序列Series 0 banana 1 42 dtype: object 指定索引index创建序列Series Person Wes McKinney Who Creator of Pandas dtype: object 创建数据帧DataFrame Name Occupation Born Died Age 0 Rosaline Franklin Chemist 1920-07-25 1958-04-16 37 1 William Gosset Statistician 1876-06-13 1937-10-16 61 指定顺序(index和columns)创建数据帧DataFrame Occupation Born Died Age Rosaline Franklin Chemist 1920-07-25 1958-04-16 37 William Gosset Statistician 1876-06-13 1937-10-16 61 Series 官方文档:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.Series.html Series的属性 属性 描述 loc 使用索引值获取子集 iloc 使用索引位置获取子集 dtype或dtypes 类型 T 转置 shape 数据的尺寸 size 元素的数量 values ndarray或类似ndarray的Series Series的方法 方法 描述 append 连接2个或更多系列 corr 计算与其他Series的关联 cov 与其他Series计算协方差 describe 计算汇总统计 drop duplicates 返回一个没有重复项的Series equals Series是否具有相同的元素 get values 获取Series的值,与values属性相同 hist 绘制直方图 min 返回最小值 max 返回最大值 mean 返回算术平均值 median 返回中位数 mode(s) 返回mode(s) replace 用指定值替换系列中的值 sample 返回Series中值的随机样本 sort values 排序 to frame 转换为数据帧 transpose 返回转置 unique 返回numpy.ndarray唯一值 series.py #!/usr/bin/python3 # -*- coding: utf-8 -*- # CreateDate: 2018-3-14 # series.py import pandas as pd import numpy as np scientists = pd.DataFrame( data={'Occupation': ['Chemist', 'Statistician'], 'Born': ['1920-07-25', '1876-06-13'], 'Died': ['1958-04-16', '1937-10-16'], 'Age': [37, 61]}, index=['Rosaline Franklin', 'William Gosset'], columns=['Occupation', 'Born', 'Died', 'Age']) print(scientists) # 从数据帧(DataFrame)获取的行或者列为Series first_row = scientists.loc['William Gosset'] print(type(first_row)) print(first_row) # index和keys是一样的 print(first_row.index) print(first_row.keys()) print(first_row.values) print(first_row.index[0]) print(first_row.keys()[0]) # Pandas.Series和numpy.ndarray很类似 ages = scientists['Age'] print(ages) # 统计,更多参考http://pandas.pydata.org/pandas-docs/stable/basics.html#descriptive-statistics print(ages.mean()) print(ages.min()) print(ages.max()) print(ages.std()) scientists = pd.read_csv('../data/scientists.csv') ages = scientists['Age'] print(ages) print(ages.mean()) print(ages.describe()) print(ages[ages > ages.mean()]) print(ages > ages.mean()) manual_bool_values = [True, True, False, False, True, True, False, False] print(ages[manual_bool_values]) print(ages + ages) print(ages * ages) print(ages + 100) print(ages * 2) print(ages + pd.Series([1, 100])) # print(ages + np.array([1, 100])) 会报错,不同类型相加,大小一定要一样 print(ages + np.array([1, 100, 1, 100, 1, 100, 1, 100])) # 排序: 默认有自动排序 print(ages) rev_ages = ages.sort_index(ascending=False) print(rev_ages) print(ages * 2) print(ages + rev_ages) 执行结果 $ python3 series.py Occupation Born Died Age Rosaline Franklin Chemist 1920-07-25 1958-04-16 37 William Gosset Statistician 1876-06-13 1937-10-16 61 <class 'pandas.core.series.Series'> Occupation Statistician Born 1876-06-13 Died 1937-10-16 Age 61 Name: William Gosset, dtype: object Index(['Occupation', 'Born', 'Died', 'Age'], dtype='object') Index(['Occupation', 'Born', 'Died', 'Age'], dtype='object') ['Statistician' '1876-06-13' '1937-10-16' 61] Occupation Occupation Rosaline Franklin 37 William Gosset 61 Name: Age, dtype: int64 49.0 37 61 16.97056274847714 0 37 1 61 2 90 3 66 4 56 5 45 6 41 7 77 Name: Age, dtype: int64 59.125 count 8.000000 mean 59.125000 std 18.325918 min 37.000000 25% 44.000000 50% 58.500000 75% 68.750000 max 90.000000 Name: Age, dtype: float64 1 61 2 90 3 66 7 77 Name: Age, dtype: int64 0 False 1 True 2 True 3 True 4 False 5 False 6 False 7 True Name: Age, dtype: bool 0 37 1 61 4 56 5 45 Name: Age, dtype: int64 0 74 1 122 2 180 3 132 4 112 5 90 6 82 7 154 Name: Age, dtype: int64 0 1369 1 3721 2 8100 3 4356 4 3136 5 2025 6 1681 7 5929 Name: Age, dtype: int64 0 137 1 161 2 190 3 166 4 156 5 145 6 141 7 177 Name: Age, dtype: int64 0 74 1 122 2 180 3 132 4 112 5 90 6 82 7 154 Name: Age, dtype: int64 0 38.0 1 161.0 2 NaN 3 NaN 4 NaN 5 NaN 6 NaN 7 NaN dtype: float64 0 38 1 161 2 91 3 166 4 57 5 145 6 42 7 177 Name: Age, dtype: int64 0 37 1 61 2 90 3 66 4 56 5 45 6 41 7 77 Name: Age, dtype: int64 7 77 6 41 5 45 4 56 3 66 2 90 1 61 0 37 Name: Age, dtype: int64 0 74 1 122 2 180 3 132 4 112 5 90 6 82 7 154 Name: Age, dtype: int64 0 74 1 122 2 180 3 132 4 112 5 90 6 82 7 154 Name: Age, dtype: int64 数据帧(DataFrame) DataFrame是最常见的Pandas对象,可认为是Python存储类似电子表格的数据的方式。Series多常见功能都包含在DataFrame中。 子集的方法 注意ix现在已经不推荐使用。 DataFrame常用的索引操作有: 方式 描述 df[val] 选择单个列 df [[ column1, column2, ... ]] 选择多个列 df.loc[val] 选择行 loc [[ label1 , label2 ,...]] | 选择多行 |df.loc[:, val] | 基于行index选择列 | df.loc[val1, val2] | 选择行列 |df.iloc[row number] | 基于行数选择行 | iloc [[ row1, row2, ...]] Multiple rows by row number | 基于行数选择多行 |df.iloc[:, where] | 选择列 | df.iloc[where_i, where_j] | 选择行列 |df.at[label_i, label_j] | 选择值 |df.iat[i, j] | 选择值 |reindex method | 通过label选择多行或列 |get_value, set_value | 通过label选择耽搁行或列 df[bool] | 选择行df [[ bool1, bool2, ...]] | 选择行df[ start :stop: step ] | 基于行数选择行 #!/usr/bin/python3 # -*- coding: utf-8 -*- # CreateDate: 2018-3-31 # df.py import pandas as pd import numpy as np scientists = pd.read_csv('../data/scientists.csv') print(scientists[scientists['Age'] > scientists['Age'].mean()]) first_half = scientists[: 4] second_half = scientists[ 4 :] print(first_half) print(second_half) print(first_half + second_half) print(scientists * 2) 执行结果 #!/usr/bin/python3 # -*- coding: utf-8 -*- # df.py import pandas as pd import numpy as np scientists = pd.read_csv('../data/scientists.csv') print(scientists[scientists['Age'] > scientists['Age'].mean()]) first_half = scientists[: 4] second_half = scientists[ 4 :] print(first_half) print(second_half) print(first_half + second_half) print(scientists * 2) 执行结果 $ python3 df.py Name Born Died Age Occupation 1 William Gosset 1876-06-13 1937-10-16 61 Statistician 2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse 3 Marie Curie 1867-11-07 1934-07-04 66 Chemist 7 Johann Gauss 1777-04-30 1855-02-23 77 Mathematician Name Born Died Age Occupation 0 Rosaline Franklin 1920-07-25 1958-04-16 37 Chemist 1 William Gosset 1876-06-13 1937-10-16 61 Statistician 2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse 3 Marie Curie 1867-11-07 1934-07-04 66 Chemist Name Born Died Age Occupation 4 Rachel Carson 1907-05-27 1964-04-14 56 Biologist 5 John Snow 1813-03-15 1858-06-16 45 Physician 6 Alan Turing 1912-06-23 1954-06-07 41 Computer Scientist 7 Johann Gauss 1777-04-30 1855-02-23 77 Mathematician Name Born Died Age Occupation 0 NaN NaN NaN NaN NaN 1 NaN NaN NaN NaN NaN 2 NaN NaN NaN NaN NaN 3 NaN NaN NaN NaN NaN 4 NaN NaN NaN NaN NaN 5 NaN NaN NaN NaN NaN 6 NaN NaN NaN NaN NaN 7 NaN NaN NaN NaN NaN Name Born \ 0 Rosaline FranklinRosaline Franklin 1920-07-251920-07-25 1 William GossetWilliam Gosset 1876-06-131876-06-13 2 Florence NightingaleFlorence Nightingale 1820-05-121820-05-12 3 Marie CurieMarie Curie 1867-11-071867-11-07 4 Rachel CarsonRachel Carson 1907-05-271907-05-27 5 John SnowJohn Snow 1813-03-151813-03-15 6 Alan TuringAlan Turing 1912-06-231912-06-23 7 Johann GaussJohann Gauss 1777-04-301777-04-30 Died Age Occupation 0 1958-04-161958-04-16 74 ChemistChemist 1 1937-10-161937-10-16 122 StatisticianStatistician 2 1910-08-131910-08-13 180 NurseNurse 3 1934-07-041934-07-04 132 ChemistChemist 4 1964-04-141964-04-14 112 BiologistBiologist 5 1858-06-161858-06-16 90 PhysicianPhysician 6 1954-06-071954-06-07 82 Computer ScientistComputer Scientist 7 1855-02-231855-02-23 154 MathematicianMathematician 修改列 #!/usr/bin/python3 # -*- coding: utf-8 -*- # Author: xurongzhong#126.com wechat:pythontesting qq:37391319 # qq群:144081101 591302926 567351477 # CreateDate: 2018-06-07 # change.py import pandas as pd import numpy as np import random scientists = pd.read_csv('../data/scientists.csv') print(scientists['Born'].dtype) print(scientists['Died'].dtype) print(scientists.head()) # 转为日期 参考:https://docs.python.org/3.5/library/datetime.html born_datetime = pd.to_datetime(scientists['Born'], format='%Y-%m-%d') died_datetime = pd.to_datetime(scientists['Died'], format='%Y-%m-%d') # 增加列 scientists['born_dt'], scientists['died_dt'] = (born_datetime, died_datetime) print(scientists.shape) print(scientists.head()) random.seed(42) random.shuffle(scientists['Age']) # 此修改会作用于scientists print(scientists.head()) scientists['age_days_dt'] = (scientists['died_dt'] - scientists['born_dt']) print(scientists.head()) 执行结果: $ python3 change.py object object Name Born Died Age Occupation 0 Rosaline Franklin 1920-07-25 1958-04-16 37 Chemist 1 William Gosset 1876-06-13 1937-10-16 61 Statistician 2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse 3 Marie Curie 1867-11-07 1934-07-04 66 Chemist 4 Rachel Carson 1907-05-27 1964-04-14 56 Biologist (8, 7) Name Born Died Age Occupation born_dt \ 0 Rosaline Franklin 1920-07-25 1958-04-16 37 Chemist 1920-07-25 1 William Gosset 1876-06-13 1937-10-16 61 Statistician 1876-06-13 2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse 1820-05-12 3 Marie Curie 1867-11-07 1934-07-04 66 Chemist 1867-11-07 4 Rachel Carson 1907-05-27 1964-04-14 56 Biologist 1907-05-27 died_dt 0 1958-04-16 1 1937-10-16 2 1910-08-13 3 1934-07-04 4 1964-04-14 /usr/lib/python3.5/random.py:272: SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/indexing.html#indexing-view-versus-copy x[i], x[j] = x[j], x[i] Name Born Died Age Occupation born_dt \ 0 Rosaline Franklin 1920-07-25 1958-04-16 66 Chemist 1920-07-25 1 William Gosset 1876-06-13 1937-10-16 56 Statistician 1876-06-13 2 Florence Nightingale 1820-05-12 1910-08-13 41 Nurse 1820-05-12 3 Marie Curie 1867-11-07 1934-07-04 77 Chemist 1867-11-07 4 Rachel Carson 1907-05-27 1964-04-14 90 Biologist 1907-05-27 died_dt 0 1958-04-16 1 1937-10-16 2 1910-08-13 3 1934-07-04 4 1964-04-14 Name Born Died Age Occupation born_dt \ 0 Rosaline Franklin 1920-07-25 1958-04-16 66 Chemist 1920-07-25 1 William Gosset 1876-06-13 1937-10-16 56 Statistician 1876-06-13 2 Florence Nightingale 1820-05-12 1910-08-13 41 Nurse 1820-05-12 3 Marie Curie 1867-11-07 1934-07-04 77 Chemist 1867-11-07 4 Rachel Carson 1907-05-27 1964-04-14 90 Biologist 1907-05-27 died_dt age_days_dt 0 1958-04-16 13779 days 1 1937-10-16 22404 days 2 1910-08-13 32964 days 3 1934-07-04 24345 days 4 1964-04-14 20777 days 数据导入导出 out.py #!/usr/bin/python3 # -*- coding: utf-8 -*- # Author: china-testing#126.com wechat:pythontesting qq群:630011153 # CreateDate: 2018-3-31 # out.py import pandas as pd import numpy as np import random scientists = pd.read_csv('../data/scientists.csv') names = scientists['Name'] print(names) names.to_pickle('../output/scientists_names_series.pickle') scientists.to_pickle('../output/scientists_df.pickle') # .p, .pkl, .pickle 是常用的pickle文件扩展名 scientist_names_from_pickle = pd.read_pickle('../output/scientists_df.pickle') print(scientist_names_from_pickle) names.to_csv('../output/scientist_names_series.csv') scientists.to_csv('../output/scientists_df.tsv', sep='\t') # 不输出行号 scientists.to_csv('../output/scientists_df_no_index.csv', index=None) # Series可以转为df再输出成excel文件 names_df = names.to_frame() names_df.to_excel('../output/scientists_names_series_df.xls') names_df.to_excel('../output/scientists_names_series_df.xlsx') scientists.to_excel('../output/scientists_df.xlsx', sheet_name='scientists', index=False) 执行结果: $ python3 out.py 0 Rosaline Franklin 1 William Gosset 2 Florence Nightingale 3 Marie Curie 4 Rachel Carson 5 John Snow 6 Alan Turing 7 Johann Gauss Name: Name, dtype: object Name Born Died Age Occupation 0 Rosaline Franklin 1920-07-25 1958-04-16 37 Chemist 1 William Gosset 1876-06-13 1937-10-16 61 Statistician 2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse 3 Marie Curie 1867-11-07 1934-07-04 66 Chemist 4 Rachel Carson 1907-05-27 1964-04-14 56 Biologist 5 John Snow 1813-03-15 1858-06-16 45 Physician 6 Alan Turing 1912-06-23 1954-06-07 41 Computer Scientist 7 Johann Gauss 1777-04-30 1855-02-23 77 Mathematician 注意:序列一般是直接输出成excel文件 更多的输入输出方法: 方式 描述 to_clipboard 将数据保存到系统剪贴板进行粘贴 to_dense 将数据转换为常规“密集”DataFrame to_dict 将数据转换为Python字典 to_gbq 将数据转换为Google BigQuery表格 toJidf 将数据保存为分层数据格式(HDF) to_msgpack 将数据保存到可移植的类似JSON的二进制文件中 toJitml 将数据转换为HTML表格 tojson 将数据转换为JSON字符串 toJatex 将数据转换为LTEXtabular环境 to_records 将数据转换为记录数组 to_string 将DataFrame显示为stdout的字符串 to_sparse 将数据转换为SparceDataFrame to_sql 将数据保存到SQL数据库中 to_stata 将数据转换为Stata dta文件 读CSV文件 read_csv.py #!/usr/bin/python3 # -*- coding: utf-8 -*- # Author: china-testing#126.com wechat:pythontesting QQ群:630011153 # CreateDate: 2018-3-9 # read_csv.py import pandas as pd df = pd.read_csv("1.csv", header=None) # 不读取列名 print("df:") print(df) print("df.head():") print(df.head()) # head(self, n=5),默认为5行,类似的有tail print("df.tail():") print(df.tail()) df = pd.read_csv("1.csv") # 默认读取列名 print("df:") print(df) df = pd.read_csv("1.csv", names=['号码','群号']) # 自定义列名 print("df:") print(df) # 自定义列名,去掉第一行 df = pd.read_csv("1.csv", skiprows=[0], names=['号码','群号']) print("df:") print(df) 执行结果: df: 0 1 0 qq qqgroup 1 37391319 144081101 2 37391320 144081102 3 37391321 144081103 4 37391322 144081104 5 37391323 144081105 6 37391324 144081106 7 37391325 144081107 8 37391326 144081108 9 37391327 144081109 10 37391328 144081110 11 37391329 144081111 12 37391330 144081112 13 37391331 144081113 14 37391332 144081114 15 37391333 144081115 df.head(): 0 1 0 qq qqgroup 1 37391319 144081101 2 37391320 144081102 3 37391321 144081103 4 37391322 144081104 df.tail(): 0 1 11 37391329 144081111 12 37391330 144081112 13 37391331 144081113 14 37391332 144081114 15 37391333 144081115 df: qq qqgroup 0 37391319 144081101 1 37391320 144081102 2 37391321 144081103 3 37391322 144081104 4 37391323 144081105 5 37391324 144081106 6 37391325 144081107 7 37391326 144081108 8 37391327 144081109 9 37391328 144081110 10 37391329 144081111 11 37391330 144081112 12 37391331 144081113 13 37391332 144081114 14 37391333 144081115 df: 号码 群号 0 qq qqgroup 1 37391319 144081101 2 37391320 144081102 3 37391321 144081103 4 37391322 144081104 5 37391323 144081105 6 37391324 144081106 7 37391325 144081107 8 37391326 144081108 9 37391327 144081109 10 37391328 144081110 11 37391329 144081111 12 37391330 144081112 13 37391331 144081113 14 37391332 144081114 15 37391333 144081115 df: 号码 群号 0 37391319 144081101 1 37391320 144081102 2 37391321 144081103 3 37391322 144081104 4 37391323 144081105 5 37391324 144081106 6 37391325 144081107 7 37391326 144081108 8 37391327 144081109 9 37391328 144081110 10 37391329 144081111 11 37391330 144081112 12 37391331 144081113 13 37391332 144081114 14 37391333 144081115 写CSV文件 #!/usr/bin/python3 # -*- coding: utf-8 -*- # write_csv.py import pandas as pd data ={'qq': [37391319,37391320], 'group':[1,2]} df = pd.DataFrame(data=data, columns=['qq','group']) df.to_csv('2.csv',index=False) 读写excel和csv类似,不过要改用read_excel来读,excel_summary_demo, 提供了多个excel求和的功能,可以做为excel读写的实例,这里不再赘述。 参考资料 技术支持qq群144081101 591302926 567351477 钉钉免费群21745728 本文最新版本地址 本文涉及的python测试开发库 谢谢点赞! 本文相关海量书籍下载 源码下载 本文英文版书籍下载