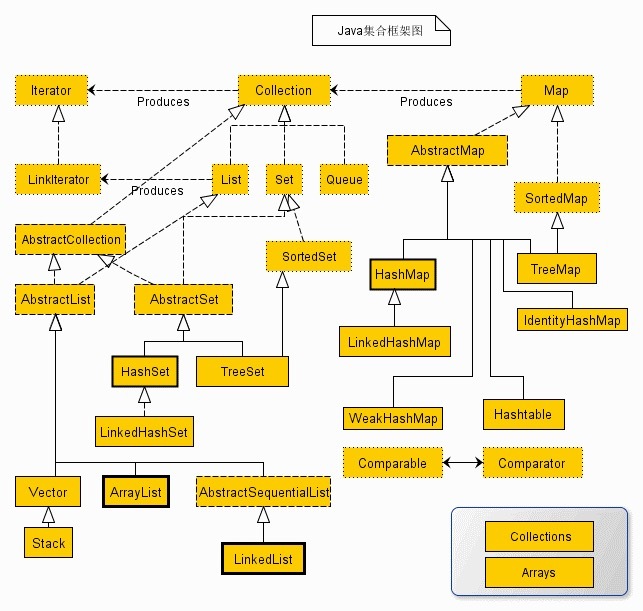
django面试题(21道)
1、什么是wsgi? WSGI是Python在处理HTTP请求时,规定的一种处理方式。如一个HTTP Request过来了,那么就有一个相应的处理函数来进行处理和返回结果。WSGI就是规定这个处理函数的参数长啥样的,它的返回结果是长啥样的?至于该处理函数的名子和处理逻辑是啥样的,那无所谓。简单而言,WSGI就是规定了处理函数的输入和输出格式。 2、django请求的生命周期? . 当用户在浏览器中输入url时,浏览器会生成请求头和请求体发给服务端 请求头和请求体中会包含浏览器的动作(action),这个动作通常为get或者post,体现在url之中. . url经过Django中的wsgi,再经过Django的中间件,最后url到过路由映射表,在路由中一条一条进行匹配, 一旦其中一条匹配成功就执行对应的视图函数,后面的路由就不再继续匹配了. . 视图函数根据客户端的请求查询相应的数据.返回给Django,然后Django把客户端想要的数据做为一个字符串返回给客户端. . 客户端浏览器接收到返回的数据,经过渲染后显示给用户. 3、列举django的内置组件? .Admin是对model中对应的数据表进行增删改查提供的组件 .model组件:负责操作数据库 .form组件:1.生成HTML代码2.数据有效性校验3校验信息返回并展示 .ModelForm组件即用于数据库操作,也可用于用户请求的验证 4、列举django中间件的5个方法?以及django中间件的应用场景? .process_request : 请求进来时,权限认证 .process_view : 路由匹配之后,能够得到视图函数 .process_exception : 异常时执行 .process_template_responseprocess : 模板渲染时执行 .process_response : 请求有响应时执行 5、简述什么是FBV和CBV? FBV和CBV本质是一样的,基于函数的视图叫做FBV,基于类的视图叫做CBV 在python中使用CBV的优点: - .提高了代码的复用性,可以使用面向对象的技术,比如Mixin(多继承) - .可以用不同的函数针对不同的HTTP方法处理,而不是通过很多if判断,提高代码可读性 6、django的request对象是在什么时候创建的? class WSGIHandler(base.BaseHandler):-------request = self.request_class(environ) 请求走到WSGIHandler类的时候,执行cell方法,将environ封装成了request 7、如何给CBV的程序添加装饰器? from django.utils.decorators import method_decorator 1、给方法加: @method_decorator(check_login) def post(self, request): ... 2、给dispatch加: @method_decorator(check_login) def dispatch(self, request, *args, **kwargs): ... 3、给类加: @method_decorator(check_login, name="get") @method_decorator(check_login, name="post") class HomeView(View): ... 8、列举django orm 中所有的方法(QuerySet对象的所有方法) <1> all(): 查询所有结果 <2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象。获取不到返回None <3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个。 如果符合筛选条件的对象超过一个或者没有都会抛出错误。 <4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象 <5> order_by(*field): 对查询结果排序 <6> reverse(): 对查询结果反向排序 <8> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 <9> first(): 返回第一条记录 <10> last(): 返回最后一条记录 <11> exists(): 如果QuerySet包含数据,就返回True,否则返回False <12> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的 并不是一系 model的实例化对象,而是一个可迭代的字典序列 <13> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列 <14> distinct(): 从返回结果中剔除重复纪录 9、select_related和prefetch_related的区别? 前提:有外键存在时,可以很好的减少数据库请求的次数,提高性能 select_related通过多表join关联查询,一次性获得所有数据,只执行一次SQL查询 prefetch_related分别查询每个表,然后根据它们之间的关系进行处理,执行两次查询 10、filter和exclude的区别? 两者取到的值都是QuerySet对象,filter选择满足条件的,exclude:排除满足条件的. 11、列举django orm中三种能写sql语句的方法 1.使用execute执行自定义的SQL 直接执行SQL语句(类似于pymysql的用法) # 更高灵活度的方式执行原生SQL语句 from django.db import connection cursor = connection.cursor() cursor.execute("SELECT DATE_FORMAT(create_time, '%Y-%m') FROM blog_article;") ret = cursor.fetchall() print(ret) 2.使用extra方法 :queryset.extra(select={"key": "原生的SQL语句"}) 3.使用raw方法 1.执行原始sql并返回模型 2.依赖model多用于查询 12、values和values_list的区别? values : queryset类型的列表中是字典 values_list : queryset类型的列表中是元组 13、cookie和session的区别: .cookie: cookie是保存在浏览器端的键值对,可以用来做用户认证 .session: 将用户的会话信息保存在服务端,key值是随机产生的字符串,value值是session的内容 依赖于cookie将每个用户的随机字符串保存到用户浏览器上 Django中session默认保存在数据库中:django_session表 flask,session默认将加密的数据写在用户的cookie中 14、如何使用django orm批量创建数据? objs=[models.Book(title="图书{}".format(i+15)) for i in range(100)] models.Book.objects.bulk_create(objs) 15、django的Form组件中,如果字段中包含choices参数,请使用两种方式实现数据源实时更新 1.重写构造函数 def__init__(self, *args, **kwargs): super().__init__(*args, **kwargs) self.fields["city"].widget.choices = models.City.objects.all().values_list("id", "name") 2.利用ModelChoiceField字段,参数为queryset对象authors = form_model.ModelMultipleChoiceField(queryset=models.NNewType.objects.all())//多选 16、django的Model中的ForeignKey字段中的on_delete参数有什么作用? 删除关联表中的数据时,当前表与其关联的field的操作 django2.0之后,表与表之间关联的时候,必须要写on_delete参数,否则会报异常 17、django的模板中自定义filter和simple_tag的区别? 自定义filter:{{ 参数1|filter函数名:参数2 }} 1.可以与if标签来连用 2.自定义时需要写两个形参 例子:自定义filter 1. 在app01下创建一个叫templatetags的Python包 2. 在templatetags的文件夹下创建py文件 myfilters 3. 在py文件中写代码 from django import template register = template.Library() @register.filter def add_sb(value,arg='aaa'): return "{}_sb_{}".formart(value,arg) @register.filter(name='sb') def add_sb(value,arg='aaa'): return "{}_sb_{}".formart(value,arg) 4. 使用自定义filter {% load myfilters %} {{ name|add_sb:'xxx'}} {{ name|sb:'xxx'}} simple_tag:{% simple_tag函数名 参数1 参数2 %} 1.可以传多个参数,没有限制 2.不能与if标签来连用 例子:自定义simpletag 创建 1 、在app01中创建一个名字是templatetags的包, 2、在包中创建一个py文件 3、在py文件中导入 from django import template register = template.Library() 4、写函数 @register.simple_tag(name="plus") def plus(a,b,c): return '{}+{}+{}'.format(a,b,c) 5、加装饰器@register.simple_tag(name="plus") 使用 1、导入 {% load mytag %} 2、使用 {% plus 1 2 3 %} 18、django中csrf的实现机制 第一步:django第一次响应来自某个客户端的请求时,后端随机产生一个token值,把这个token保存在SESSION状态中;同时,后端把这个token放到cookie中交给前端页面; 第二步:下次前端需要发起请求(比如发帖)的时候把这个token值加入到请求数据或者头信息中,一起传给后端;Cookies:{csrftoken:xxxxx} 第三步:后端校验前端请求带过来的token和SESSION里的token是否一致。 19、基于django使用ajax发送post请求时,都可以使用哪种方法携带csrf token? 1.后端将csrftoken传到前端,发送post请求时携带这个值发送 data: { csrfmiddlewaretoken: '{{ csrf_token }}' }, 2.获取form中隐藏标签的csrftoken值,加入到请求数据中传给后端 data: { csrfmiddlewaretoken:$('[name="csrfmiddlewaretoken"]').val() }, 3.cookie中存在csrftoken,将csrftoken值放到请求头中 headers:{ "X-CSRFtoken":$.cookie("csrftoken")} 20、Django本身提供了runserver,为什么不能用来部署?(runserver与uWSGI的区别) 1.runserver方法是调试 Django 时经常用到的运行方式,它使用Django自带的 WSGI Server 运行,主要在测试和开发中使用,并且 runserver 开启的方式也是单进程 。 2.uWSGI是一个Web服务器,它实现了WSGI协议、uwsgi、http 等协议。注意uwsgi是一种通信协议,而uWSGI是实现uwsgi协议和WSGI协议的 Web 服务器。uWSGI具有超快的性能、低内存占用和多app管理等优点,并且搭配着Nginx就是一个生产环境了,能够将用户访问请求与应用 app 隔离开,实现真正的部署 。相比来讲,支持的并发量更高,方便管理多进程,发挥多核的优势,提升性能。 21、Django如何实现websocket? django实现websocket官方推荐大家使用channels。channels通过升级http协议 升级到websocket协议。保证实时通讯。也就是说,我们完全可以用channels实现我们的即时通讯。而不是使用长轮询和计时器方式来保证伪实时通讯。他通过改造django框架,使django既支持http协议又支持websocket协议。 官方文档地址:https://channels.readthedocs.io/en/stable/