踏上kubernetes的第一步:集群环境部署介绍
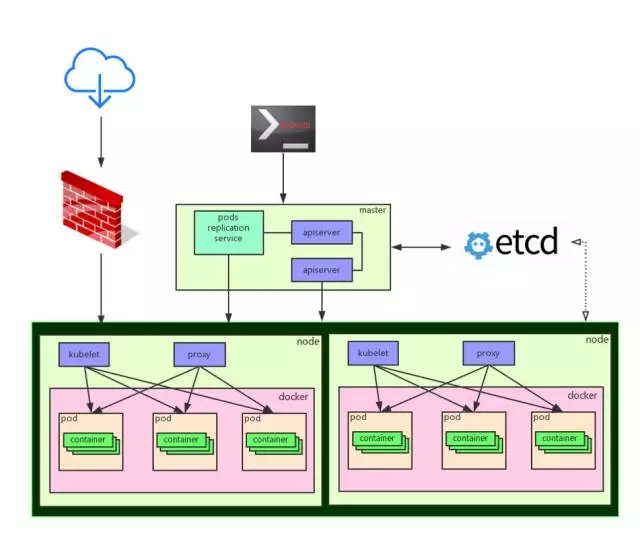
一、简介 redhat 在今年9月份发布了k8s 和 etcd 的yum 源(redhat 7),我们下面都是基于redhat 7操作系统以yum来构建k8s集群,你也可以到github 下载kubernetes 进行安装部署 下面是k8s集群架构 二、架构部署 基本信息 2.1 etcd 安装配置(etcd) 安装etcd 配置 etcd配置文件 这里我直接使用脚本进行替换配置,也可以手工修改,主要是配置etcd地址,这里主要做演示,就不搭建etcd集群了,如果搭建etcd集群可以参考coreos doc 构建etcd集群。 注意:这里的ip变量,因为我的地址是192网段, 所以我这里简单点直接grep 192来过滤。 配置etcd 启动 2.2 kube master 安装配置(kubem) 安装 k8s master 配置 master默认配置 配置k8s master 启动 2.3 kube minion 安装配置(minion1,minion2) 安装 k8s minion + docker(注意k8s 2个节点都需要同样配置) 配置 k8s minion配置文件 启动k8s minion + docker 到此我们k8s集群搭建完成了,我们可以使用如下命令在k8s master执行获取nodes信息: 2.4 使用工具quagga 配置容器间网络互通 从前面k8s集群搭建,你会看到网上搜索的k8s集群搭建容器网络互通大部分都基于flannel 来做,但这里我们使用quagga 来实现容器互通,使用quagga来做主要是觉得目前flannel通过端口转发方式实现容器互通,从性能上来看还不太理想,同时flannel本身还不够稳定,quagga的配置步奏如下: 安装brctl工具 删除默认的docker0 网卡,并创建新的网卡kbr0 配置kbr0 IP(我们写入一个配置文件到操作系统的网络配置目录) 这里注意:每个minion 节点配置不同的IPADDR,假设minion1 为172.11.11.1 ,则可以配置minion2为172.12.12.1,同时更改网关同步配置 更改docker默认参数配置,让docker默认使用kbr0网卡 重启network和docker 注意:如果重启network 没有加载kbr0,则需要重启操作系统 这里有网友直接将quagga 配置好并打包为docker image,我们直接拿来使用,我们也可以自行在宿主机上安装quagga 等待几秒钟,我们通过以下命令查看,可以看到route自动更新了。 注意:如果你执行命令route -n没有发现更新,你可以尝试stop 系统防火墙,再执行命令查看。 三、kube-ui 安装 kubernetes 自带了一个kube-ui,用来展示kubernetes 集群状态,目前kube-ui 还比较简单,只展现了kube 节点资源使用率,rc,service,pod ,nodes 情况,默认情况下安装kubernetes 集群是没有安装kube-ui的,需要我们手工安装。 注意:在安装kube-ui 之前,你需要把kube master服务器与其他kube minon 容器大二层网络互通,直接办法就是前面讲到的使用工具quagga 配置容器间网络互通这一节的流程在kube master 服务器上执行一次,可以在kube master上配置一个网卡kbr0 ,网络配置也跟其他minion节点容器网络相同域,让kube master 也能访问到kube minion 容器网络,否则kube-ui 安装好后会报无法访问minion pod地址。 安装配置准备工作 kube-ui的docker image是在google gcr中,由于众所周知的原因,我们在国内无法访问到这个源,这里我将源下载下来放到百度云盘中,我们可以将此image 下载下来后通过docker load 命令进行导入到kube minion或者私有仓库中。 kube-ui image 国内源 同时我们要用到3个文件 分别是kube-ui rc ,svc,kube-system,这3个文件,rc和service 在kubernetes 安装包kubernetes\cluster\addons\kube-ui路径下,你可以从github下载kubernetes 获取这2个文件,kube-system 文件需要你自己定义构建,由于kubernetes 完整安装包非常大,我这里直接将这3个文件内容展示,你可以直接复制内容命名一个文件名称使用kubectl create -f 进行创建,同时这里我将kubernetes 1.1版本直接搬到了百度云上,有需要可以下载: kuberntes 1.1版本 国内下载地址 下面是kube-ui rc,svc 和kube-system 内容,创建的顺序是kube-system-->kube-ui-rc-->kube-ui-svc。 kube-system.yaml kube-ui-rc.yaml kube-ui-svc.yaml 安装配置过程 前面的准备工作准备好以后,kube-ui的安装配置非常简单,总结为下面几步 (1)执行创建kube-system (2)创建kube-ui-rc 这里再提醒一下,一定要记得把kube-ui 镜像导入到kube minion 中,否则由于无法访问gcr的源,会一直卡在这里无法running 成功,同时注意由于我们的kube-ui 是创建在kube-system namespace 中的,所有我们查找rc,pod 都需要带关键字 --namespace=kube-system 或--all-namespace。 (3)创建kube-ui-svc (4)访问http://kube-master地址:8080/ui 可以看到我们kube-ui界面 四、总结 前面的配置,基本绕过了网上的一些构建k8s集群不完整文档的坑,主要有如下几个坑。 1. 2. 五、参考文章 高可用及自动发现的Docker基础架构 CentOS 7实战Kubernetes部署 kubernetes 官方doc 作者介绍 王佩 新炬网络云计算高级工程师 目前主要研究Docker相关的云计算技术 本文来自云栖社区合作伙伴"DBAplus",原文发布时间:2016-04-08




)