hbase 学习(十三)集群间备份原理
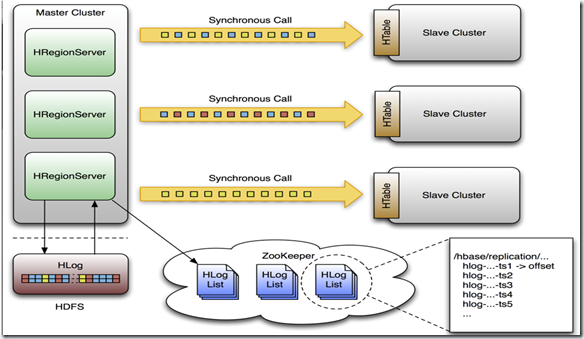
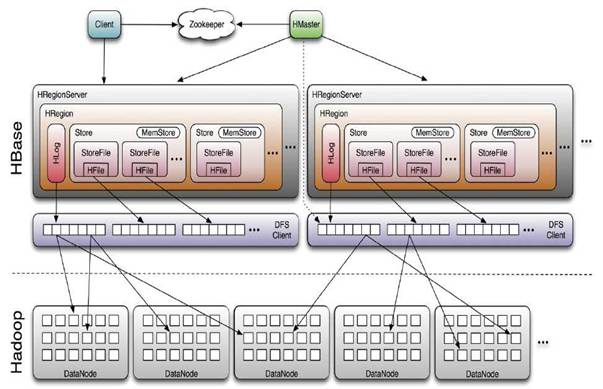
集群建备份,它是master/slaves结构式的备份,由master推送,这样更容易跟踪现在备份到哪里了,况且region server是都有自己的WAL 和HLog日志,它就像mysql的主从备份结构一样,只有一个日志来跟踪。一个master集群可以向多个slave集群推送,收到推送的集群会覆盖它本地的edits日志。 这个备份操作是异步的,这意味着,有时候他们的连接可能是断开的,master的变化不会马上反应到slave当中。备份个格式在设计上是和mysql的statement-based replication是一样的,全部的WALEdits(多种来自Delete和Put的Cell单元)为了保持原子性,会一次性提交。 HLogs是region server备份的基础,当他们要进行备份时必须保存在hdfs上,每个region server从它需要的最老的日志开始进行备份,并且把当前的指针保存在zookeeper当中来简化错误恢复,这个位置对于每一个slave 集群是不同的,但是对于同一个队列的HLogs是相同的。 下面这个是设计的结构图: 下面我们了解一下master和一个slave节点的整个过程。 1)当客户端通过api发送Put、Delete或者ICV到region server,这些KeyValue被转换成WALEdit,这个过程会被replication检测到,每一个设置了replication的列族,会把scope添加到edit的日志,然后追加到WAL中,并被应用到MemStore中。 2)在另一个线程当中,edit被从log当中读取来,并且只有可以备份的KeyValues(列族为scoped为GLOBAL的,并且不是catalog,catalog指的是.META. 和 -ROOT-) 3-1)这个edit然后被打上master群集的UUID,当buffer写满的时候或者读完文件,buffer会发到slave集群的随机的一个region server同步的,收到他们的region server把edit分开,一个表一个buffer,当所有的edits被读完之后,每一个buffer会通过HTable来flush,edits里面的master集群的UUID被应用到了备份节点,以此可以进行循环备份。 4-1)回到master的region server上,当前WAL的位移offset已经被注册到了zookeeper上面。 3-2)这里面,如果slave的region server没有响应,master的region server会停止等待,并且重试,如果目标的region server还是不可用,它会重新选择别的slave的region server去发送那些buffer。 同时WALs会被回滚,并且保存一个队列在zookeeper当中,那些被region server存档的Logs会更新他们在复制线程中的内存中的queue的地址。 4-2)当目标集群可用了,master的region server会复制积压的日志。 下面是一些具体的操作: 假设zookeeper当中的节点是/hbase/replication ,它会有三个子节点。 /hbase/replication/state /hbase/replication/peers /hbase/replication/rs The State znode state节点是记录是否可以进行备份的,它里面记录这个一个boolean值,true或者false,它是由hbase.replication决定的,同事它会在ReplicationZookeeper当中缓存,它还会因为在shell中执行了stop_replication而改变。 /hbase/replication/state [VALUE: true] The Peers znode 这个节点下面记录着所有需要备份的集群和他们当前的备份状态,如下: /hbase/replication/peers /1 [Value: zk1.host.com,zk2.host.com,zk3.host.com:2181:/hbase] /2 [Value: zk5.host.com,zk6.host.com,zk7.host.com:2181:/hbase]peer的id是自己在add_peer时候,自己提供的,后面的value是slave集群所使用的zookeeper集群,最后是所在的znode的父节点。 在每一个peer节点的下面还有一个表示状态的节点: /hbase/replication/peers /1/peer-state [Value: ENABLED] /2/peer-state [Value: DISABLED] The RS znode rs的节点下面包括了复制的region server以及需求复制的HLog的队列,看图就知道啦! 第一层节点记录着region server的机器名,端口号以及start code。 /hbase/replication/rs /hostname.example.org,6020,1234 /hostname2.example.org,6020,2856 下一层是需求复制的HLog的队列: /hbase/replication/rs /hostname.example.org,6020,1234 /1 /2 队列里面需要复制的HLog,值是已经被复制的最新的位置position。 /hbase/replication/rs /hostname.example.org,6020,1234 /1 23522342.23422 [VALUE: 254] 12340993.22342 [VALUE: 0]过程是上述的过程,下面展开讲一下具体的细节。 1)选择哪个region server去复制 当master节点准备好备份之后,它首先要通过slave集群的zookeeper,然后查看他们的rs的节点下面有多少可用的rs,然后随机选择他们中的一部分,默认是10%,如果有150个机器的话,会选择15个机器去发送。这个时候是有一个watcher在监视着slave集群的rs下面的变化,如果节点发生了变化,它会通知master节点的region server重发。 2)错误恢复,直接来个实际的例子 一个有3个region server集群正在和一个peer id为2的集群进行备份,每个region server下面都有一个队列 队列中的每个znode都是hdfs上的真实的文件名,“地址,端口.时间戳”。 /hbase/replication/rs/ 1.1.1.1,60020,123456780/ 2/ 1.1.1.1,60020.1234 (Contains a position) 1.1.1.1,60020.1265 1.1.1.2,60020,123456790/ 2/ 1.1.1.2,60020.1214 (Contains a position) 1.1.1.2,60020.1248 1.1.1.2,60020.1312 1.1.1.3,60020, 123456630/ 2/ 1.1.1.3,60020.1280 (Contains a position) 现在让1.1.1.2的zookeeper丢失session,观察者会创建一个lock,这个时候1.1.1.3完成了,它会把1.1.1.2的给接手过来,在自己的znode下面创建一个新的znode,并且加上dead的server的名称,就像下面这样子,原来的1.1.1.2的下面多了一层lock,1.1.1.3下面多了一个,和它原始的状态也不一样,前面多了个2。 /hbase/replication/rs/ 1.1.1.1,60020,123456780/ 2/ 1.1.1.1,60020.1234 (Contains a position) 1.1.1.1,60020.1265 1.1.1.2,60020,123456790/ lock 2/ 1.1.1.2,60020.1214 (Contains a position) 1.1.1.2,60020.1248 1.1.1.2,60020.1312 1.1.1.3,60020,123456630/ 2/ 1.1.1.3,60020.1280 (Contains a position) 2-1.1.1.2,60020,123456790/ 1.1.1.2,60020.1214 (Contains a position) 1.1.1.2,60020.1248 1.1.1.2,60020.1312然后1.1.1.3又自己倒腾了一会儿,假设它也挂了,最后的形态会是这样 1.1.1.1把1.1.1.3的未完成事业给接过了过来,所以我们看到1.1.1.1下面有个三手货和几个二手货。。。 /hbase/replication/rs/ 1.1.1.1,60020,123456780/ 2/ 1.1.1.1,60020.1378 (Contains a position) 2-1.1.1.3,60020,123456630/ 1.1.1.3,60020.1325 (Contains a position) 1.1.1.3,60020.1401 2-1.1.1.2,60020,123456790-1.1.1.3,60020,123456630/ 1.1.1.2,60020.1312 (Contains a position) 1.1.1.3,60020,123456630/ lock 2/ 1.1.1.3,60020.1325 (Contains a position) 1.1.1.3,60020.1401 2-1.1.1.2,60020,123456790/ 1.1.1.2,60020.1312 (Contains a position)原理说完了,从下面说说进行这个备份操作是哪些要求吧 (1)hbase的大的版本要一致 0.90.1 可以向0.90.0推送但是0.90.1不可以向0.89.20100725推送 (2)独立部署的zookeeper集群 (3)集群间的备份的表名和列族都要一致 (4)多个slave集群的话,要0.92以上版本 (5)集群间可以互相访问 (6)集群间的zookeeper.znode.parent不能相同 要使用这个集群建备份的功能需要先进行以下的设置: 1、修改hbase-site.xml文件 <property> <name>hbase.replication</name> <value>true</value> </property> 2、add_peer 输入这个命令,查看它的具体用法,然后添加 3、修改表的REPLICATION_SCOPE disable 'your_table' alter 'your_table', {NAME => 'family_name', REPLICATION_SCOPE => '1'} enable 'your_table' 4、list_peers 查看一下状态 5、备份完成之后如何进行数据校验,VerifyReplication就是专门来处理这个校验的。我们需要提供peer的id还有表名,verifyrep是它的简称,要用hadoop jar来运行。 集群之间备份的网址,说明他们是怎么工作的: http://hbase.apache.org/replication.html