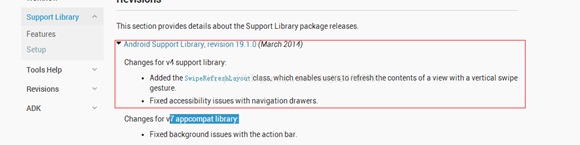
Android -- 官方下拉刷新SwipeRefreshLayout
V4的兼容包 API 大概就这4个常用的方法。 code 布局 <RelativeLayout xmlns:android="http://schemas.android.com/apk/res/android" xmlns:tools="http://schemas.android.com/tools" android:layout_width="match_parent" android:layout_height="match_parent" tools:context=".MainActivity" > <android.support.v4.widget.SwipeRefreshLayout android:id="@+id/swipe" android:layout_width="match_parent" android:layout_height="match_parent" > <ListView android:id="@+id/listview" android:layout_width="fill_parent" android:layout_height="wrap_content" /> </android.support.v4.widget.SwipeRefreshLayout> </RelativeLayout> MainActivty @Override protected void onCreate(Bundle savedInstanceState) { super.onCreate(savedInstanceState); setContentView(R.layout.activity_main); listView = (ListView) findViewById(R.id.listview); mSwipeLayout = (SwipeRefreshLayout) findViewById(R.id.swipe); list = new ArrayList<MyTextClass>(); Map<String, String> maps = new HashMap<String, String>(); maps.put("1", "2"); myHandler = new MyHandler(); client = new MyHttpClient(myHandler); myThread = new MyThread(client,"http://192.168.1.4/json/index.php",maps,GETJSON); myHandler.setThread(myThread); myHandler.setHandlerExtraHandleMessage(new MyHandler.HandlerExtraHandleMessage() { @Override public void handleMessage(Message msg) { switch (msg.what) { case GETJSON: String strJson1 = (String) msg.obj; Json json1 = new Json(strJson1); try { list = json1.getMyTextClass(); } catch (JSONException e) { e.printStackTrace(); } myBaseAdapter = new MyBaseAdapter(MainActivity.this, list); listView.setAdapter(myBaseAdapter); break; case REFRESH: String strJson2 = (String) msg.obj; Json json2 = new Json(strJson2); //list.clear(); try { list = json2.getMyTextClass(); } catch (JSONException e) { e.printStackTrace(); } if(myBaseAdapter != null) { myBaseAdapter.setList(list); myBaseAdapter.notifyDataSetChanged(); } else { MyBaseAdapter myBaseAdapter2 = new MyBaseAdapter(MainActivity.this, list); listView.setAdapter(myBaseAdapter2); } mSwipeLayout.setRefreshing(false); break; default: System.out.println("Other Message"); break; } super.handleMessage(msg); } }); Map<String, String> maps2 = new HashMap<String, String>(); maps.put("1", "2"); MyRefreshListener myRefreshListener = new MyRefreshListener(myHandler, maps2, REFRESH); mSwipeLayout.setOnRefreshListener(myRefreshListener); mSwipeLayout.setColorScheme(android.R.color.holo_green_dark, android.R.color.holo_green_light, android.R.color.holo_orange_light, android.R.color.holo_red_light); } 我是天王盖地虎的分割线 本文转自我爱物联网博客园博客,原文链接:http://www.cnblogs.com/yydcdut/p/3922845.html,如需转载请自行联系原作者