Facebook 将对 React 的优化实现到了浏览器!
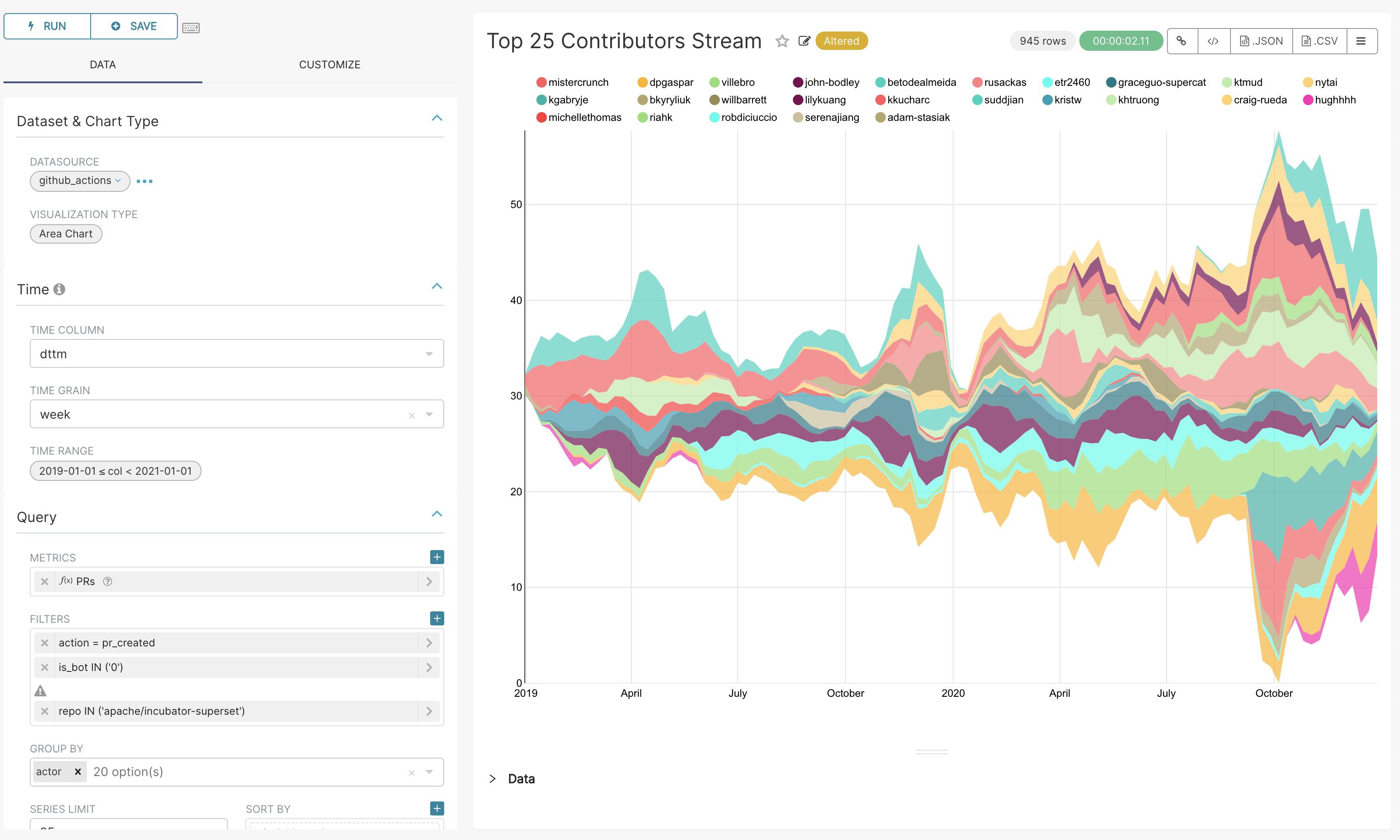
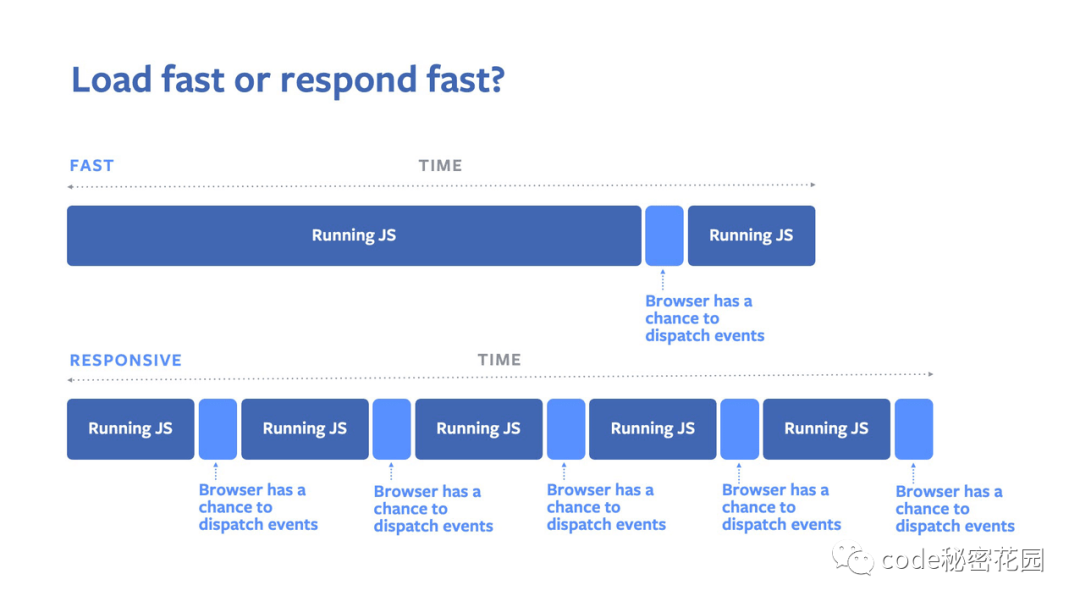
点上方蓝字关注公众号「前端从进阶到入院」 精选原创好文、进阶交流群助你进入大厂 想要提高一个网页的加载速度是非常困难的,如果你的网站是在使用 JavaScript 渲染的内容,你必须要在网页的加载速度和网页的输入响应能力之间作出权衡: 一次性执行首屏需要执行的逻辑(负载性能好,输入响应能力差) 将复杂的逻辑拆分成更小块的任务执行,以保证对外界输入的响应(负载性能差,输入响应能力好) 为了避免这种取舍,Facebook 在 Chromium 中提出并实现了 isInputPending() API,它可以提高网页的响应能力,但是不会对性能造成太大影响。 目前 isInputPending API 仅在 Chromium 的 87 版本开始提供,其他浏览器并未实现。 背景 在现今的 JavaScript 生态中,大多数工作都是在一个线程完成的:主线程。这种设计为开发者提供了一个健壮的执行模型,但是如果脚本执行的时间太长,则用户体验(尤其是响应能力)可能会遭受严重损失。例如,用户正在输入一些内容时, JavaScript 正在执行大量的逻辑,则在这些逻辑完成之前,浏览器都不能处理用户的输入事件。 现在的最佳实践是通过将复杂的逻辑拆分成更小块的任务执行来解决这种问题。在页面加载期间,页面可以运行一些 JavaScript 逻辑,然后将控制权转交给浏览器,这时浏览器可以检测自己的事件队列,看看是不是需要响应用户输入,然后再继续运行 JavaScript ,这种方式虽然会有一些帮助,但是同时也可能会带来其他问题。 每次页面将控制权交还给浏览器时,浏览器都会花费一些时间来检查它的事件队列,处理完事件后再获取下一个 JavaScript 代码逻辑。当浏览器更快地响应事件时,页面的整体加载时间会变慢。而且,用户输交互比较多的情况下,页面加载会非常慢。如果我们不那么频繁地进行上面的过程,那么浏览器响应用户事件所花费的时间就会更长。 Facebook 提出的 isInputPending API 是第一个将中断的概念用于浏览器用户交互的的功能,并且允许 JavaScript 能够检查事件队列而不会将控制权交于浏览器。 下面我们来具体看一个例子。 一个例子 假设您需要做很多显示阻塞的工作来加载页面,例如,从组件生成标记,分解质数或仅绘制一个很酷的加载微调器。这些中的每一个都分解为一个离散的工作项。使用调度程序模式,让我们勾勒出如何在假设的processWorkQueue()函数中处理我们的工作: 假设你再首屏加载页面时要处理非常多的阻塞逻辑,例如从组件生成标记,分解质数,或者只是绘制一个很酷的加载器动画。这些逻辑都会被分解成一个独立的工作项。使用 scheduler 模式,让我们在一个假设的 processWorkQueue() 函数中处理我们的逻辑: constDEADLINE=performance.now()+QUANTUM;while(workQueue.length>0){if(performance.now()>=DEADLINE){//Yieldtheeventloopifwe'reoutoftime.setTimeout(processWorkQueue);return;}letjob=workQueue.shift();job.execute();} 通过 processWorkQueue() 延时链式调用 setTimeout(),我们使浏览器能够在某种程度上保持对输入的响应,同时仍然在相对不间断地运行。但是,可能需要很长时间才能完成其他需要控制事件循环的工作,或者使 QUANTUM 事件延迟增加一毫秒。 在RAIL模型下,QUANTUM 一个好的值是<50ms,这取决于要完成的工作类型。该值主要决定了处理能力和延迟之间的平衡。 但是,我们还可以做的更好: constDEADLINE=performance.now()+QUANTUM;while(workQueue.length>0){if(navigator.scheduling.isInputPending()||performance.now()>=DEADLINE){//Yieldifwehavetohandleaninputevent,orwe'reoutoftime.setTimeout(processWorkQueue);return;}letjob=workQueue.shift();job.execute();} 通过调用 navigator.scheduling.isInputPending(),我们可以更快地响应输入,同时仍然确保我们的阻塞逻辑能够不间断地执行。如果在完成这些逻辑之前对用户交互(例如绘画)以外的其他操作不感兴趣,则可以方便地增加输入的长度 QUANTUM。 默认情况下,“连续”的事件类型不会返回 isInputPending(),比如 mousemove,pointermove 等等。如果你对这些也感兴趣的话,没问题。可以通过为 isInputPending() 提供一个包含连续变量为true的字典: constDEADLINE=performance.now()+QUANTUM;constoptions={includeContinuous:true};while(workQueue.length>0){if(navigator.scheduling.isInputPending(options)||performance.now()>=DEADLINE){//Yieldifwehavetohandleaninputevent(anyofthem!),orwe'reoutoftime.setTimeout(processWorkQueue);return;}letjob=workQueue.shift();job.execute();} 像 React 这样的框架正在将 isInputPending() 使用类似的逻辑构建到其核心调度库中。希望这将使使用这些框架的开发人员能够从幕后的 isInputPending() 中受益,而不要进行重大的重写。 React Fiber 让我们回想下 React Fiber 中的时间分片: 把一个耗时长的任务分成很多小片,每一个小片的运行时间很短,虽然总时间依然很长,但是在每个小片执行完之后,都给其他任务一个执行的机会,这样唯一的线程就不会被独占,其他任务依然有运行的机会。 React Fiber 把更新过程碎片化,执行过程如下面的图所示,每执行完一段更新过程,就把控制权交还给 React 负责任务协调的模块,看看有没有其他紧急任务要做,如果没有就继续去更新,如果有紧急任务,那就去做紧急任务。 如果你对该库感兴趣,可以到 https://github.com/WICG/is-input-pending 参与反馈和讨论。 参考:https://web.dev/isinputpending/ 不得不说 React 团队还是非常强的,一个 JavaScript 库能带动浏览器的发展。虽然这还是第一个由 Facebook 贡献给浏览器的能力,不过未来可期,让我们期待更多更强大的 API 吧! 1.关注「前端从进阶到入院」,获取我分类整理的原创精选面试热点文章。 2. 加我好友,拉你进氛围贼好的前端进阶讨论群,2021 陪你一起度过。 分享给你的朋友是最好的支持~ 本文分享自微信公众号 - 前端从进阶到入院(code_with_love)。如有侵权,请联系 support@oschina.cn 删除。本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。