web开发模式
Model1 显示层,控制层,数据层,统一交给jsp或者javabean处理. 处理流程 客户端发送request 到 jsp jsp 执行javabean javabean读取databases 返回 databases 返回给javabean 在返回给jsp 在response 给客户端 问题 代码杂乱即 jsp + dao 方式 model - view - controller 客户端发送request 到servlet 然后servlet 执行javabean javabean用于读取databases 控制器,获取到javabean读取的数据以后,再次返回给jsp,jso生成html文件,response 给客户端分为 显示层 控制层 模型层 EJB 属于SUN提供的分布式组件服务 分为会话bean 实体bean 消息驱动bean 实栗 一个登录程序用户提交登录信息,发送给servlet servlet数据验证失败将会返回给登录页,同时servlet将会调用数据层操作dao,dao到数据库databases进行验证,结果返回给servlet 然后返回两个结果,登录成功,登录失败. 代码如下 创建数据库 no 列名称 描述 1 userid 保存用户的登录id 2 name 用户真实姓名 3 password 用户密码 目录结构如下 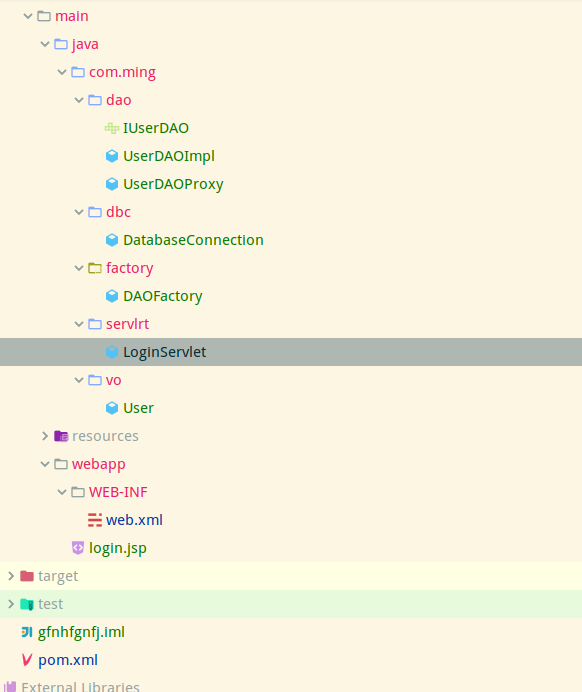 jdbc层 package com.ming.dbc; import java.sql.Connection; import java.sql.DriverManager; public class DatabaseConnection { private static final String DBDRIVER = "com.mysql.cj.jdbc.Driver"; private static final String DBURL = "jdbc:mysql://47.94.95.84:32786/test"; private static final String DBUSER = "test"; private static final String DBPASSWORD = "ABCcba20170607"; private Connection connection = null; // 连接数据库 public DatabaseConnection() throws Exception{ try{ Class.forName(DBDRIVER); connection = DriverManager.getConnection(DBURL, DBUSER, DBPASSWORD); }catch (Exception e){ throw e; } } // 获得数据库连接 public Connection getConnection(){ return this.connection; } // 数据库关闭 public void close() throws Exception{ if(this.connection != null){ try{ this.connection.close(); }catch (Exception e){ throw e; } } } } dao层 定义接口 package com.ming.dao; import com.ming.vo.User; public interface IUserDAO { /** * 用户登录验证 * @param user 传入VO对象 * @return 验证操作结果 * @throws Exception 抛出错误 */ public boolean findLogin(User user) throws Exception; } 实现类 package com.ming.dao; import com.ming.vo.User; import java.sql.Connection; import java.sql.PreparedStatement; import java.sql.ResultSet; public class UserDAOImpl implements IUserDAO { // 数据库连接对象 private Connection connection = null; // 操作对象 private PreparedStatement preparedStatement = null; // 数据库连接 public UserDAOImpl(Connection _connection){ this.connection = _connection; } /** * 用户登录验证 * * @param user 传入VO对象 * @return 验证操作结果 * @throws Exception 抛出错误 */ @Override public boolean findLogin(User user) throws Exception { boolean flag = false; try{ String sql = "SELECT name FROM user WHERE userid = ? AND password = ?"; // 获得实例化对象 this.preparedStatement = this.connection.prepareStatement(sql); // 设置id this.preparedStatement.setString(1, user.getUserid()); this.preparedStatement.setString(2, user.getPassword()); ResultSet resultset = this.preparedStatement.executeQuery(); if(resultset.next()){ user.setName(resultset.getString(1)); flag = true; } }catch (Exception e){ throw e; }finally { if(this.preparedStatement != null){ try{ this.preparedStatement.close(); }catch (Exception e){ throw e; } } } return flag; } } 代理类 package com.ming.dao; import com.ming.dbc.DatabaseConnection; import com.ming.vo.User; public class UserDAOProxy implements IUserDAO { private DatabaseConnection databaseConnection = null; private IUserDAO dao = null; public UserDAOProxy(){ try{ this.databaseConnection = new DatabaseConnection(); }catch (Exception e){ e.printStackTrace(); } this.dao = new UserDAOImpl(this.databaseConnection.getConnection()); } /** * 用户登录验证 * * @param user 传入VO对象 * @return 验证操作结果 * @throws Exception 抛出错误 */ @Override public boolean findLogin(User user) throws Exception { boolean flag = false; try{ flag = this.dao.findLogin(user); }catch (Exception e){ throw e; }finally { this.databaseConnection.close(); } return flag; } } 定义代理工厂 package com.ming.factory; import com.ming.dao.IUserDAO; import com.ming.dao.UserDAOProxy; public class DAOFactory { public static IUserDAO getIuserDAOInstance(){ return new UserDAOProxy(); } } 实体关系映射 package com.ming.vo; // 对user表进行映射 public class User { private String userid; private String name; private String password; public String getUserid() { return userid; } public String getName() { return name; } public String getPassword() { return password; } public void setUserid(String userid) { this.userid = userid; } public void setName(String name) { this.name = name; } public void setPassword(String password) { this.password = password; } } 视图层 <%@ page import="java.util.List" %> <%@ page import="java.util.Iterator" %><%-- Created by IntelliJ IDEA. User: ming Date: 19-3-16 Time: 下午11:07 To change this template use File | Settings | File Templates. --%> <%@ page contentType="text/html;charset=UTF-8" language="java" %> <html> <head> <title>Title</title> </head> <body> <h2>用户登录程序</h2> <% List<String> info = (List<String>)request.getAttribute("info"); if(info != null){ Iterator<String> iterator = info.iterator(); while(iterator.hasNext()){ %> <h4><%=iterator.next()%></h4> <% } } %> <form action="loginServlet" method="post"> 用户id <input type="text" name="userid" id="uname"/> 密码 <input type="password" name="userpass" id="password"/> <input type="submit" value="登录" id="submit"/> <input type="reset" value="重置"/> </form> <script> let submit = document.getElementById("submit"); submit.onclick = (event) => { let uname = document.getElementById("uname").value; let password = document.getElementById("password").value; if(!(/^\w{5,15}/.test(uname))){ alert("用户id为5-15位"); return false; } if(!(/^\w{5,15}/.test(password))){ alert("密码必须为5-15位"); return false; } return true; } </script> </body> </html> 配置文件 <!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd" > <web-app> <display-name>Archetype Created Web Application</display-name> <servlet> <servlet-name>login</servlet-name> <servlet-class>com.ming.servlrt.LoginServlet</servlet-class> </servlet> <servlet-mapping> <servlet-name>login</servlet-name> <url-pattern>/loginServlet</url-pattern> </servlet-mapping> </web-app> mvc运行流程 表单提交到servlet,servlet调用dao进行表单验证,然后dao连接数据库进行验证,验证结果返回给业务层,即servlet,在业务层servlet中获取info等日志信息,然后服务器端跳转到运行结果页面即view层.