MapReduce中map并行度优化及源码分析
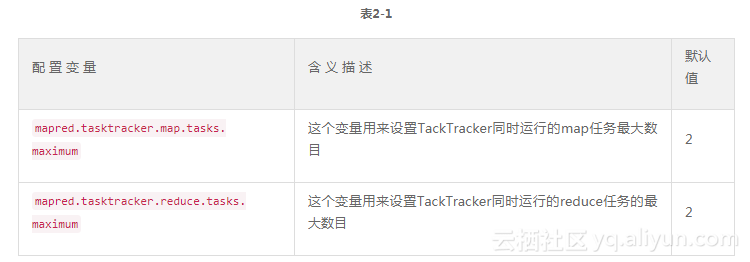
mapTask并行度的决定机制 一个job的map阶段并行度由客户端在提交job时决定,而客户端对map阶段并行度的规划的基本逻辑为:将待处理数据执行逻辑切片(即按照一个特定切片大小,将待处理数据划分成逻辑上的多个split),然后每一个split分配一个mapTask并行实例处理。 FileInputFormat切片机制 原文和作者一起讨论:http://www.cnblogs.com/intsmaze/p/6733968.html 1、默认切片定义在InputFormat类中的getSplit()方法 2、FileInputFormat中默认的切片机制: a)简单地按照文件的内容长度进行切片 b)切片大小,默认等于hdfs的block大小 c)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片 比如待处理数据有两个文件: file1.txt 260M file2.txt 10M 经过FileInputFormat的切片机制运算后,形成的切片信息如下: file1.txt.split1-- 0~128 file1.txt.split2-- 128~260 //如果剩余的文件长度/切片长度<=1.1则会将剩余文件的长度并未一个切片 file2.txt.split1-- 0~10M 3、FileInputFormat中切片的大小的参数配置 通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize, Math.min(maxSize, blockSize)); 切片主要由这几个值来运算决定。 minsize:默认值:1 配置参数: mapreduce.input.fileinputformat.split.minsize maxsize:默认值:Long.MAXValue 配置参数:mapreduce.input.fileinputformat.split.maxsize blocksize:值为hdfs的对应文件的blocksize配置读取目录下文件数量的线程数:public static final String LIST_STATUS_NUM_THREADS = "mapreduce.input.fileinputformat.list-status.num-threads"; 因此,默认情况下,Math.max(minSize,Math.min(maxSize,blockSize));切片大小=blocksize maxsize(切片最大值):参数如果调得比blocksize小,则会让切片变小。 minsize(切片最小值):参数调的比blockSize大,则可以让切片变得比blocksize还大。 选择并发数的影响因素: 1、运算节点的硬件配置 2、运算任务的类型:CPU密集型还是IO密集型 3、运算任务的数据量 3、hadoop2.6.4源码解析 org.apache.hadoop.mapreduce.JobSubmitter类 //得到job的map任务的并行数量 private int writeSplits(org.apache.hadoop.mapreduce.JobContext job, Path jobSubmitDir) throws IOException, InterruptedException, ClassNotFoundException { JobConf jConf = (JobConf)job.getConfiguration(); int maps; if (jConf.getUseNewMapper()) { maps = writeNewSplits(job, jobSubmitDir); } else { maps = writeOldSplits(jConf, jobSubmitDir); } return maps; } @SuppressWarnings("unchecked") private <T extends InputSplit> int writeNewSplits(JobContext job, Path jobSubmitDir) throws IOException, InterruptedException, ClassNotFoundException { Configuration conf = job.getConfiguration(); InputFormat<?, ?> input = ReflectionUtils.newInstance(job.getInputFormatClass(), conf); List<InputSplit> splits = input.getSplits(job); T[] array = (T[]) splits.toArray(new InputSplit[splits.size()]); // sort the splits into order based on size, so that the biggest // go first Arrays.sort(array, new SplitComparator()); JobSplitWriter.createSplitFiles(jobSubmitDir, conf, jobSubmitDir.getFileSystem(conf), array); return array.length; } 切片计算逻辑,关注红色字体代码即可。 public List<InputSplit> getSplits(JobContext job) throws IOException { Stopwatch sw = new Stopwatch().start();long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); long maxSize = getMaxSplitSize(job); // generate splits List<InputSplit> splits = new ArrayList<InputSplit>(); List<FileStatus> files = listStatus(job); //遍历文件,对每一个文件进行如下处理:获得文件的blocksize,获取文件的长度,得到切片信息(spilt 文件路径,切片编号,偏移量范围) for (FileStatus file: files) { Path path = file.getPath(); long length = file.getLen(); if (length != 0) { BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { FileSystem fs = path.getFileSystem(job.getConfiguration()); blkLocations = fs.getFileBlockLocations(file, 0, length); } if (isSplitable(job, path)) { long blockSize = file.getBlockSize(); long splitSize = computeSplitSize(blockSize, minSize, maxSize); long bytesRemaining = length; while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); bytesRemaining -= splitSize; } if (bytesRemaining != 0) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); } } else { // not splitable splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(), blkLocations[0].getCachedHosts())); } } else { //Create empty hosts array for zero length files splits.add(makeSplit(path, 0, length, new String[0])); } } // Save the number of input files for metrics/loadgen job.getConfiguration().setLong(NUM_INPUT_FILES, files.size()); sw.stop(); if (LOG.isDebugEnabled()) { LOG.debug("Total # of splits generated by getSplits: " + splits.size() + ", TimeTaken: " + sw.elapsedMillis()); } return splits; } public static final String SPLIT_MINSIZE = "mapreduce.input.fileinputformat.split.minsize"; public static final String SPLIT_MAXSIZE = "mapreduce.input.fileinputformat.split.maxsize"; long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); //保证切分的文件长度最小不得小于1字节 protected long getFormatMinSplitSize() { return 1; } //如果没有在conf中设置SPLIT_MINSIZE参数,则取默认值1字节。 public static long getMinSplitSize(JobContext job) { return job.getConfiguration().getLong(SPLIT_MINSIZE, 1L); } //得到切片文件的最大长度 long maxSize = getMaxSplitSize(job); //如果没有在conf中设置SPLIT_MAXSIZE参数,则去默认值Long.MAX_VALUE字节。 public static long getMaxSplitSize(JobContext context) { return context.getConfiguration().getLong(SPLIT_MAXSIZE, Long.MAX_VALUE); } //读取指定目录下的所有文件的信息 List<FileStatus> files = listStatus(job); //如果没有指定开启几个线程读取,则默认一个线程去读文件信息,因为存在目录下有上亿个文件的情况,所以有需要开启多个线程加快读取。 int numThreads = job.getConfiguration().getInt(LIST_STATUS_NUM_THREADS, DEFAULT_LIST_STATUS_NUM_THREADS); public static final String LIST_STATUS_NUM_THREADS = "mapreduce.input.fileinputformat.list-status.num-threads"; public static final int DEFAULT_LIST_STATUS_NUM_THREADS = 1; //计算切片文件的逻辑大小 long splitSize = computeSplitSize(blockSize, minSize, maxSize); protected long computeSplitSize(long blockSize, long minSize, long maxSize) { return Math.max(minSize, Math.min(maxSize, blockSize)); } private static final double SPLIT_SLOP = 1.1; // 10% slop //判断剩余文件与切片大小的比是否为1.1. while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); bytesRemaining -= splitSize; } map并行度 如果job的每个map或者reduce的task的运行时间都只有30-40秒钟(最好每个map的执行时间最少不低于一分钟),那么就减少该job的map或者reduce数。每一个task的启动和加入到调度器中进行调度,这个中间的过程可能都要花费几秒钟,所以如果每个task都非常快就跑完了,就会在task的开始和结束的时候浪费太多的时间。 配置task的JVM重用可以改善该问题: (mapred.job.reuse.jvm.num.tasks,默认是1,表示一个JVM上最多可以顺序执行的task数目(属于同一个Job)是1。也就是说一个task启一个JVM)。 小文件的场景下,默认的切片机制会造成大量的maptask处理很少量的数据,效率低下: 解决方案: 推荐:把小文件存入hdfs之前进行预处理,先合并为大文件后再上传。 折中:写程序对hdfs上小文件进行合并再跑job处理。 补救措施:如果大量的小文件已经存在hdfs上了,使用combineInputFormate组件,它可以将众多的小文件从逻辑上规划到一个切片中,这样多个小文件就可以交给一个maptask操作了。 作者: intsmaze(刘洋) 出处: http://www.cnblogs.com/intsmaze/ 老铁,你的--->推荐,--->关注,--->评论--->是我继续写作的动力。 微信公众号号:Apache技术研究院 由于博主能力有限,文中可能存在描述不正确,欢迎指正、补充! 本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。