“ 3 个月 5980 ,你的品牌名上不了 DeepSeek ,你来找我,我们直接退钱! ”
“一个词 5980 吗?”
“对,如果你优化多个平台,会有梯度优惠,比如豆包、元宝、KIMI 。”
以上,是最近一个 GEO( Generative Engine Optimization 生成引擎优化)业务销售与朋友的聊天记录,大概情况是:朋友是做 MCN 的,需要在 DeepSeek 、豆包、元宝等国内 AI 平台上优化自己的品牌关键词(或业务关键词),然后一个自称 GEO 营销专家的销售嗅着味就过来了,其产品 PPT 营销味之冲,令人咋舌。
整理了一些关键表述,大家评估(不便直接截图,但是真人真事):
-
答案霸权战争开启,95% 传统 SEO 企业出局
-
未布局 GEO 企业搜索量暴跌 90%
-
GEO 成本≈传统 SEO 的 1/10
...
笔者理解在一些营销场域,确实需要拽狠词儿,但不解:一个 2023 年随 ChatGPT 大火后出现的技术方向,真的有如此大的能量?这不禁让笔者联想到 2022 年还有一篇文章提到:“随着 ChatGPT 取代谷歌搜索,传统的搜索引擎优化( SEO )正走向消亡...”
![]()
但事实上,SEO 并没死,诸如 GEO、LLMO 等优化概念,也随着这几年生成式 AI 技术的发展,与传统 SEO 形成互补、协作的态势。
闲言少叙,正片开始。
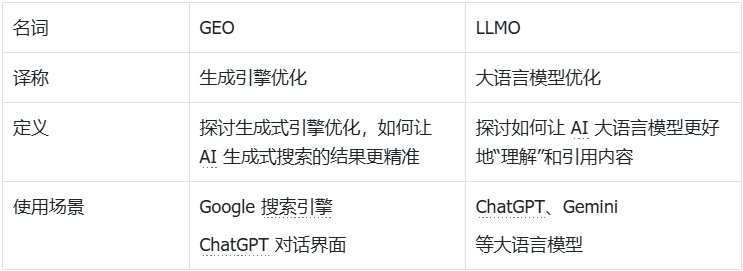
GEO、LLMO 是什么?二者有何联系?
严格来说,我们处于一个由人工智能技术,特别是生成式 AI ( Generative AI )深刻变革的时代。以大语言模型为核心的生成引擎,如 ChatGPT 、Gemini 、DeepSeek 、豆包、腾讯元宝等,正以前所未有的速度渗透到信息检索、内容创作、问题解答、决策辅助等各个环节。
而用户获取信息的行为也正发生转变:从过去习惯于在搜索引擎返回的“链接列表”中自行探索、筛选和整合信息,逐渐转向直接对 AI 提出问题,并期望获得一个经过 AI 理解、提炼、组织后的综合性、对话式答案。
以上是因,果则是:传统的 SEO 策略,虽仍有价值,但不足以完全应对这场由 AI 驱动的信息革命。2023 年 ,GEO(生成引擎优化)这一概念被提出,随之还有 LLMO(大语言模型优化)。
方便大家了解,笔者引用 @已见室 的解读,如下:
![]()
综合来看,二者不外乎解决一件事情:提升品牌及其内容在生成式 AI 回答中的可见度。但二者也有些许不同。
我们先聊 GEO 。GEO 全称 Generative Engine Optimization ,指通过优化网站内容,提升其在 AI 驱动的搜索引擎(国内如 Deepseek 、百度 AI 搜索、秘塔搜索,国外如 ChatGPT 、Perplexity 、Gemini 、Copilot 和 Google AI Overviews )中的可见度。
例如,当用户搜索与你的产品、服务或专业领域相关的内容时,GEO 能帮助你的品牌在 AI 生成结果中获得优先展示,从而实现精准触达,最终将访客转化为品牌的忠实用户,促使他们持续回访并深度互动。
故 GEO 多面向企业、品牌、内容创作者,以及营销人员。
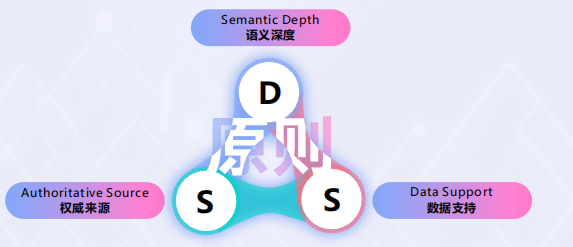
在上海源易信息发布的《GEO 营销新增长白皮书》一文提出,企业要系统性地构建能被生成式 AI 优先采信的内容,可以遵循 DSS 原则,即:语义深度、数据支持、权威来源。
-
语义深度:指内容在信息丰富度、分析透彻度、逻辑严谨性、上下文关联性和满足用户深度(而非表层)需求方面的程度。
-
数据支持:指内容中的观点、结论或陈述是否基于可验证的事实、可靠的数据、具体的案例或明确的证据。
-
权威来源:指内容本身的出处(发布平台或作者)是否具有公认的专业性、权威性和良好的声誉,关乎内容的可信背书和行业地位。
![]()
而 LLMO( Large Language Model Optimization ),则聚焦于模型自身的优化,涉及模型微调、模型压缩、优化推理效率、改进上下文学习能力等,以提高模型的准确率、响应速度或多模态处理能力。
例如:通过微调,让模型在金融行业场景下,更准确地分析财报;通过剪枝,让模型在面对一些低延时场景下,提升响应速度。
故 LLMO 多面向 AI 开发者、数据科学家或工程师。
![]()
那么,GEO 与 LLMO 之间有何关联呢?在搞懂这一点前,不妨看看 LLM 是如何影响单一品牌出现的,从机制上:
总结一下,大家可以将 LLMO 看作是为了“精准反馈用户所需要的内容”,大模型在“输出前”的自身机制优化,而 GEO 则为了优化 AI 生成结果的先后顺序,即:针对于生成式 AI 答案的“ SEO ”。二者相互协同,最终提升品牌在生成式 AI 回答中的可见度。
GEO 与 SEO 的关联与互补
笔者明确一个观点:GEO 并非完全摒弃 SEO ,GEO 建立在 SEO 基础之上,并对其核心理念进行了延展。
无论是 GEO 还是 SEO ,其核心目的都是对输出内容的先后顺序进行优化——不外乎 SEO 优化的是网站链接的先后顺序,而 GEO 优化的是 LLM 输出内容的先后顺序。
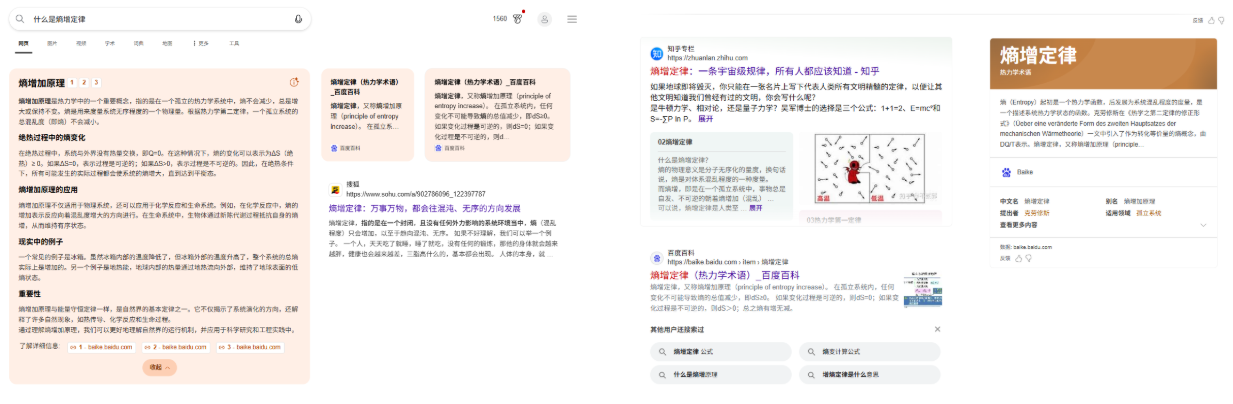
所以,我们在 AI 搜索引擎中看到的引用链接,常常也出现在搜索引擎结果页( SERP )的前列。
![]()
左图(GEO)所引用的“某度百科”,为右图(SEO)的第二位
而搜索引擎和生成式 AI 引擎的本质都是“响应用户需求”,因此 SEO 和 GEO 都需要先明确“用户想获取什么信息”,再反向优化策略。二者的本质都是“用户需求→信息匹配→优化策略”的闭环,只是“需求载体”不同,SEO 是“搜索关键词”,GEO 是“自然语言提问”。
且为了更好理解用户需求,搜索引擎和生成式 AI 引擎都依赖 NLP (自然语言处理),因此 GEO 和 SEO 在“语言优化”层面其实是相似的。
-
SEO 的 NLP 应用:搜索引擎通过 NLP 解析用户关键词的语义,例如“电脑卡怎么办”与“如何解决电脑卡顿”是同义需求,因此 SEO 还需要优化内容的“语义关联性”,并非单纯的关键词查询。
-
GEO 的 NLP 应用:生成式引擎的核心是理解用户的自然语言提问,例如“帮我推荐附近一家靠谱的火锅店”,GEO 不但需要负责推荐的排序,还得整合输出对应品牌的相关标签,以满足“靠谱”“附近”等词的语义解决。
![]()
至于 GEO 与传统 SEO 的互补,其实可以分为两个方面:
1、产品形态的角度
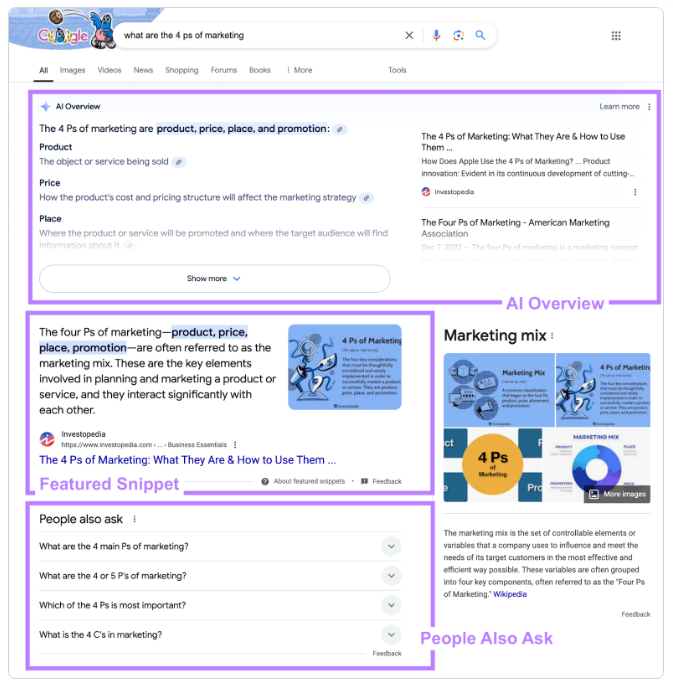
目前很多 AI 搜索引擎都会同时返回“ AI 输出整理”与“传统搜索引擎结果”,即:顶部显示 AI 生成式回答,下方序列显示相关网页链接。例如,在 Google 搜索“what are the 4 ps of marketing ”,会显示如下结果:
![]()
再拓展一下,例如某音这款大家常用的短视频 APP ,也推出了“ AI 搜一搜”这类功能,搜索的答案则不会直接反馈“关联词”的短视频,而是 AI 生成的答案。
![]()
可见,在实际使用场景中,输出内容背后所对应的优化逻辑( GEO/SEO ),目前仍是并行使用的。
2、爬虫协议的角度
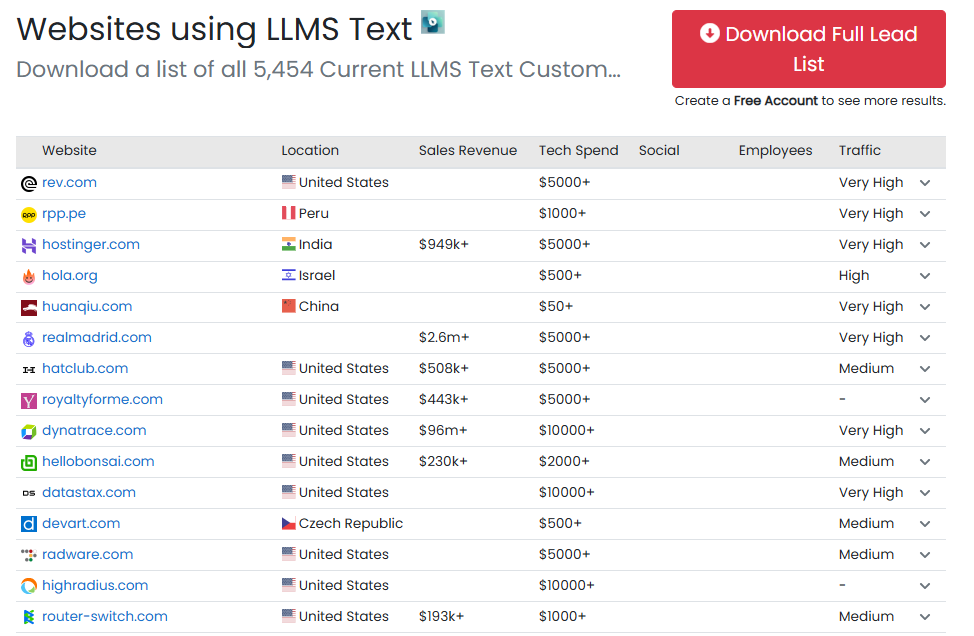
传统的 SEO ,是通过网络根目录下的 robot.txt 文件去抓取网络的内容、关键词,而现在的 GEO 依旧沿用了这一爬虫协议,并诞生了更契合大模型理解的 llms.txt 协议,通过提供网站的结构化 Markdown 文档,帮助 LLM 理解哪些内容重要,哪些内容不重要、可取舍,从而减少爬虫工具对网站的抓取负担。
目前,全球大概已有 5000+ 网站布局了 llms.txt ,以增强网站的机器可读。爬虫协议方面,robot.txt 、sitemap.xml 、llms.txt 呈现出并行支持的态势。
![]()
针对 GEO ,企业可以怎么做?
上文也提到,GEO 是为了让大模型更好抓取内容并理解,在“输入前”的一整套可操作的优化方案。那么“输入前”是哪个阶段呢?对于企业来说,无非是官网搭建、内容框架、分发渠道等,即:向 LLM 介绍“ who am I ”的阶段。
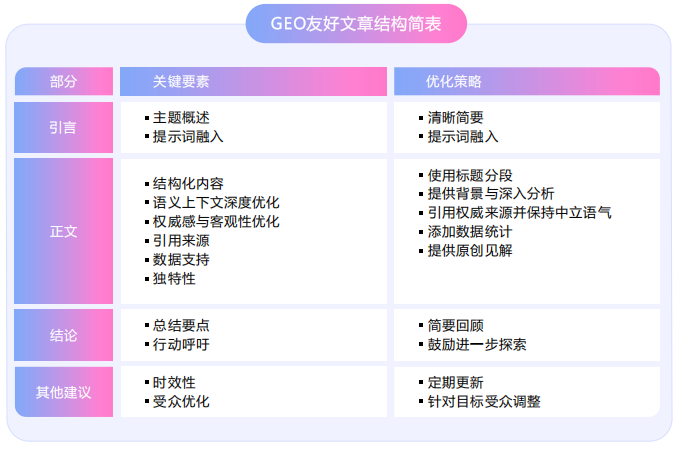
针对于提高企业相关内容的能见度,我们又该怎么做呢?结合上海源易信息的解决方案,笔者用大白话为大家整理如下——
内容层优化:
1、深度挖掘核心用户需求,打造具有标签性质的内容框架。例如,品牌可以通过用户调研、搜索数据分析等,建立品牌 FAQ 板块。这样不仅可以通过品牌官网解决大部分用户需求,也可以满足 LLM 信息抓取的结构化需要,毕竟在对话式 AI 语境下,大模型的输出也是一问一答。
2、提升语义深度。品牌在搭建内容框架时,需要提供尽可能全面的信息。例如:产品背景、技术参数、专业名词解释、针对痛点、恰当类比、解决方案,以及明确导向能给用户带来的独特价值。总而言之,品牌最好要有自己独特的内容框架,别抄模板,别写一些模棱两可的话。
3、强化数据支持。说白了,言之有理,言有出处。一方面,引用可信数据,例如来自于权威机构(政府、研究机构、行业协会)的最新数据、统计报告;另一方面,多使用图表、图像等形式让数据更直观易懂。
4、建立 LLM 受益的文档结构。即 Snowflake 的“全球文档”概念,指 LLM 通过将文本分解为“块”来工作,可以通过在整个文本中添加有关文档的额外信息(如财务文本的公司名称、提交日期),LLM 更容易理解并正确解释每个独立的块,从而提高回答准确率。
![]()
技术层优化:
1、夯实 SEO 基础(面向 AI 爬虫):首先确保网站没有阻止 AI 爬虫访问的技术障碍(如 robots.txt 或 llms.txt 设置不当)。其次做好跨端适配,确保在各种设备上都能良好显示和使用。最后使用 HTTPS 加密,搜索引擎更倾向于优先展示 HTTPS 网站。
2、结构化数据( Schema Markup )深度应用:Schema 标记是一种标准化的词汇表,可添加到网站 HTML 中,帮助搜索引擎和 AI 更精准地理解页面的含义和实体关系。基于此,Schema 标记直接向 AI 提供相关内容的“元数据”,降低 AI 理解内容的难度和歧义性,也提升了内容被准确解读和采信的可能性。
3、实体优化:是指内容和网站结构中清晰地定义和关联这些核心实体,帮助 AI 准确识别并理解它们。例如,在内容中一致地使用品牌、产品、人物、logo 等的标准名称,建立内部链接将相关实体页面连接起来;在权威第三方平台(如维基百科、行业数据库、知识图谱网站)上建立和完善品牌相关的实体信息。
4、建立“防御性 GEO ”机制:GEO 策略不仅要着眼于优化正面信息,更要建立常态化的品牌 AI 声誉监测体系。主动发现并追踪 AI 回答中关于品牌的潜在负面、不实或过时信息。一旦发现问题,可以通过发布和优化更权威、全面、可信的官方信息(如声明、FAQ 、事实核查文章)来“对冲”负面内容,争取让 AI 采信正面信息源。
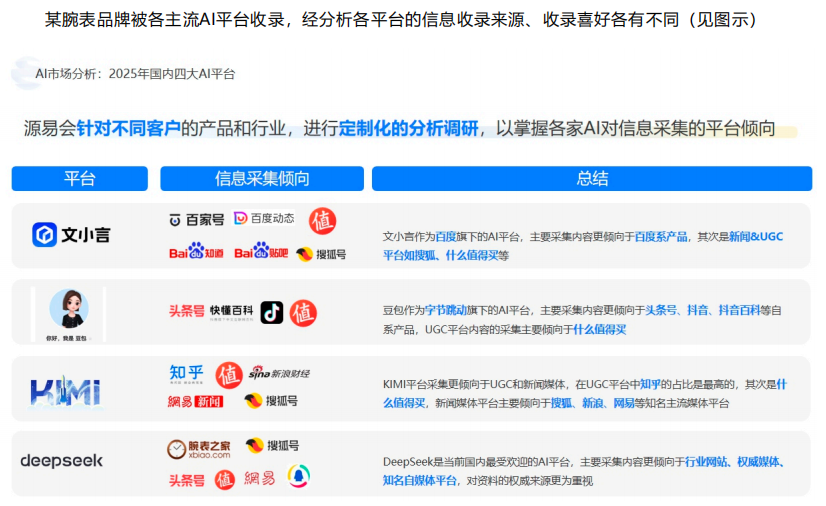
平台选择与分发策略:
我们得承认,即便内容质量再高,如果发布在 AI 不常访问或不信任的平台上,品牌被引用的效果也会大打折扣。
所以,企业可以优先在行业内公认的网站、知名媒体或高权重平台发表内容。其次,优先在 AI 索引的主流平台发布内容,满足 LLM 抓取习惯。最后,切忌随意更换品牌的官方表述、历史声誉等信息。(笔者还认为,在分发过程中,明确内容作者的专业背景、从业经验、相关认证等,通过关联作者信息的形式,也有利于品牌的索引曝光。)
![]()
图源:上海源易信息
目前的困难与挑战
总体来说,GEO 目前依旧是一个新兴的研究领域,自带历史局限性。例如,2022 年,GEO 刚被提出时,网上就出现了“如何确保优化后的内容准确可信”、“过度优化导致优质小众内容被淹没”的声音。
而在笔者咨询了一圈企业主之后,也得到了更多的负面声音:
-
除了需要支付 SEO 的费用,还要支付 GEO 的费用,徒增运营成本
-
如何防止竞争企业在 AI 平台上对品牌进行恶意抹黑
-
AI 生成内容对原创内容的引用、改编和合成,引发关于版权、知识产权归属的法律和伦理问题
-
那些跟模型厂商有合作,或者有关联的品牌,能否介入 LLM 的参数权重
类似还有很多,笔者就不展开了。我们不得不承认:原本在 SEO 时代下存在的,恶性竞价、优化转单等问题,依旧可能在 GEO 时代发生。除此之外,生成式 AI 内容优化还自带与 AI 深度结合下的发展挑战:
-
算法不透明、难以解释。目前,大模型的“黑箱”问题在短期内难以解决,但随着技术发展与市场监管的要求,生成引擎提供商可能会有限度地提高算法透明度,或提供更明确的内容指南,帮助创作者更好地进行优化;
-
网站的机器可读性低。在生成式 AI 深度介入内容生态后,“机器可读性” 的内涵已远超传统 SEO 中对 HTML 结构、标签规范的基础要求,而类似于 llms.txt 等标准,还未大范围推行;
-
数据偏见的固化与放大。生成式 AI 的优化能力高度依赖训练数据的质量,而历史数据中隐含的社会偏见(如性别刻板印象、地域认知偏差)会被模型学习并在优化过程中强化。这种偏见的 “代际传递” 难以通过简单的算法调整消除,因为它根植于数据反映的历史认知偏差。
-
GEO 还没有像 SEO 一样,走向体系化。SEO ,不仅有搜索引擎平台出的规范、教程以及适用范围,在业内同样有专业的从业资格认证,且诞生出了 SEO 优化师这一垂直岗位。反观 GEO ,就像笔者开篇所写,一个词优化就需要 6000 块,谁定的价?优化方案是?优化平台是?目前在很多方面仍不透明。
......
可见,让 AI 有效回答,并满足人类的实际需求,并不是一件简单的事情。但笔者还是认为:无论是 GEO ,还是 LLMO ,LLM 都可以拥有其自身的回答风格与范式,这也是目前绝大部分模型厂商的态度。至于商业品牌的曝光需求,不妨落在特定业务场景下的 AI Agent 中去解决,或许所生成的内容、提供的服务,更易被提问者接受。
参考资料:
1、上海源易信息《GEO 营销增长白皮书》
2、https://digitalzoo.com.hk/blog/seo%e5%b0%88%e9%a1%8c/geo-llmo-aeo-%e5%85%a8%e9%83%a8%e9%83%bd%e5%8f%aa%e6%98%afseo%e8%80%8c%e5%b7%b2/
3、https://mister-seo.com/llmo-gaio-geo/