Java并发编程笔记之Unsafe类和LockSupport类源码分析
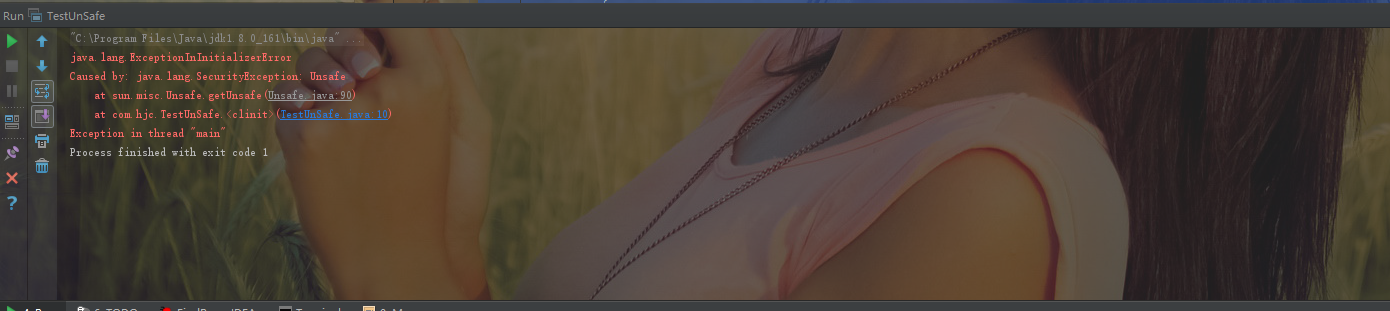
一.Unsafe类的源码分析 JDK的rt.jar包中的Unsafe类提供了硬件级别的原子操作,Unsafe里面的方法都是native方法,通过使用JNI的方式来访问本地C++实现库。 rt.jar 中 Unsafe 类主要函数讲解, Unsafe 类提供了硬件级别的原子操作,可以安全的直接操作内存变量,其在 JUC 源码中被广泛的使用,了解其原理为研究 JUC 源码奠定了基础。 首先我们先了解Unsafe类中主要方法的使用,如下: 1.long objectFieldOffset(Field field) 方法:返回指定的变量在所属类的内存偏移地址,偏移地址仅仅在该Unsafe函数中访问指定字段时使用。如下代码使用unsafe获取AtomicLong中变量value在AtomicLong对象中的内存偏移,代码如下: static { try { valueOffset = unsafe.objectFieldOffset(AtomicLong.class.getDeclaredField("value")); } catch (Exception ex) { throw new Error(ex); } } 2.int arrayBaseOffset(Class arrayClass)方法:获取数组中第一个元素的地址 3.int arrayIndexScale(Class arrayClass)方法:获取数组中单个元素占用的字节数 3.boolean compareAndSwapLong(Object obj,long offset,long expect,long update)方法:比较对象obj中偏移量offset的变量的值是不是和expect相等,相等则使用update值更新,然后返回true,否则返回false。 4.public native long getLongVolative(Object obj,long offset)方法:获取对象obj中偏移量offset的变量对应的volative内存语义的值。 5.void putOrderedLong(Object obj, long offset, long value) 方法:设置 obj 对象中 offset 偏移地址对应的 long 型 field 的值为 value。这是有延迟的 putLongVolatile 方法,并不保证值修改对其它线程立刻可见。变量只有使用 volatile 修饰并且期望被意外修改的时候使用才有用。 6.void park(boolean isAbsolute, long time) 方法:阻塞当前线程,其中参数 isAbsolute 等于 false 时候,time 等于 0 表示一直阻塞,time 大于 0 表示等待指定的 time 后阻塞线程会被唤醒,这个 time 是个相对值,是个增量值,也就是相对当前时间累加 time 后当前线程就会被唤醒。 如果 isAbsolute 等于 true,并且 time 大于 0 表示阻塞后到指定的时间点后会被唤醒,这里 time 是个绝对的时间,是某一个时间点换算为 ms 后的值。另外当其它线程调用了当前阻塞线程的 interrupt 方法中断了当前线程时候,当前线程也会返回,当其它线程调用了 unpark 方法并且把当前线程作为参数时候当前线程也会返回。 7.void unpark(Object thread)方法: 唤醒调用 park 后阻塞的线程,参数为需要唤醒的线程。 在JDK1.8中新增加了几个方法,这里简单的列出Long类型操作的方法如下: 8.long getAndSetLong(Object obj, long offset, long update) 方法: 获取对象 obj 中偏移量为 offset 的变量 volatile 语义的值,并设置变量 volatile 语义的值为 update。使用方法如下代码: public final long getAndSetLong(Object obj, long offset, long update) { long l; do { l = getLongVolatile(obj, offset);//(1) } while (!compareAndSwapLong(obj, offset, l, update)); return l; } 从代码中可以内部代码(1)处使用了getLongVolative获取当前变量的值,然后使用CAS原子操作进行设置新值,这里使用while循环是考虑到多个线程同时调用的情况CAS失败后需要自旋重试。 9.long getAndAddLong(Object obj, long offset, long addValue) 方法 :获取对象 obj 中偏移量为 offset 的变量 volatile 语义的值,并设置变量值为原始值 +addValue。使用方法如下代码: public final long getAndAddLong(Object obj, long offset, long addValue) { long l; do { l = getLongVolatile(obj, offset); } while (!compareAndSwapLong(obj, offset, l, l + addValue)); return l; } 类似于getAndSetLong的实现,只是这里使用CAS的时候使用了原始值+传递的增量参数addValue的值。 那么如何使用Unsafe类呢? 看到 Unsafe 这个类如此牛叉,是不是很想进行练习,好了,首先看如下代码所示: package com.hjc; import sun.misc.Unsafe; /** * Created by cong on 2018/6/6. */ public class TestUnSafe { //获取Unsafe的实例(2.2.1) static final Unsafe unsafe = Unsafe.getUnsafe(); //记录变量state在类TestUnSafe中的偏移值(2.2.2) static final long stateOffset; //变量(2.2.3) private volatile long state = 0; static { try { //获取state变量在类TestUnSafe中的偏移值(2.2.4) stateOffset = unsafe.objectFieldOffset(TestUnSafe.class.getDeclaredField("state")); } catch (Exception ex) { System.out.println(ex.getLocalizedMessage()); throw new Error(ex); } } public static void main(String[] args) { //创建实例,并且设置state值为1(2.2.5) TestUnSafe test = new TestUnSafe(); //(2.2.6) Boolean sucess = unsafe.compareAndSwapInt(test, stateOffset, 0, 1); System.out.println(sucess); } } 代码(2.2.1)获取了Unsafe的一个实例,代码(2.2.3)创建了一个变量state初始化为0. 代码(2.2.4)使用unsafe.objectFieldOffset 获取 TestUnSafe类里面的state变量 在 TestUnSafe对象里面的内存偏移量地址并保存到stateOffset变量。 代码(2.2.6)调用创建的unsafe实例的compareAndSwapInt方法,设置test对象的state变量的值,具体意思是如果test对象内存偏移量为stateOffset的state的变量为0,则更新改值为1 上面代码我们希望输入true,然而执行后会输出如下结果: 为什么会这样呢?必然需要进入getUnsafe代码中如看看里面做了啥: private static final Unsafe theUnsafe = new Unsafe(); public static Unsafe getUnsafe(){ //(2.2.7) Class localClass = Reflection.getCallerClass(); //(2.2.8) if (!VM.isSystemDomainLoader(localClass.getClassLoader())) { throw new SecurityException("Unsafe"); } return theUnsafe; } //判断paramClassLoader是不是BootStrap类加载器(2.2.9) public static boolean isSystemDomainLoader(ClassLoader paramClassLoader){ return paramClassLoader == null; } 代码(2.2.7)获取调用getUnsafe这个方法的对象的Class对象,这里是TestUnSafe.calss。 代码(2.2.8)判断是不是Bootstrap类加载器加载的localClass,这里关键要看是不是Bootstrap加载器加载了TestUnSafe.class。看过Java虚拟机的类加载机制的人,很明显看出是由于TestUnSafe.class 是使用 AppClassLoader 加载的,所以这里直接抛出了异常。 那么问题来了,为什么需要有这个判断呢? 我们知道Unsafe类是在rt.jar里面提供的,而rt.jar里面的类是使用Bootstrap类加载器加载的,而我们启动main函数所在的类是使用AppClassLoader加载的,所以在main函数里面加载Unsafe类时候鉴于双亲委派机制会委托给Bootstrap去加载Unsafe类。 如果没有代码(2.2.8)这个鉴权,那么我们应用程序就可以随意使用Unsafe做事情了,而Unsafe类可以直接操作内存,是很不安全的,所以JDK开发组特意做了这个限制,不让开发人员在正规渠道下使用Unsafe类,而是在rt.jar里面的核心类里面使用Unsafe功能。 问题来了,如果我们真的想要实例化Unsafe类,使用Unsafe的功能,那该怎么办呢? 我们不要忘记了反射这个黑科技,使用万能的反射来获取Unsafe的实例方法,代码如下: package com.hjc; import sun.misc.Unsafe; import java.lang.reflect.Field; /** * Created by cong on 2018/6/6. */ public class TestUnSafe { static final Unsafe unsafe; static final long stateOffset; private volatile long state = 0; static { try { // 反射获取 Unsafe 的成员变量 theUnsafe(2.2.10) Field field = Unsafe.class.getDeclaredField("theUnsafe"); // 设置为可存取(2.2.11) field.setAccessible(true); // 获取该变量的值(2.2.12) unsafe = (Unsafe) field.get(null); //获取 state 在 TestUnSafe 中的偏移量 (2.2.13) stateOffset = unsafe.objectFieldOffset(TestUnSafe.class.getDeclaredField("state")); } catch (Exception ex) { System.out.println(ex.getLocalizedMessage()); throw new Error(ex); } } public static void main(String[] args) { TestUnSafe test = new TestUnSafe(); Boolean sucess = unsafe.compareAndSwapInt(test, stateOffset, 0, 1); System.out.println(sucess); } } 如果上面的代码(2.2.10 2.2.11 2.2.12)反射获取unsafe的实例,运行结果如下: 二.LockSupport类源码探究 JDK中的rt.jar里面的LockSupport是一个工具类,主要作用是挂起和唤醒线程,它是创建锁和其他同步类的基础。 LockSupport类与每个使用他的线程都会关联一个许可证,默认调用LockSupport 类的方法的线程是不持有许可证的,LockSupport内部使用Unsafe类实现。 这里要注意LockSupport的几个重要的函数,如下: 1.void park() 方法: 如果调用 park() 的线程已经拿到了与 LockSupport 关联的许可证,则调用 LockSupport.park() 会马上返回,否者调用线程会被禁止参与线程的调度,也就是会被阻塞挂起。例子如下代码: package com.hjc; import java.util.concurrent.locks.LockSupport; /** * Created by cong on 2018/6/6. */ public class LockSupportTest { public static void main( String[] args ) { System.out.println( "park start!" ); LockSupport.park(); System.out.println( "park stop!" ); } } 如上面代码所示,直接在main函数里面调用park方法,最终结果只会输出park start! 然后当前线程会被挂起,这是因为默认下调用线程是不持有许可证的。运行结果如下: 在看到其他线程调用unpark(Thread thread)方法并且当前线程作为参数时候,调用park方法被阻塞的线程会返回,另外其他线程调用了阻塞线程的interrupt()方法,设置了中断标志时候或者由于线程的虚假唤醒原因后阻塞线程也会返回,所以调用 park() 最好也是用循环条件判断方式。 需要注意的是调用park()方法被阻塞的线程被其他线程中断后阻塞线程返回时候并不会抛出InterruptedException 异常。 2.void unpark(Thread thread) 方法 当一个线程调用了 unpark 时候,如果参数 thread 线程没有持有 thread 与 LockSupport 类关联的许可证,则让 thread 线程持有。如果 thread 之前调用了 park() 被挂起,则调用 unpark 后,该线程会被唤醒。 如果 thread 之前没有调用 park,则调用 unPark 方法后,在调用 park() 方法,会立刻返回,上面代码修改如下: package com.hjc; import java.util.concurrent.locks.LockSupport; /** * Created by cong on 2018/6/6. */ public class LockSupportTest { public static void main( String[] args ) { System.out.println( "park start!" ); //使当前线程获取到许可证 LockSupport.unpark(Thread.currentThread()); //再次调用park LockSupport.park(); System.out.println( "park stop!" ); } } 运行结果如下: 接下来我们在看一个例子来加深对 park,unpark 的理解,代码如下: import java.util.concurrent.locks.LockSupport; /** * Created by cong on 2018/6/6. */ public class LockSupportTest { public static void main(String[] args) throws InterruptedException { Thread thread = new Thread(new Runnable() { @Override public void run() { System.out.println("子线程 park start!"); // 调用park方法,挂起自己 LockSupport.park(); System.out.println("子线程 unpark!"); } }); //启动子线程 thread.start(); //主线程休眠1S Thread.sleep(1000); System.out.println("主线程 unpark start!"); //调用unpark让thread线程持有许可证,然后park方法会返回 LockSupport.unpark(thread); } } 运行结果如下: 上面的代码首先创建了一个子线程thread,启动后子线程调用park方法,由于默认子线程没有持有许可证,会把自己挂起 主线程休眠1s 目的是主线程在调用unpark方法让子线程输出 子线程park start! 并阻塞。 主线程然后执行unpark方法,参数为子线程,目的是让子线程持有许可证,然后子线程调用的park方法就返回了。 park方法返回时候不会告诉你是因为何种原因返回,所以调用者需要根据之前是处于什么目前调用的park方法,再次检查条件是否满足,如果不满足的话,还需要再次调用park方法。 例如,线程在返回时的中断状态,根据调用前后中断状态对比就可以判断是不是因为被中断才返回的。 为了说明调用 park 方法后的线程被中断后会返回,修改上面例子代码,删除 LockSupport.unpark(thread); 然后添加 thread.interrupt(); 代码如下: import java.util.concurrent.locks.LockSupport; /** * Created by cong on 2018/6/6. */ public class LockSupportTest { public static void main(String[] args) throws InterruptedException { Thread thread = new Thread(new Runnable() { @Override public void run() { System.out.println("子线程 park start!"); // 调用park方法,挂起自己,只有中断才会退出循环 while (!Thread.currentThread().isInterrupted()) { LockSupport.park(); } System.out.println("子线程 unpark!"); } }); //启动子线程 thread.start(); //主线程休眠1S Thread.sleep(1000); System.out.println("主线程 unpark start!"); //中断子线程 thread.interrupt(); } } 运行结果如下: 正如上面代码,也就是只有当子线程被中断后子线程才会运行结束,如果子线程不被中断,即使你调用unPark(Thread) 子线程也不会结束。 3.void parkNanos(long nanos)方法:和 park 类似,如果调用 park 的线程已经拿到了与 LockSupport 关联的许可证,则调用 LockSupport.park() 会马上返回,不同在于如果没有拿到许可调用线程会被挂起 nanos 时间后在返回。 park 还支持三个带有blocker参数的方法,当线程因为没有持有许可证的情况下调用park 被阻塞挂起的时候,这个blocker对象会被记录到该线程内部。 使用诊断工具可以观察线程被阻塞的原因,诊断工具是通过调用getBlocker(Thread)方法来获取该blocker对象的,所以JDK推荐我们使用带有blocker参数的park方法,并且blocker设置为this,这样当内存dump排查问题时候就能知道是哪个类被阻塞了。 例子如下: import java.util.concurrent.locks.LockSupport; /** * Created by cong on 2018/6/6. */ public class TestPark { public void testPark(){ LockSupport.park();//(1) } public static void main(String[] args) { TestPark testPark = new TestPark(); testPark.testPark(); } } 运行结果如下: 可以看到运行在阻塞,那么我们要使用JDK/bin目录下的工具看一下了,如果不知道的读者,建议去先看一下JVM的监控工具。 运行后使用jstack pid 查看线程堆栈的时候,可以看到的结果如下: 然后我们进行上面的代码(1)进行修改如下: LockSupport.park(this);//(1) 再次运行,再用jstack pid 查看的结果如下: 可以知道,带blocker的park方法后,线程堆栈可以提供更多有关阻塞对象的信息。 那么我们接下来进行park(Object blocker) 函数的源代码查看,源码如下: public static void park(Object blocker) { //获取调用线程 Thread t = Thread.currentThread(); //设置该线程的 blocker 变量 setBlocker(t, blocker); //挂起线程 UNSAFE.park(false, 0L); //线程被激活后清除 blocker 变量,因为一般都是线程阻塞时候才分析原因 setBlocker(t, null); } Thread类里面有个变量volatile Object parkBlocker 用来存放park传递的blocker对象,也就是把blocker变量存放到了调用park方法的线程的成员变量里面 4.void parkNanos(Object blocker, long nanos) 函数 相比 park(Object blocker) 多了个超时时间。 5.void parkUntil(Object blocker, long deadline) parkUntil源代码如下: public static void parkUntil(Object blocker, long deadline) { Thread t = Thread.currentThread(); setBlocker(t, blocker); //isAbsolute=true,time=deadline;表示到 deadline 时间时候后返回 UNSAFE.park(true, deadline); setBlocker(t, null); } 可以看到是一个设置deadline,时间单位为milliseconds,是从1970到现在某一个时间点换算为毫秒后的值,这个和parkNanos(Object blocker,long nanos)区别是后者是从当前算等待nanos时间的,而前者是指定一个时间点, 比如我们需要等待到2018.06.06 日 20:34,则把这个时间点转换为从1970年到这个时间点的总毫秒数。 我们再来看一个例子,代码如下: import java.util.Queue; import java.util.concurrent.ConcurrentLinkedQueue; import java.util.concurrent.atomic.AtomicBoolean; import java.util.concurrent.locks.LockSupport; /** * Created by cong on 2018/6/6. */ public class FIFOMutex { private final AtomicBoolean locked = new AtomicBoolean(false); private final Queue<Thread> waiters = new ConcurrentLinkedQueue<Thread>(); public void lock() { boolean wasInterrupted = false; Thread current = Thread.currentThread(); waiters.add(current); // 只有队首的线程可以获取锁(1) while (waiters.peek() != current || !locked.compareAndSet(false, true)) { LockSupport.park(this); if (Thread.interrupted()) // (2) wasInterrupted = true; } waiters.remove(); if (wasInterrupted) // (3) current.interrupt(); } public void unlock() { locked.set(false); LockSupport.unpark(waiters.peek()); } } 可以看到这是一个先进先出的锁,也就是只有队列首元素可以获取所,代码(1)如果当前线程不是队首或者当前锁已经被其他线程获取,则调用park方法挂起自己。 接着代码(2)做判断,如果park方法是因为被中断而返回,则忽略中断,并且重置中断标志,只做个标记,然后再次判断当前线程是不是队首元素或者当先锁是否已经被其他线程获取,如果是则继续调用park方法挂起自己。 然后代码(3)中如果标记为true 则中断该线程,这个怎么理解呢?其实就是其他线程中断了该线程,虽然我对中断信号不感兴趣,忽略它,但是不代表其他线程对该标志不感兴趣,所以要恢复下。