Spring Boot 无侵入式 实现RESTful API接口统一JSON格式返回
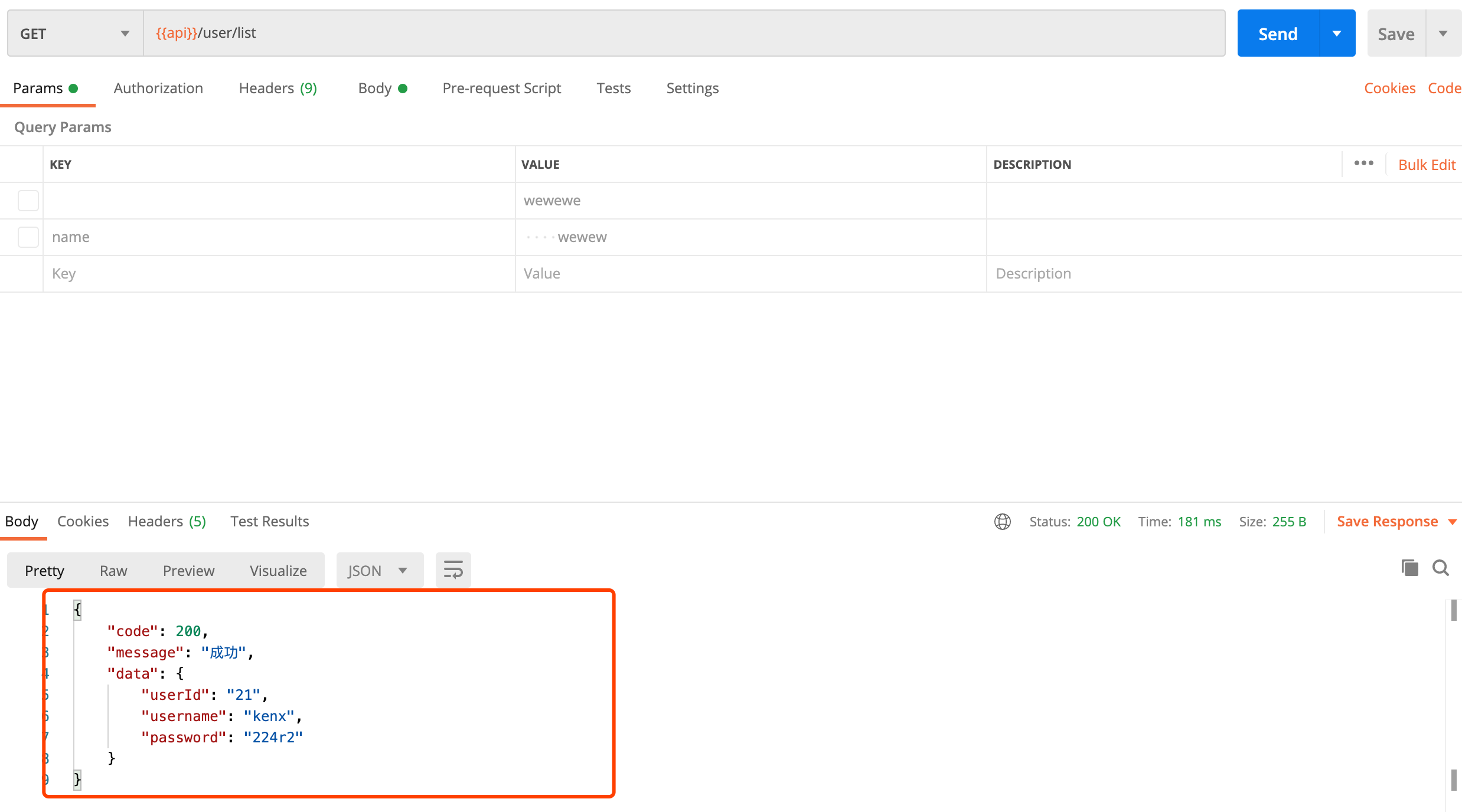
前言 现在我们做项目基本上中大型项目都是选择前后端分离,前后端分离已经成了一个趋势了,所以总这样·我们就要和前端约定统一的api 接口返回json 格式, 这样我们需要封装一个统一通用全局 模版api返回格式,下次再写项目时候直接拿来用就可以了 约定JSON格式 一般我们和前端约定json格式是这样的 { "code": 200, "message": "成功", "data": { } } code: 返回状态码 message: 返回信息的描述 data: 返回值 封装java bean 定义状态枚举 package cn.soboys.core.ret; import lombok.Data; import lombok.Getter; /** * @author kenx * @version 1.0 * @date 2021/6/17 15:35 * 响应码枚举,对应HTTP状态码 */ @Getter public enum ResultCode { SUCCESS(200, "成功"),//成功 //FAIL(400, "失败"),//失败 BAD_REQUEST(400, "Bad Request"), UNAUTHORIZED(401, "认证失败"),//未认证 NOT_FOUND(404, "接口不存在"),//接口不存在 INTERNAL_SERVER_ERROR(500, "系统繁忙"),//服务器内部错误 METHOD_NOT_ALLOWED(405,"方法不被允许"), /*参数错误:1001-1999*/ PARAMS_IS_INVALID(1001, "参数无效"), PARAMS_IS_BLANK(1002, "参数为空"); /*用户错误2001-2999*/ private Integer code; private String message; ResultCode(int code, String message) { this.code = code; this.message = message; } } 定义返回状态码,和信息一一对应,我们可以约定xxx~xxx 为什么错误码,防止后期错误码重复,使用混乱不清楚, 定义返回体结果体 package cn.soboys.core.ret; import lombok.Data; import java.io.Serializable; /** * @author kenx * @version 1.0 * @date 2021/6/17 15:47 * 统一API响应结果格式封装 */ @Data public class Result<T> implements Serializable { private static final long serialVersionUID = 6308315887056661996L; private Integer code; private String message; private T data; public Result setResult(ResultCode resultCode) { this.code = resultCode.getCode(); this.message = resultCode.getMessage(); return this; } public Result setResult(ResultCode resultCode,T data) { this.code = resultCode.getCode(); this.message = resultCode.getMessage(); this.setData(data); return this; } } code,和message都从定义的状态枚举中获取 这里有两个需要注意地方我的数据类型T data返回的是泛型类型而不是object类型而且我的结果累实现了Serializable接口 我看到网上有很多返回object,最后返回泛型因为泛型效率要高于object,object需要强制类型转换,还有最后实现了Serializable接口因为通过流bytes传输方式web传输,速率更块 定义返回结果方法 一般业务返回要么是 success成功,要么就是failure失败,所以我们需要单独定义两个返回实体对象方法, package cn.soboys.core.ret; /** * @author kenx * @version 1.0 * @date 2021/6/17 16:30 * 响应结果返回封装 */ public class ResultResponse { private static final String DEFAULT_SUCCESS_MESSAGE = "SUCCESS"; // 只返回状态 public static Result success() { return new Result() .setResult(ResultCode.SUCCESS); } // 成功返回数据 public static Result success(Object data) { return new Result() .setResult(ResultCode.SUCCESS, data); } // 失败 public static Result failure(ResultCode resultCode) { return new Result() .setResult(resultCode); } // 失败 public static Result failure(ResultCode resultCode, Object data) { return new Result() .setResult(resultCode, data); } } 注意这里我定义的是静态工具方法,因为使用构造方法进行创建对象调用太麻烦了, 我们使用静态方法来就直接类调用很方便 这样我们就可以在controller中很方便返回统一api格式了 package cn.soboys.mallapi.controller; import cn.soboys.core.ret.Result; import cn.soboys.core.ret.ResultResponse; import cn.soboys.mallapi.bean.User; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; /** * @author kenx * @version 1.0 * @date 2021/7/2 20:28 */ @RestController //默认全部返回json @RequestMapping("/user") public class UserController { @GetMapping("/list") public Result getUserInfo(){ User u=new User(); u.setUserId("21"); u.setUsername("kenx"); u.setPassword("224r2"); return ResultResponse.success(u); } } 返回结果符合我们预期json格式 但是这个代码还可以优化,不够完善,比如,每次controller中所有的方法的返回必须都是要Result类型,我们想返回其他类型格式怎么半,还有就是不够语义化,其他开发人员看你方法根本就不知道具体返回什么信息 如果改成这个样子就完美了如 @GetMapping("/list") public User getUserInfo() { User u = new User(); u.setUserId("21"); u.setUsername("kenx"); u.setPassword("224r2"); return u; } 其他开发人员一看就知道具体是返回什么数据。但这个格式要怎么去统一出来? 其实我们可以这么去优化,通过SpringBoot提供的ResponseBodyAdvice进行统一响应处理 自定义注解@ResponseResult来拦截有此controller注解类的代表需要统一返回json格式,没有就安照原来返回 package cn.soboys.core.ret; import java.lang.annotation.*; /** * @author kenx * @version 1.0 * @date 2021/6/17 16:43 * 统一包装接口返回的值 Result */ @Target({ElementType.TYPE, ElementType.METHOD}) @Retention(RetentionPolicy.RUNTIME) @Documented public @interface ResponseResult { } 定义请求拦截器通过反射获取到有此注解的HandlerMethod设置包装拦截标志 package cn.soboys.core.ret; import org.springframework.web.method.HandlerMethod; import org.springframework.web.servlet.HandlerInterceptor; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import java.lang.reflect.Method; /** * @author kenx * @version 1.0 * @date 2021/6/17 17:10 * 请求拦截 */ public class ResponseResultInterceptor implements HandlerInterceptor { //标记名称 public static final String RESPONSE_RESULT_ANN = "RESPONSE-RESULT-ANN"; @Override public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception { //请求方法 if (handler instanceof HandlerMethod) { final HandlerMethod handlerMethod = (HandlerMethod) handler; final Class<?> clazz = handlerMethod.getBeanType(); final Method method = handlerMethod.getMethod(); //判断是否在对象上加了注解 if (clazz.isAnnotationPresent(ResponseResult.class)) { //设置此请求返回体需要包装,往下传递,在ResponseBodyAdvice接口进行判断 request.setAttribute(RESPONSE_RESULT_ANN, clazz.getAnnotation(ResponseResult.class)); //方法体上是否有注解 } else if (method.isAnnotationPresent(ResponseResult.class)) { //设置此请求返回体需要包装,往下传递,在ResponseBodyAdvice接口进行判断 request.setAttribute(RESPONSE_RESULT_ANN, clazz.getAnnotation(ResponseResult.class)); } } return true; } } 实现ResponseBodyAdvice<Object> 接口自定义json返回解析器根据包装拦截标志判断是否需要自定义返回类型返回类型 package cn.soboys.core.ret; import cn.soboys.core.utils.HttpContextUtil; import com.alibaba.fastjson.JSON; import lombok.extern.slf4j.Slf4j; import org.springframework.core.MethodParameter; import org.springframework.http.MediaType; import org.springframework.http.converter.HttpMessageConverter; import org.springframework.http.server.ServerHttpRequest; import org.springframework.http.server.ServerHttpResponse; import org.springframework.web.bind.annotation.ControllerAdvice; import org.springframework.web.context.request.RequestContextHolder; import org.springframework.web.context.request.ServletRequestAttributes; import org.springframework.web.servlet.mvc.method.annotation.ResponseBodyAdvice; import javax.servlet.http.HttpServletRequest; /** * @author kenx * @version 1.0 * @date 2021/6/17 16:47 * 全局统一响应返回体处理 */ @Slf4j @ControllerAdvice public class ResponseResultHandler implements ResponseBodyAdvice<Object> { public static final String RESPONSE_RESULT_ANN = "RESPONSE-RESULT-ANN"; /** * @param methodParameter * @param aClass * @return 此处如果返回false , 则不执行当前Advice的业务 * 是否请求包含了包装注解 标记,没有直接返回不需要重写返回体, */ @Override public boolean supports(MethodParameter methodParameter, Class<? extends HttpMessageConverter<?>> aClass) { HttpServletRequest request = HttpContextUtil.getRequest(); //判断请求是否有包装标志 ResponseResult responseResultAnn = (ResponseResult) request.getAttribute(RESPONSE_RESULT_ANN); return responseResultAnn == null ? false : true; } /** * @param body * @param methodParameter * @param mediaType * @param aClass * @param serverHttpRequest * @param serverHttpResponse * @return 处理响应的具体业务方法 */ @Override public Object beforeBodyWrite(Object body, MethodParameter methodParameter, MediaType mediaType, Class<? extends HttpMessageConverter<?>> aClass, ServerHttpRequest serverHttpRequest, ServerHttpResponse serverHttpResponse) { if (body instanceof Result) { return body; } else if (body instanceof String) { return JSON.toJSONString(ResultResponse.success(body)); } else { return ResultResponse.success(body); } } } 注意这里string类型返回要单独json序列化返回一下,不然会报转换异常 这样我们就可以在controler中返回任意类型,了不用每次都必须返回 Result 如 package cn.soboys.mallapi.controller; import cn.soboys.core.ret.ResponseResult; import cn.soboys.core.ret.Result; import cn.soboys.core.ret.ResultResponse; import cn.soboys.mallapi.bean.User; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; /** * @author kenx * @version 1.0 * @date 2021/7/2 20:28 */ @RestController //默认全部返回json @RequestMapping("/user") @ResponseResult public class UserController { @GetMapping("/list") public User getUserInfo() { User u = new User(); u.setUserId("21"); u.setUsername("kenx"); u.setPassword("224r2"); return u; } @GetMapping("/test") public String test() { return "ok"; } @GetMapping("/test2") public Result test1(){ return ResultResponse.success(); } } 这里还有一个问题?正常情况返回成功的话是统一json 格式,但是返回失败,或者异常了,怎么统一返回错误json 格式,sprinboot有自己的错误格式? 请参考我上一篇,SpringBoot优雅的全局异常处理 扫码关注公众号猿人生了解更多好文