JavaScript的常用基础知识
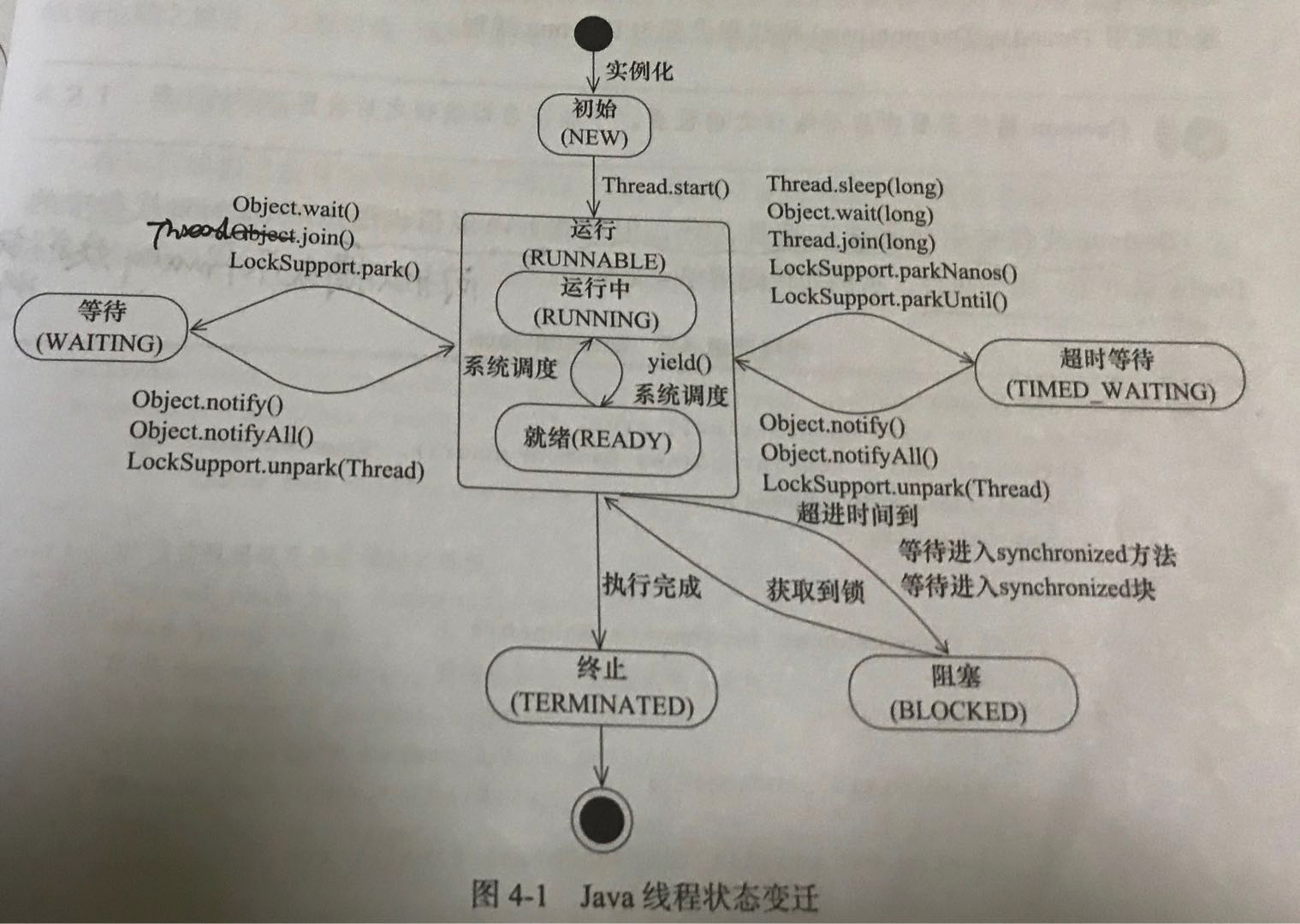
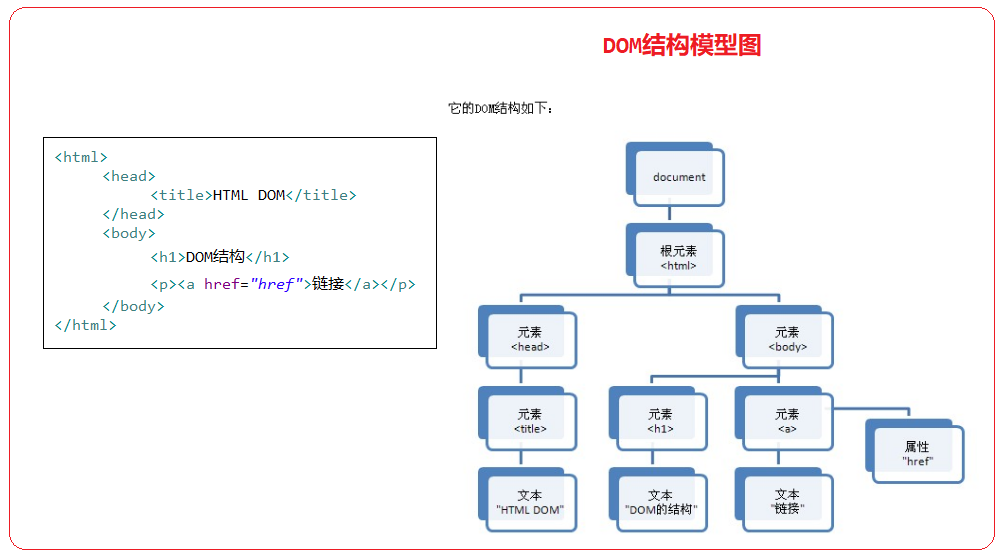
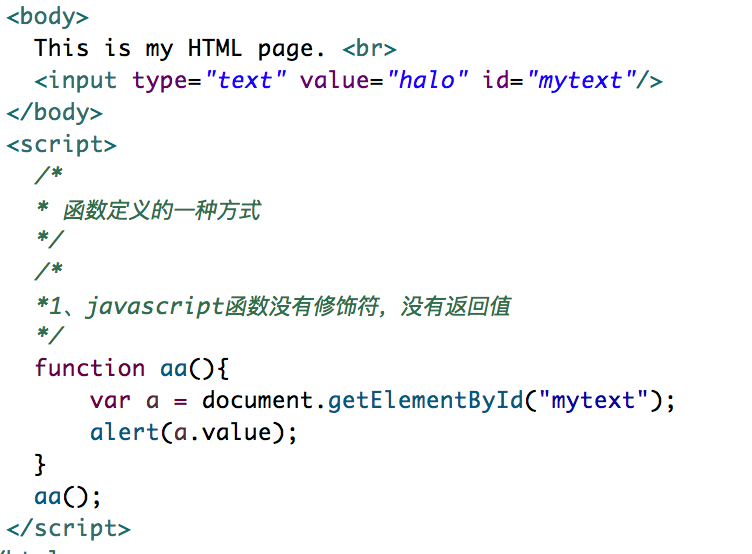
前言 稻光养晦,未雨绸缪 函数的定义 函数定义的第一种方式 屏幕快照 2018-01-26 17.39.05.png 说明 1 . 这是最正常的一种函数表达式 2 . 函数aa可以接受任意的参数 3 . 可以有返回值,可以用变量来接受其返回值 4 . 如果没有return,则返回undefined. 函数定义的第二种方式 屏幕快照 2018-01-26 17.41.48.png 说明 1 . 直接给变量赋值一个函数 2 . 在项目开发中是一种比较常见的形式 Dom对象 DOM是Document Object Model文档对象模型的缩写。根据W3C DOM规范,DOM是一种与浏览器,平台,语言无关的接口,使得你可以访问页面其他的标准组件。 D:文档 – html 文档 或 xml 文档 O:对象 – 把document里的所有节点都看成对象 M:模型(用于建立从文档到对象的模型) 结构如下: 屏幕快照 2018-01-27 00.02.59.png 对应的html页面: 屏幕快照 2018-01-27 00.03.11.png 从上述两个图中可以看出: 1 . 整个html称为dom树,而dom的引用为document,也称为一个节点。 2 . 每一个HTML标签都为一个元素节点 3 . 标签中的文字则是文本节点 4 . 标签中的属性则是属性节点 5 . dom中元素、文本、属性都是节点 6 . dom树是由节点构成的 7 . 每个节点都代表一个对象 常用的API getElementById() 说明: 1、 查询给定ID属性值的元素,返回该元素的元素节点。也称为元素对象。 2、 因为在一个html页面中id的值是唯一的,所以返回值也是唯一的。所以方法的名称为getElementById()而不是getElementsById()。 3、 该方法只能用于document对象,类似与java的static关键字。 例子 屏幕快照 2018-01-27 00.24.44.png getElementsByName() 说明: 1、查找给定name属性的所有元素,这个方法将返回一个节点集合,也可以称为对象集合。 2、这个集合可以作为数组来对待,length属性的值表示集合的个数。 3、因为在html页面中,name不能唯一确定一个元素,所以方法的名称为getElementsByName而不是getElementByName。 例子 屏幕快照 2018-01-27 00.25.53.png getElementsByTagName() 说明: 1、查询给定标签名的所有元素 2、因为在html页面中,标签名不是唯一的,所以返回值为节点的集合。 3、这个集合可以当做数组来处理,length属性为集合里所有元素的个数 例子 <!DOCTYPE html> <html> <head> <title>getElementsByTagName.html</title> <meta name="keywords" content="keyword1,keyword2,keyword3"> <meta name="description" content="this is my page"> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> </head> <body> <form name="form1" action="test.html" method="post"> <input type="text" name="halo" value="我是Halo1!!!" id="halo1"> <input type="text" name="halo" value="我是Halo2!!!" id="halo2"> <input type="text" name="halo" value="我是Halo3!!!" id="halo3"> <input type="text" name="halo" value="我是Halo4!!!" id="halo4"> <input type="button" name="ok" value="OK"> </form> <select name="sport" id="sport"> <option value="篮球">乔丹</option> <option value="足球" selected="selected">梅西</option> <option value="乒乓球">刘国梁</option> <option value="台球">丁俊晖</option> </select> <select name="edu" id="edu"> <option value="专科">专科学位</option> <option value="本科">本科学位</option> <option value="硕士">硕士学位</option> <option value="博士">博士学位</option> </select> </body> <script type="text/javascript"> /*** *1、获取所有input元素的值 *2、输出所有input元素的值,不包括按钮,并且点击文本框,获取相应的值。 *3、输出所有下拉选 id=“edu” 的value值 *4、输出所有下拉选框的内容 *5、选择下拉列表框的内容,并且弹出所选择的内容 *6、针对每一个下拉列表框的内容,弹出所选中的内容 ***/ //1. /******************************************************************/ /* //1.获取所有input元素的值 var inputElements = document.getElementsByTagName("input"); //遍历inputElements数组元素的每一个对象 for(var i=0;i < inputElements.length;i++){ alert(inputElements.item(i).value); } */ //2. /******************************************************************/ //输出所有input元素的值,不包括按钮,并且点击文本框,获取相应的值。 //1、获取input元素的对象数组 var inputElements = document.getElementsByTagName("input"); //2、遍历数组 /* for(var i=0;i<inputElements.length;i++){ if(inputElements[i].type != "button"){ alert(inputElements[i].value); inputElements[i].onclick = function(){ alert(this.value); } } } */ //3. /******************************************************************/ //输出所有下拉选 id=“edu” 的value值 //eduElement.childNodes获取的是所有子节点及子子节点。 /* //1、获取id为edu的对象 var eduElement = document.getElementById("edu"); //2、获取id为edu的对象的子节点 var optionElements = eduElement.getElementsByTagName("option"); for(var i=0;i<optionElements.length;i++){ alert(optionElements[i].value); } */ //4. /******************************************************************/ //输出所有下拉选框的内容 /* var optionElements = document.getElementsByTagName("option"); for(var i=0;i<optionElements.length;i++){ alert(optionElements[i].value); } */ //5. /******************************************************************/ //选择下拉列表框的内容,并且弹出所选择的内容 //1.获取所有的select元素的对象 var selectElements = document.getElementsByTagName("select"); //2.遍历所有的select对象,并且赋值onchange方法 for(var i=0; i<selectElements.length;i++){ selectElements[i].onchange = function(){ //this代表选中的option对象 alert(this.value); } } //6. /******************************************************************/ //针对每一个下拉列表框的内容,弹出所选中的内容 var selectElement1 = document.getElementById("sport"); var selectElement2 = document.getElementById("edu"); selectElement1.onchange = function(){ alert(this.value); } selectElement2.onchange = function(){ alert(this.value); } </script> </html> hasChildNodes() 说明 1、该方法用来判断一个元素是否有子节点。 2、返回值为true或者false。 3、文本节点和属性节点不可能再包含子节点,所以对于这两类节点使用 hasChildNodes()方法返回值永远为false。 4、如果hasChildNodes()返回值为false,则childNodes,firstChild,lastChild将为空数组或者空字符串。 例子 <!DOCTYPE html> <html> <head> <title>hasChildNodes.html</title> <meta name="keywords" content="keyword1,keyword2,keyword3"> <meta name="description" content="this is my page"> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> </head> <body> <form name="form1" action="test.html" method="post"> <input type="text" name="halo" value="我是Halo1!!!" id="halo1"> <input type="text" name="halo" value="我是Halo2!!!" id="halo2"> <input type="text" name="halo" value="我是Halo3!!!" id="halo3"> <input type="text" name="halo" value="我是Halo4!!!" id="halo4"> <input type="button" name="ok" value="OK"> </form> <select name="edu" id="edu"> <option value="专科">专科学位</option> <option value="本科">本科学位</option> <option value="硕士">硕士学位</option> <option value="博士">博士学位</option> </select> </body> <script type="text/javascript"> /* *分两种情况输出hasChildNodes()的值 * 1、有子节点 * 2、没有子节点 */ //输出有子节点的值 var eduElement = document.getElementById("edu"); //因为有子节点,所以返回值为true alert(eduElement.hasChildNodes()); //输出没有子节点的值 var halo1Element = document.getElementById("halo1"); alert(halo1Element.hasChildNodes()); </script> </html> nodeName属性 说明 1、文档中的每一个节点都有这个属性。 2、为给定节点的名称。 3、如果节点是元素节点,nodeName返回元素的名称;如果给定节点为属性节点,nodeName返回属性的名称;如果给定节点为文本节点,nodeName返回为#text的字符串; 例子 <!DOCTYPE html> <html> <head> <title>nodeName.html</title> <meta name="keywords" content="keyword1,keyword2,keyword3"> <meta name="description" content="this is my page"> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> </head> <body> <select name="edu" id="edu"> <option value="本科">本科学位</option> <option value="硕士">硕士学位</option> <option value="博士">博士学位</option> <option value="专科">专科学位</option> </select> </body> <script type="text/javascript"> /* *分别输出edu元素节点元素及属性name,id的nodeName * */ //1.获得edu对象 var eduElement = document.getElementById("edu"); //2.获得edu对象的nodeName alert(eduElement.nodeName); //这一步获得的是<select name="edu" id="edu">的name属性的值 //var nameElement = eduElement.name; //通过eduElement.getAttributeNode()可以获取属性的对象 var nameElement = eduElement.getAttributeNode("name"); alert(nameElement.nodeName); var idElement = eduElement.getAttributeNode("id"); alert(idElement.nodeName); var optionElements = eduElement.getElementsByTagName("option"); for(var i=0;i<optionElements.length;i++){ alert(optionElements[i].nodeName); var valueElement = optionElements[i].getAttributeNode("value"); alert(valueElement.nodeName); } </script> </html> nodeType属性 说明 1、该节点表明节点类型,返回值为一个整数 2、常用的节点类型有三种: (1)、 元素节点类型 值为1 (2)、属性节点类型 值为2 (3)、文本节点类型 值为3 例子 <!DOCTYPE html> <html> <head> <title>nodeName.html</title> <meta name="keywords" content="keyword1,keyword2,keyword3"> <meta name="description" content="this is my page"> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> </head> <body> <select name="edu" id="edu"> <option value="专科">专科学位</option> <option value="本科">本科学位</option> <option value="硕士">硕士学位</option> <option value="博士">博士学位</option> </select> </body> <script type="text/javascript"> /* *分别输出edu元素节点元素及属性name,id的nodeType *输出option元素的子节点文本元素的元素类型 */ //1.分别输出edu元素节点元素及属性name,id的nodeType var eduElement = document.getElementById("edu"); //alert(eduElement.nodeType); var nameElement = eduElement.getAttributeNode("name"); //alert(nameElement.nodeType); var idElement = eduElement.getAttributeNode("id"); //alert(idElement.nodeType); var optionElements = eduElement.getElementsByTagName("option"); for(var i=0;i<optionElements.length;i++){ //alert(optionElements[i].nodeType); var valueElement = optionElements[i].getAttributeNode("value"); alert(valueElement.nodeType); var textElement = optionElements[i].firstChild; alert(textElement.nodeType); } </script> </html> nodeType属性 说明 1、返回给定节点的当前值(字符串)。 2、如果给定节点是属性节点,返回值是这个属性的值;如果给定节点是文本节点,返回值是这个文本节点的内容;如果给定节点是元素节点,返回值是null。 3、nodeValue是一个读写属性。 例子 <!DOCTYPE html> <html> <head> <title>nodeValue.html</title> <meta name="keywords" content="keyword1,keyword2,keyword3"> <meta name="description" content="this is my page"> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> </head> <body> <select name="edu" id="edu"> <option value="专科">专科学位</option> <option value="本科">本科学位</option> <option value="硕士">硕士学位</option> <option value="博士">博士学位</option> </select> </body> <script type="text/javascript"> /* *分别输出edu元素节点元素及属性name,id的nodeValue *输出option元素的子节点文本元素的元素类型 */ //1、获得edu的元素节点 var eduElement = document.getElementById("edu"); //2、获得eduElement的nodeValue的值 alert(eduElement.nodeValue); //获得edu属性name的元素节点值 var nameElement = eduElement.getAttributeNode("name"); alert(nameElement.nodeValue); //获得edu属性id的元素节点值 var idElement = eduElement.getAttributeNode("id"); alert(nameElement.nodeValue); //输出option元素的子节点文本元素的元素类型 var optionElements = eduElement.getElementsByTagName("option"); for(var i = 0; i < optionElements.length; i++){ var valueElement = optionElements[i].getAttributeNode("value"); alert(valueElement.nodeValue); var textElement = optionElements[i].firstChild; alert(textElement.nodeValue); } </script> </html> replaceChild() 说明 1、把一个给定父元素里的一个子节点替换为另外一个子节点; 2、var reference = element.replaceChild(newChild,oldChild); 3、返回值指向已经被替换掉的那个子节点的引用; 例子 <!DOCTYPE html> <html> <head> <title>replaceChild.html</title> <meta name="keywords" content="keyword1,keyword2,keyword3"> <meta name="description" content="this is my page"> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> </head> <body> 您喜欢的城市:<br> <ul> <li id="wh" value="wuhan">武汉</li> <li id="km" value="kunming">昆明</li> <li id="sz" value="shenzhen">深圳</li> </ul> 您喜欢的词语:<br> <ul> <li id="six" value="sixsixsix">666</li> <li id="dy" value="daye">大爷</li> <li id="ly" value="laoye">老爷</li> </ul> </body> <script type="text/javascript"> /* *点击北京节点,将被给力节点替换 */ window.onload = function(){ //1、得到北京节点 var whElement = document.getElementById("wh"); //2、注册onclick事件 whElement.onclick = function(){ //3、找到wh节点的父节点 var ulElement = whElement.parentNode; //4、获得gl节点 var dyElement = document.getElementById("dy"); //5、替换 ulElement.replaceChild(dyElement,whElement); } } </script> </html> getAttribute() 说明 1、返回一个给定元素的给定属性的节点的值 2、var attributeValue = element.getAttribute(attributeName) 3、给定属性的名字必须以字符串的形式传递给该方法 4、给定属性的值将以字符串的形式返回 5、通过属性获取属性节点getAttributeNode(属性的名称) --返回属性节点 例子 <!DOCTYPE html> <html> <head> <title>getAttribute.html</title> <meta name="keywords" content="keyword1,keyword2,keyword3"> <meta name="description" content="this is my page"> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> </head> <body> 您喜欢的词语:<br> <ul> <li id="six" value="sixsixsix">666</li> <li id="dy" value="daye">大爷</li> <li id="ly" value="laoye">老爷</li> </ul> </body> <script type="text/javascript"> /** ** 获取<li id="six" value="sixsixsix">666</li>的属性id和value的值 **/ var sixElement = document.getElementById("six"); //第一种方法: alert(sixElement.getAttributeNode("id").nodeValue); alert(sixElement.getAttributeNode("value").nodeValue); //第二种方法: alert(sixElement.getAttribute("id")); alert(sixElement.getAttribute("value")); </script> </html> setAttribute() 说明 1、将给定元素添加一个新的属性或改变它现有属性的值; 2、element.setAttribute(attributeName,attributeValue); 3、属性的名字和值必须以字符串的形式传递; 4、如果这个属性已经存在,那么值将被attributeValue取代; 5、如果这个属性不存在,那么先创建它,再给他赋值; 例子 <!DOCTYPE html> <html> <head> <title>setAttribute.html</title> <meta name="keywords" content="keyword1,keyword2,keyword3"> <meta name="description" content="this is my page"> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> </head> <body> 您喜欢的词语:<br> <ul> <li id="six" value="sixsixsix">666</li> <li id="dy" value=daye"">大爷</li> <li id="ly" value="laoye">老爷</li> </ul> </body> <script type="text/javascript"> /** ** 给<li id="ly" value="laoye">老爷</li>增加一个name属性,并赋值,然后输出 **/ var lyElement = document.getElementById("ly"); lyElement.setAttribute("name", "halo"); alert(lyElement.getAttribute("name")); </script> </html> createElement() 说明 1、按照给定的标签名创建一个新的元素节点,方法的参数为被创建的元素的名称; 2、var reference = document.createElement(elementName); 3、方法的返回值指向新建节点的引用,返回值是一个元素节点,所以nodeType 为1; 4、新建的节点不会自动添加到文档里,只是存在于document里一个游离的对象; 例子 <!DOCTYPE html> <html> <head> <title>createElement.html</title> <meta name="keywords" content="keyword1,keyword2,keyword3"> <meta name="description" content="this is my page"> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> </head> <body> 您喜欢的词语:<br> <ul> <li id="six" value="sixsixsix">666</li> <li id="dy" value=daye"">大爷</li> <li id="ly" value="laoye">老爷</li> </ul> </body> <script type="text/javascript"> /** ** 为ul增加一个新的元素<li id="cs" value="cs">计算机</li> ** **/ //1.创建<li></li> var liElement = document.createElement("li"); //2.创建文本节点 传说 var textElement = document.createTextNode("计算机"); //3.<li id="cs" value="cs">计算机</li>的形成 liElement.appendChild(textElement); liElement.setAttribute("id", "cs"); liElement.setAttribute("value", "cs"); //4.获得ul对象 var ulElement = document.getElementsByTagName("ul")[0]; ulElement.appendChild(liElement); </script> </html> innerHTML属性 说明 用来读写某个元素中的HTML内容 例子 <!DOCTYPE html> <html> <head> <title>innerHTML.html</title> <meta name="keywords" content="keyword1,keyword2,keyword3"> <meta name="description" content="this is my page"> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> </head> <body> <div id="mydiv"><h1 id="h">halo是我的简称!!</h1></div> </body> <script type="text/javascript"> /** *读取div中的html内容 **/ var divElement = document.getElementById("mydiv"); var h1Element = document.getElementById("h") alert(divElement.textContent); alert(h1Element.textContent); </script> </html> window.onload 说明 1、在页面上所有的数据加载完以后触发该方法; 2、这样做的好处是,有时候一些JS函数要用到页面上的一些数据,但是此时有些数据还没有加载进来。这个时候触发函数,就会报一些异常。所以用window.onload方法可以确保数据安全落地; 例子 <!DOCTYPE html> <html> <head> <title>window_load.html</title> <meta name="keywords" content="keyword1,keyword2,keyword3"> <meta name="description" content="this is my page"> <meta http-equiv="content-type" content="text/html; charset=UTF-8"> </head> <body> this is my HTML page.<br> </body> <script type="text/javascript"> /** *把页面中的所有的数据加载完以后触发该方法 **/ window.onload = function(){ alert("ssssss"); } </script> </html>