《老男孩Linux运维笔记》笔记
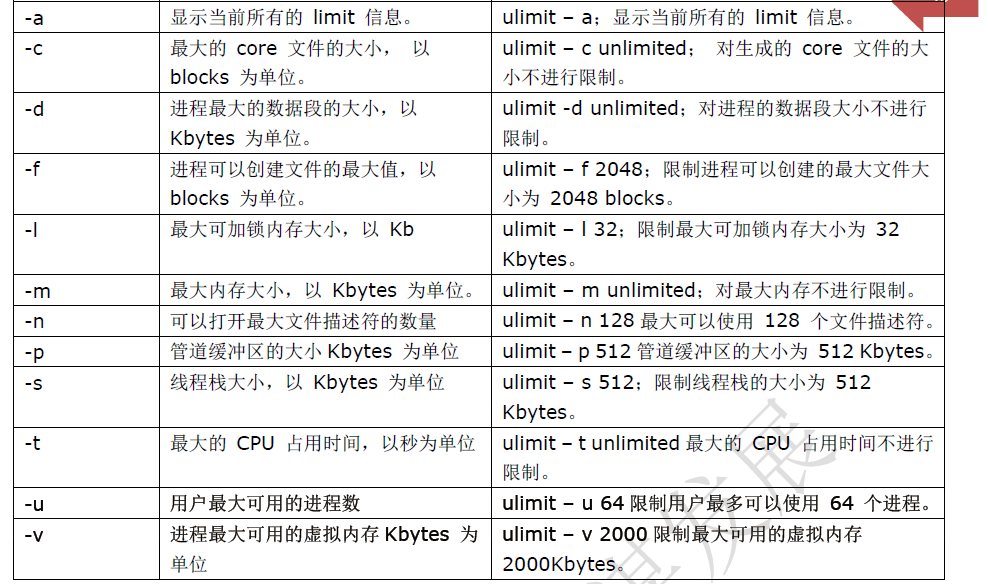
centos7为基准 1、更改YUM源: /bin/mv CentOS-Base.repo CentOS-Base.repo.ori //备份 yum 源 7 wget http://mirrors.sohu.com/help/CentOS-Base-sohu.repo //下载soho 源 /bin/mv CentOS-Base-sohu.repo CentOS-Base.repo 打补丁: yum upgrade 安装必要的软件包: yum -y install lrzsz 2、关闭selinux: vi /etc/sysconfig/selinux disabled 重启 3、设定运行级别: systemctl get-default systemctl set-default shutdown.target(0) emergency.target rescure.target multi-user.target(3) graphical.target(5) 4、关闭不必要的服务 systemctl list-units --type=service 开机启动:systemctl enable crond network sshd syslog 5、授权服务:visudo root ALL=(ALL) ALL %wheel ALL=(ALL) ALL %wheel ALL=(ALL) NOPASSWD: ALL 6、ssh优化:vi /etc/ssh/sshd_config 52113#→ssh 连接默认的端口,谁都知道,必须要改。 PermitRootLogin no#→root 用户黑客都知道的,禁止它远程登陆。 PermitEmptyPasswords no #→禁止空密码登陆 UseDNSno#→不使用DNS GSSAPIAuthentication no 重启sshd 服务#/etc/init.d/sshd restart 7、修改默认字符集: locale -a vi /etc/locale.conf source /etc/locale.conf 8、同步时间服务: echo '*/5 * * * * /usr/sbin/ntpdate time.nist.gov >/dev/null 2>&1' >>/var/spool/cron/root 9、修改文件描述符: ulimit -n echo '* - nofile 65535 ' >>/etc/security/limits.conf 10、清理clientmqueue垃圾文件防止inode被占满 find /var/spool/clientmqueue/ -type -f |xargs rm -f 11、内核优化:vi /etc/sysctl.conf net.ipv4.tcp_fin_timeout = 2 net.ipv4.tcp_tw_reuse = 1 net.ipv4.tcp_tw_recycle = 1 net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_keepalive_time = 600 net.ipv4.ip_local_port_range = 4000 65000 net.ipv4.tcp_max_syn_backlog = 16384 net.ipv4.tcp_max_tw_buckets = 36000 net.ipv4.route.gc_timeout = 100 net.ipv4.tcp_syn_retries = 1 net.ipv4.tcp_synack_retries = 1 net.core.somaxconn = 16384 12 net.core.netdev_max_backlog = 16384 net.ipv4.tcp_max_orphans = 16384 net.ipv4.ip_conntrack_max = 25000000 net.ipv4.netfilter.ip_conntrack_max=25000000 net.ipv4.netfilter.ip_conntrack_tcp_timeout_established=180 net.ipv4.netfilter.ip_conntrack_tcp_timeout_time_wait=120 net.ipv4.netfilter.ip_conntrack_tcp_timeout_close_wait=60 net.ipv4.netfilter.ip_conntrack_tcp_timeout_fin_wait=120 12、grep高亮显示: vi /etc/profile alias grep='grep --color=auto' source /etc/profile 13、锁定关键文件 chattr +i /etc/passwd chattr +i /etc/inittab chattr +i /etc/group chattr +i /etc/shadow chattr +i /etc/gshadow 14、更改登录后的信息:/etc/motd 15、内核参数: 16、NFS:yum install -y nfs-utils rpcbind vi /etc/exports xx ip(rw) exportfs -r mount -t nfs xx:/xx /yy mount -t nfs -o nosuid,noexec,nodev,rw,bg,soft,rsize=32768,wsize=32768 192.168.1.4:/home/test /usr/local/live/ 17、apache安装调优参数: ./configure \ --prefix=/application/apache2.2.27 \#安装的目录 --enable-deflate \ #压缩文件文本一般 html/js/css 等内容的站点,使用此参数功能会大大提高传输速度,提示访问者访问体验,在生产环境中,这是apache 调优的重要选项之一 --enable-expires \ #激活允许通过配置文件控制http 的“expires”和“cache-control” 头内容,即对网站图片,js,css 等内容,提供在客户端浏览器缓存的设置,这是apache 调优的重 要选项之一 --enable-headers \ #提供允许http 请求头的控制 --enable-moudles=most \ #激活多数模块 --enable-so \ #激活apache 服务的DSO 支持,即在以后可以以DSO 的方式编译 安装共享模块,这个模块本身不能以DSO 方式编译 --with-mpm=worker \ #选择apache mpm 的模式为worker 模式,因为worker 模式原 理是更多的使用线程来处理请求,所以可以处理更多的并发请求,而系统资源的开销小于基于进程 的MPM prefork,如果不指定此参数,默认得到模式是prefork 进程模式。这是apache 调优的一 个重要选项之一。 --enable-rewrite #提供基于URL 规则的重写功能,根据已知URL 地址,转换其他想 要的url 地址,如伪静态功能就是这个模块实现的,这是apache 在生产环节中必用的一个重要功能 检查语法:apachectl -t 启用: apachectl start 平滑重启:apachectl graceful 18、apache配置文件:Httpd.conf ServerRoot "/usr/local/xxx" #安装目录 Listen 80 <ifModule !mpm_netware_moudle> User daemon #执行者 Group daemon ServerAdmin xx@qq.com DocumentRoot "/xx" #网站根目录 #设置根目录访问权限 <Directory /> Options FollowSymLinks AllowOverride None Order allow,deny Allow from all </Direcotry> <ifModule dir_module> DirectoryIndex index.html </ifModule> #AllowOverride:允许存在.htaccess 文件中的指令类型None:当AllowOverride 设置None 时,不搜索该目录下的.htaccessAll:在.htaccess 文件中使用所有指令 #Allow:允许访问的主机列表(可用域名或子网,例如:Allow from 192.168.0.0/16)。 #DirectoryIndex index.html index.htm index.php #主页文件的设置(本例将主页文件设置为: index.html,index.htm 和index.php) #Options特性:ExecCGI 在该目录下执行CGI脚本FollowSymLinks:在该目录下允许文件系统使用符号连接Indexes: 当用户访问该目录时,如果用户找不到DirectoryIndex 指定的主页文件(例如index.html),则返回该目录下的文件列表给用户。SymLinksIfOwnerMatch: 当使用符号连接时,只有当符号连接的文件拥有者与实际文件的拥有者相同时才可以访问。 #设置其他目录权限 <Direcotry "/usr/local"> Options Indexes FollowSymLinks AllowOverride None Order allow,deny Allow from all 19、apache的PHP.INI配置 /application/php/lib/php.ini [PHP] engine = On ——→ 是否启用PHP 解析引擎 short_open_tag = Off ——→ 是否使用简介标志 asp_tags = Off ——→ 不允许asp 类标志 precision = 14 ——→ 浮点型数据显示的有效期 y2k_compliance = On output_buffering = 4096 ——→ 输出缓冲区大小(字节)。建议值为4096~8192。 zlib.output_compression = Off ——→ 是否开启zlib 输出压缩 implicit_flush = Off ——→ 是否要求PHP 输出层在每个输出块之后自动刷新数据 这等效于在每个print()、echo()、HTML 块之后自动调用flush()函数。打开这个选项对程序执行 的性能有严重的影响,通常只推荐在调试时使用。在CLI SAPI 的执行模式下,该指令默认为On 。 serialize_precision = 17 safe_mode = Off ——→ 安全模式 safe_mode_gid = Off safe_mode_exec_dir = ——→ 安全模式下的可执行文件存放目录 safe_mode_allowed_env_vars = PHP_ ####在安全模式下,用户仅可以更改的环境变量的前缀列表(逗号分隔)。允许用户设置某些环境变 量,可能会导致潜在的安全漏洞。注意: 如果这一参数值为空,PHP 将允许用户更改任意环境变量。 safe_mode_protected_env_vars = LD_LIBRARY_PATH ####在安全模式下,用户不能更改的环境变量列表(逗号分隔)。这些变量即使在safe_mode_allowed_env_vars 指令设置为允许的情况下也会得到保护。 disable_functions = ——→ 该指令接受一个用逗号分隔的函数名列表,以禁用特定的函数。 disable_classes = ——→ 该指令接受一个用逗号分隔的类名列表,以禁用特定的类 expose_php = On ——→ 在网页头部显示php 信息 max_execution_time = 30 ——→ 每个脚本最大执行秒数 max_input_time = 60 ——→ 每个脚本用来分析请求数据的最大限制时间 memory_limit = 128M ——→ 每个脚本执行的内存限制 72 display_errors = Off ——→ #显示失误(该关闭,换成日志显示) display_startup_errors = Off ——→ #显示启动失误 log_errors = On ——→ 生成错误错误日志显示 log_errors_max_len = 1024 ——→ 设定error_log 最大长度 ignore_repeated_errors = Off ——→ 打开后,不记录重复的信息 ignore_repeated_source = Off ——→ 打开后当记录重复的信息时忽略来源 report_memleaks = On ——→ 报告内存泄露,仅在debug 编译模式下有效 html_errors = Off ——→ 是否开启静态网页错误提示 register_globals = Off ——→ ##是否打开register 全局变量 register_long_arrays = Off ####是否注册老形式的输入数组, HTTP_GET_VARS 和相关数组;如果你不使用他们,建议为了提 高性能关闭他们. register_argc_argv = Off ####此指令让PHP 确认是否申明argv&argc 变量(这些变量会包含GET 信息). ;如果你不使用这 些变量,为了提升性能应该关闭此选项. auto_globals_jit = On ####当打开此项, SERVER 和 ENV 变量将在第一次被使用时而不是脚本一开始时创建(运行时);如 73 果这些变量在脚本中没有被使用过, 打开此项会增加一点性能.;为了使此指令有效,PHP 指令 register_globals, register_long_arrays,;以及register_argc_argv 必须被关闭. post_max_size = 8M ——→ #PHP 可以接受的最大的POST 数据大小 magic_quotes_sybase = Off ##使用Sybase 风格的magic quotes (使用"来引导'替代\'). auto_prepend_file = ——→ #在任何PHP 文档之前或之后自动增加文件 auto_append_file = ####两个有趣的变量是auto_prepend_file 以及auto_append_file。这些变量指定PHP 自动添加 到任何PHP 文档文件头或文件尾的其他文件。这对于为PHP 产生的页面添加页眉或页脚非常有用, 可以节省为每个PHP 文档添加代码的时间。但需要注意这里的指定文件将会添加到所有的PHP 文 档中,所以这些变量必须适合单应用程序(single-application)的服务器。所包含的文件要么是 PHP 脚本,要么是普通的HTML 文档。嵌入式PHP 代码必须用标准标记括起来。 default_mimetype = "text/html" ——→ #PHP 内建默认为text/html doc_root = ——→ #PHP 的"根目录"。仅在非空时有效。 file_uploads = On 是否开启上传功能 upload_max_filesize = 2M #最大可上传文件,2M max_file_uploads = 20 最大同时可以上传20 个文件 allow_url_fopen = On #是否允许打开远程文件 allow_url_include = Off #是否允许include/require 远程文件 default_socket_timeout = 60 默认的socket 超时时间 pdo_mysql.cache_size = 2000 ——→ Ped_mysql 的缓存大小 pdo_mysql.default_socket= ——→ 默认的socket 时间 [Phar] [Syslog] define_syslog_variables = Off ——→ 是否定义各种的系统日志变量 [mail function] ——→ 邮件功能 SMTP = localhost ——→ 本地作为邮件服务器 smtp_port = 25 邮件端口号默认是25 mail.add_x_header = On ——→ 是否开启最大的header [ODBC] odbc.allow_persistent = On ——→ 允许或阻止持久连接. odbc.check_persistent = On ——→ 在重用前检查连接是否可用 odbc.max_persistent = -1 ——→ 持久连接的最大数目,-1 意味着没有限制. odbc.max_links = -1 ——→ 最大连接数(持久+ 非持久).-1 意味着没有限制. odbc.defaultlrl = 4096 ——→ 长字段处理.返回变量的字节数.0 意味着略过. odbc.defaultbinmode = 1 ####二进制数据处理.0 意味着略过,1 按照实际返回,2 转换到字符.;查看odbc_binmode 和 odbc_longreadlen 的文档来获取针对uodbc.defaultlrl 和uodbc.defaultbinmode 的解释 [Interbase] ——→ Interbase 数据库 75 ibase.allow_persistent = 1 ——→ 允许或组织持久连接。 ibase.max_persistent = -1 ——→ 持久连接的最大数目,-1 意味着没有限制. ibase.max_links = -1 ——→ 最大连接数(持久+ 非持久).-1 意味着没有限制. ibase.timestampformat = "%Y-%m-%d %H:%M:%S" ——→ 数据库时间记录模式 ibase.dateformat = "%Y-%m-%d" ibase.timeformat = "%H:%M:%S" [MySQL] mysql.allow_local_infile = On ——→ 是否允许本地文件连接数据库 mysql.allow_persistent = On ——→ 允许或禁止持久连接 mysql.cache_size = 2000 ——→ mysql 缓存大小 mysql.max_persistent = -1 ——→ 持久连接的最大数目. -1 意味着没有限制. mysql.max_links = -1 ——→ 连接的最大数目(持久和非持久)。-1 代表无限制 mysql.default_port = ####mysql_connect() 使用的默认端口,如不设置,mysql_connect() ;将使用变量$MYSQL_TCP_PORT,或在/etc/services 下的mysql-tcp 条目(unix), ;或在编译是定义的MYSQL_PORT(按这样的顺序) mysql.default_socket = ####用于本地MySql 连接的默认的套接字名。为空,使用MYSQL 内建值 mysql.default_host = ——→ mysql_connect() 默认使用的主机(安全模式下无效) mysql.default_user = ——→ mysql_connect() 默认使用的用户名(安全模式下无效) mysql.default_password = ——→ mysql_connect() 默认使用的密码(安全模式下无效 mysql.connect_timeout = 60 ——→ 连接超时时间,默认是60s mysql.trace_mode = Off [MySQLi] mysqli.max_persistent = -1 ——→ 持久连接的最大数目. -1 意味着没有限制. mysqli.allow_persistent = On ——→ 允许或拒绝之久连接 76 mysqli.max_links = -1 ——→ 最大连接数. -1 意味着没有限制. mysqli.cache_size = 2000 ——→ 连接缓存大小 mysqli.default_port = 3306 ——→ 连接端口号 ####mysqli_connect()默认的端口号.如果没有设置, mysql_connect() 会使用 $MYSQL_TCP_PORT;或者位于/etc/services 的mysql-tcp 入口或者编译时定义的 MYSQL_PORT 值(按照此顺序查找).;Win32 只会查找MYSQL_PORT 值. mysqli.default_socket = ####对于本地MySQL 连接的默认socket 名称. 如果为空, 则使用MySQL 内建默认值. mysqli.default_host = ####mysqli_connect()的默认host 值(在安全模式中不会生效) mysqli.default_user = ####mysqli_connect()的默认user 值(在安全模式中不会生效). mysqli.default_pw = ####mysqli_connect() 的默认password 值(在安全模式中不会生效). ; 注意在此文件中保存密码一般来说是*糟糕* 的主义. ; *任何* 使用PHP 的用户可以执行'echo get_cfg_var("mysqli.default_password") ; 并且获取到此密码! 而且理所当然, 任何有对此文件读权限的用户都可以获取到此密码. mysqli.reconnect = Off ——→ 允许或阻止持久连接 [mysqlnd] mysqlnd.collect_statistics = On mysqlnd.collect_memory_statistics = Off [OCI8] [PostgreSQL] pgsql.allow_persistent = On ——→ 允许或阻止持久连接. pgsql.auto_reset_persistent = Off ####总是在pg_pconnect() 时检测断开的持久连接.;自动重置特性会引起一点开销. pgsql.max_persistent = -1 ——→ 持久连接的最大数目. -1 意味着没有限制. 77 pgsql.max_links = -1 ——→ 最大连接数(持久+ 非持久). -1 意味着没有限制 pgsql.ignore_notice = 0 ——→ 是否忽略PostgreSQL 后端通告消息.;通告消息记录会需要 一点开销. pgsql.log_notice = 0 ####是否记录PostgreSQL 后端通告消息.;除非pgsql.ignore_notice=0, 否则模块无法记录通 告消息。 [Sybase-CT] sybct.allow_persistent = On ——→ 允许或阻止持久连接. sybct.max_persistent = -1 ——→ 持久连接的最大数目. -1 意味着没有限制. sybct.max_links = -1 ——→ 最大连接数(持久+ 非持久). -1 意味着没有限制. sybct.min_server_severity = 10 ——→ 显示出的错误最小严重程度. sybct.min_client_severity = 10 ——→ 显示出的消息最小严重程度 [bcmath] bcmath.scale = 0 ——→ #用于所有bcmath 函数的10 十进制数数字的个数 [browscap] [Session] session.save_handler = files ——→ 用于保存/取回数据的控制方式 session.use_cookies = 1 ——→ 是否使用cookies session.use_only_cookies = 1 ####这个选项允许管理员去保护那些在URL 中传送session id 的用户免于被攻击;默认是0. session.name = PHPSESSID ——→ session 的名字(同时作为cookie 的名称 session.auto_start = 0 ——→ 在请求开始时初始化session session.cookie_lifetime = 0 ——→ cookie 的存活秒数,如果为0,则是直到浏览器重新启动 session.cookie_path = / ——→ cookie 的有效路径 session.cookie_domain = ——→ cookie 的有效域名 session.cookie_httponly = ####是否将httpOnly 标志增加到cookie 上,增加后则 cookie 无法被浏览器的脚本语言(例如 JavaScript)存取. 78 session.serialize_handler = php 用于序列化数据的处理器. php 是标准的PHP 序列化器. session.gc_probability = 1 ####; 定义'垃圾回收'进程在每次session 初始化时开始的比例. ; 比例由gc_probability/gc_divisor 来得出, ; 例如. 1/100 意味着在每次请求时有1%的机会启动'垃圾回收'进程. session.gc_divisor = 1000 session.gc_maxlifetime = 1440 ####在这里数字所指的秒数后,保存的数据将被视为'碎片(garbage)'并由gc 进程清理掉。 session.bug_compat_42 = Off ####PHP 4.2 和更早版本有一个未公开的特性/bug , 此特性允许你在全局初始化一个session 变量,即便register_globals 已经被关闭.;如果此特性被使用,PHP 4.3 和更早版本会警告你.;你可以 关闭此特性并且隔离此警告. 这时候,如果打开bug_compat_42,那此警告只是被显示出来. session.bug_compat_warn = Off session.referer_check = ####检查HTTP Referer 来防止带有id 的外部URL.;HTTP_REFERER 必须包含从session 来的这 个字段才会被认为是合法的. session.entropy_length = 0 ——→ 从此文件读取多少字节 session.cache_limiter = nocache ####设置为{nocache,private,public,}来决定HTTP 缓冲的类型;留空则防止发送anti-caching 头. session.cache_expire = 180 ——→ 文档在n 分钟之后过期. session.use_trans_sid = 0 ####trans sid 支持默认关闭. ;使用trans sid 可能让你的用户承担安全风险.;使用此项必须小心.; - 用户也许通过email/irc/其他 途径发送包含有效的session ID 的URL 给其他人.; - 包含有效session ID 的URL 可能被存放在容 易被公共存取的电脑上.; - 用户可能通过在浏览器历史记录或者收藏夹里面的包含相同的session ID 的URL 来访问你的站点. 20、httpd-mpm.conf文件详解 #prefork 多路处理模块 <IfModule mpm_prefork_module> StartServers 5 #设置服务器启动时建立的子进程数量,一般不调 MinSpareServers 5 #设置空闲子进程的最小数量,不要调太大 MaxSpareServers 10 #设置空闲子进程的最大数量 MaxClients 150 #用于服务器客户端最大请求数量 MaxRequestsPerChild 0 #每个子进程在生存期内允许服务器的最大请求数,建议10000-30000 #worker 多路处理模块 <IfModule mpm_worker_module> StartServers 2 #设置服务器启动时建立的子进程数量,一般不调 MaxClients 150 #用于服务器客户端最大请求数量 MinSpareThreads 25 #设置空闲子进程的最小数量,不要调太大 MaxSpareThreads 75 #设置空闲子进程的最大数量 ThreadsPerChild 25 #每个子进程建立的线程数 MaxRequestsPerChild 0 #设置每个子进程在其生存期内允许伺服的最大请求数量 21、http-default.conf详解 Timeout 300 #设置服务器在断定请求失败前等待的秒数。默认值300 KeepAlive Off #设置是否启用HTTP 持久链接,On 代表打开,Off 代表关闭。 如果用于同一页面包含大量静态文件的应用,设置为On,以提高性能; 如果用于主要为动态页面的应用,设置为Off,以节约内存资源; 如果服务器前跑有squid 或者其它七层设备,设置为On MaxKeepAliveRequests 100 #限制当启用KeepAlive 时,每个连接允许的请求数量。 如果将此值设为"0",将不限制请求的数目。 笔者建议将此值设为100-500 之间的一个值, 以确保最优的服务器性能 KeepAliveTimeout 5 #设置持久链接中服务器在两次请求之间等待的秒数。对于高负荷服务器来说, KeepAliveTimeout 值较大会导致一些性能方面的问题: 超时值越大,与空闲客户端保持连接的进程就越多 UseCanonicalName Off #配置服务器如何确定它自己的域名, 可选值为On | Off | DNS。DNS 用于为大量基于IP 的虚拟主机支持那些古董级的不提供"Host:"头的浏览器使 用。 笔者建议设置为Off AccessFileName .htaccess #设置分布式配置文件的名字,默认为.htaccess。 如果为某个目录启用了分布式配置文件功能,那么在向客户端返回其中的文档时, 服务器将在这个文档所在的各级目录中查找此配置文件,因此会带来性能问题, 笔者建议关闭分布式配置文件功能。 ServerTokens Prod #控制服务器回应给客户端的"Server:"应答头是否包含关于服务器操作系统类型和编译 进的模块描述信息, 同时还控制着ServerSignature 指令的显示内容。可选值为Full | OS | Minor | Minimal | Major | Prod。 笔者建议设置为显示最少信息的Prod。 ServerSignature Off #配置服务器生成页面的页脚,可选值为On | Off | EMail。 采用On 会简单的增加一行关于服务器版本和正在伺服的虚拟主机的ServerName, 而EMail 设置会额外创建一个指向ServerAdmin 的"mailto:"部分。建议使用默认值Off。 HostnameLookups Off #设置是否启用对客户端IP 的DNS 查找,可选值为On | Off | Double。 DNS 查询会造成明显的时间消耗,建议设置为Off。 22、bin目录 23、虚拟主机配置: vim httpd-vhosts.conf NameVirtualHost *:80 <VirtualHost *:80> ServerAdmin 291406980@qq.com DocumentRoot "/var/www/html/www" ServerName www.etiantian.org ServerAlias etiantian.org ErrorLog "logs/www-error_log" CustomLog "logs/www-access_log" common vim httpd.conf Include conf/extra/httpd-vhosts.conf #基于端口 NameVirtualHost *:80 NameVirtualHost *:8000 NameVirtualHost *:9000 #基于IP <VirtualHost 192.168.1.1:90> xxxxxxxxx 24、apache日志: CustomLog "logs/blog-access_log" combined #日志轮询 #统计IP awk '{print $1}' access_bbs_xx.log|sort|uniq -c|sort -rn 25、隐藏版本信息: 方法一: ※首先修改源文件,再进行make && make install 编译安装 编辑源文件/usr/local/apache2/include/ap_release.h 文件 [root@Nagios-Server include]# vimap_release.h #define AP_SERVER_BASEPRODUCT "IIS" #define AP_SERVER_MAJORVERSION_NUMBER 7 #define AP_SERVER_MINORVERSION_NUMBER 0 #define AP_SERVER_PATCHLEVEL_NUMBER 0 #define AP_SERVER_DEVBUILD_BOOLEAN 0 编辑源文件/usr/local/apache2/include/os.h 文件 [root@Nagios-Server include]# vimos.h #define PLATFORM "Win32" 方法二: [root@Nagios-Server include]# vim /usr/local/apache2/conf/httpd.conf # Various default settings Include conf/extra/httpd-default.conf [root@Nagios-Server include]# vim /usr/local/apache2/conf/extra/httpd-default.conf #ServerTokens Prod #ServerSignature off [root@Nagios-Server include]# curl -I 192.168.1.125 89 HTTP/1.1 200 OK Date: Sun, 07 Dec 2014 11:55:51 GMT Server: Apache/2.2.23 (Unix) PHP/5.4.1 #此处无法去掉,若要隐藏,只有用方法一 Last-Modified: Sat, 06 Dec 2014 07:22:37 GMT ETag: "42760-19-509870ed29d1c" Accept-Ranges: bytes Content-Length: 25 Content-Type: text/html 26、apache的rewrite:vi /etc/httpd.conf LoadModule rewrite_module modules/mod_rewrite.so RewriteEngine on Include conf.d/xx.conf RewriteCond %{HTTP_HOST} hunk.test.com [NC] RewriteRule ^(.*)/index.html$ http://hunk.test.com/test.html [L,R=302] 27、apache安全 Allow from [All /全域名/部分域名/IP 地址/网络地址/CIDR 地址] All:表示全部客户端 全域名:表示域名对应的客户端,如www.domain.com 部分域名:表示域名内所有客户端,如domain.com IP 地址:如172.20.17.1 网络地址:如172.20.17.0/255.255.255.0 CIDR 地址:如172.20.17.0/24 htpasswd -c /usr/local/apache2/conf/users sam 28、图片防盗链 28、忽略某些访问日志 29、APACHE日志分析 1.获得访问前10 位的ip 地址 [root@apache ~]# cat access_log |awk '{print $1}'|sort|uniq -c|sort -nr|head -10 2.访问次数最多的文件或页面,取前20 cat access.log|awk ‘{print $11}’|sort|uniq -c|sort -nr|head -20 3.列出传输最大的几个exe 文件 cat access.log |awk ‘($7~/\.exe/){print $10 ” ” $1 ” ” $4 ” ” $7}’|sort -nr|head -20 4. 列出输出大于200000byte(约200kb)的exe 文件以及对应文件发生次 数 cat access.log |awk ‘($10 > 200000 && $7~/\.exe/){print $7}’|sort -n|uniq -c|sort -nr|head -100 5. 如果日志最后一列记录的是页面文件传输时间,则有列出到客户端 最耗时的页面 cat access.log |awk ‘($7~/\.php/){print $NF ” ” $1 ” ” $4 ” ” $7}’|sort -nr|head -100 6. 列出最最耗时的页面(超过60 秒的)的以及对应页面发生次数 cat access.log |awk ‘($NF > 60 && $7~/\.php/){print $7}’|sort -n|uniq -c|sort -nr|head -100 7. 列出传输时间超过30 秒的文件 cat access.log |awk ‘($NF > 30){print $7}’|sort -n|uniq -c|sort -nr|head -20 8. 统计网站流量(G) 94 cat access.log |awk ‘{sum+=$10} END {print sum/1024/1024/1024}’ 9. 统计404 的连接 awk ‘($9 ~/404/)’ access.log | awk ‘{print $9,$7}’ | sort 10. 统计http status. cat access.log |awk ‘{counts[$(9)]+=1}; END {for(code in counts) print code, counts[code]}' cat access.log |awk '{print $9}'|sort|uniq -c|sort -rn 11. 蜘蛛分析 查看是哪些蜘蛛在抓取内容。 /usr/sbin/tcpdump -i eth0 -l -s 0 -w - dst port 80 | strings | grep -i user-agent | grep -i -E 'bot|crawler|slurp|spider' Webalizer 日志分析程序 [root@Apache-Server tools]# yum install -y webalizer [root@Apache-Server tools]# less /etc/webalizer.conf 30、apache tomcat整合 http://blog.51cto.com/maofan/1560639