用 k8s 管理机密信息 - 每天5分钟玩转 Docker 容器技术(155)
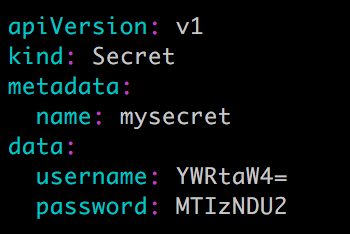
应用启动过程中可能需要一些敏感信息,比如访问数据库的用户名密码或者秘钥。将这些信息直接保存在容器镜像中显然不妥,Kubernetes 提供的解决方案是 Secret。 Secret 会以密文的方式存储数据,避免了直接在配置文件中保存敏感信息。Secret 会以 Volume 的形式被 mount 到 Pod,容器可通过文件的方式使用 Secret 中的敏感数据;此外,容器也可以环境变量的方式使用这些数据。 Secret 可通过命令行或 YAML 创建。比如希望 Secret 中包含如下信息: 用户名admin 密码123456 创建 Secret 有四种方法创建 Secret: 1. 通过--from-literal: kubectl create secret generic mysecret --from-literal=username=admin --from-literal=password=123456 每个--from-literal对应一个信息条目。 2. 通过--from-file: echo -n admin > ./username echo -n 123456 > ./password kubectl create secret generic mysecret --from-file=./username --from-file=./password 每个文件内容对应一个信息条目。 3. 通过--from-env-file: cat << EOF > env.txt username=admin password=123456 EOF kubectl create secret generic mysecret --from-env-file=env.txt 文件env.txt中每行 Key=Value 对应一个信息条目。 4. 通过 YAML 配置文件: 文件中的敏感数据必须是通过 base64 编码后的结果。 执行kubectl apply创建 Secret: 下一节我们学习如何使用这些创建好的 Secret。 书籍: 1.《每天5分钟玩转Kubernetes》https://item.jd.com/26225745440.html 2.《每天5分钟玩转Docker容器技术》https://item.jd.com/16936307278.html 3.《每天5分钟玩转OpenStack》https://item.jd.com/12086376.html