🔥 xbatis ORM 框架 1.9.3 正式发布,一款最好用的基于 mybatis 的 ORM 框架!
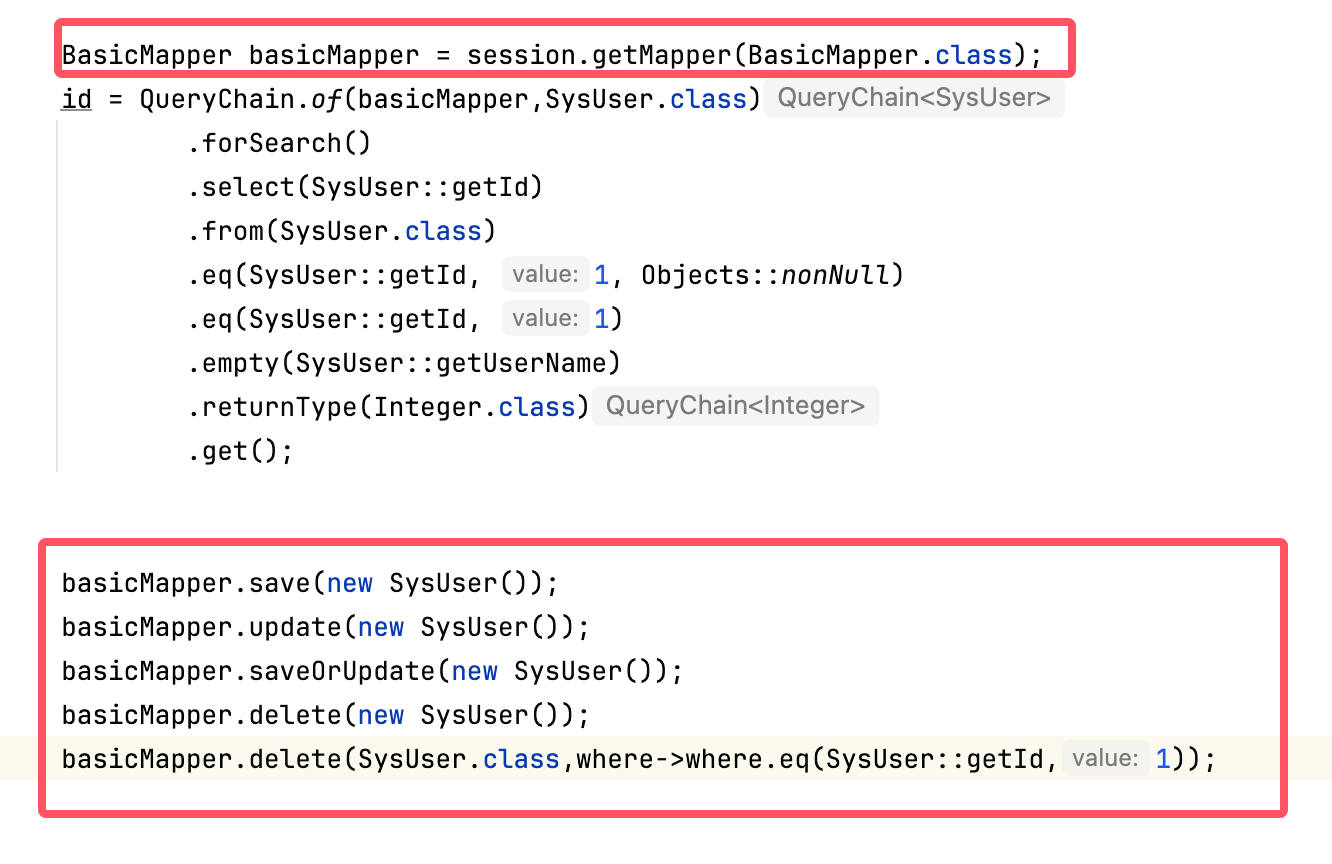
1.9.3 更新内容 1:@Fetch注解在内存分页基础上增加内存排序 2:修复and(XXX::getX,c->c.in or c.not(list)错误问题 3:@Fetch注解支持缓存能力 4:update delete 增加exists notExists 多条件方法 5:优化in子查询,实现简洁优雅的写法 6:支持springboot4 1.8.7 更新内容: 1:为了更好的 JAVA+XML 结合,query 和 where 增加 tableAs (实体类,别名) 方法,用于自定义表名别名 2:XbatisConfig 改为 XbatisGlobalConfig 3:增加逻辑删除拦截器 4:updatedelete增加 原生 RETURNING (原生) 功能 5:增加原生 sql 查询方法和update delete RETURNING 功能 6:增加了一个Mapper 方法拦截器 7:增加exists/not exists 简易写法 通用 SQL 扩展: //类型支持 实体类,VO和普通POJO SysUser user = sysUserMapper.select(SysUser.class, "select * from t_sys_user where id =?", 1); //支持增删改,且支持返回数据 String user_name = sysUserMapper.executeAndReturning(String.class, "update t_sys_user set user_name=? where id=1 RETURNING user_name", "xxx"); //ORM写法 删除并返回被删除的数据(数据库原生操作) List<SysUser> list = DeleteChain.of(sysUserMapper) .in(SysUser::getId, 1, 2) .returning(SysUser.class) .returnType(SysUser.class) .executeAndReturningList(); //ORM写法 修改并返回修改后的数据(数据库原生操作)适合金额加减操作返回剩余金额 SysUser sysUser = UpdateChain.of(sysUserMapper) .eq(SysUser::getId, 1) .set(SysUser::getUserName, "abc2") .returning(SysUser.class) .returnType(SysUser.class) .executeAndReturning(); 分表配置 @Data @SplitTable(SysUserSplitter.class) public class SysUser { @TableId private Integer id; @SplitTableKey private Integer groupId; private String nickname; private String username; } public class SysUserSplitter implements TableSplitter { @Override public boolean support(Class<?> type) { return type == Integer.class || type == int.class; } @Override public String split(String sourceTableName, Object splitValue) { Integer groupId = (Integer) splitValue; //分成10个表 return sourceTableName + "_" + groupId % 10; } } 分表就是这么简单,其他操作和常规无异!!! 1.7.7 更新内容: 1:QueryChain,DeleteChain,InsertChain,UpdateChain 支持 BasicMapper 方法 2:支持通用 BasicMapper,可不需要创建多个实体类 Mapper;一个 BasicMapper 即可使用所有功能 3:正式支持单 Mapper (写一个 Mapper 即可) 为什么推荐 xbatis?: xbatis 是一款超级强大的 ORM 框架 1:可多表 join(不再只能单表了) 2:代码分页,xml 还可以分页(可以不用 pagehelper 了) 3:良好的扩展能力:orm+sql 模板 (让 ORM 框架不再死板,扩展性极强) 4:强大的各种数据库适配,可在一套代码中 实现多个数据库适配;真正的 ORM hibernate 都做不到 6:极简的 api 设计,让开发者 不再迷糊 1.单表 +@Fetch 注解 + fetchFilter 方法 @Data @ResultEntity(SysUser.class) public class SysUserVo { private Integer id; private String userName; private String password; private Integer roleId; private LocalDateTime create_time; @Fetch(source = SysUser.class, property = "roleId", target = SysRole.class, targetProperty = "id") private List<SysRoleVo> sysRoles; } List<SysUserVO> list = QueryChain.of(sysUserMapper) .from(SysUser.class) .fetchFilter(SysUserVO::getRoles,where->where.eq(SysRole::getStatus,1)) .returnType(SysUserVO.class) .list(); fetchFilter 方法是对 @Fetch 注解的增强,没有特殊要求一般,可忽略 2. 单表查询 SysUser sysUser = QueryChain.of(sysUserMapper) .eq(SysUser::getId, 1) .eq(SysUser::getUserName,'admin') .get(); 3.VO 映射 @Data @ResultEntity(SysUser.class) public class SysUserVo { private Integer id; private String userName; //字段名字不一样时 @ResultEntityField(property = "password") private String pwd; } SysUserVO sysUserVO = QueryChain.of(sysUserMapper) .eq(SysUser::getId, 1) .eq(SysUser::getUserName,'admin') .returnType(SysUserVO.class) .list(); 4. join 查询 @Data @ResultEntity(SysUser.class) public class SysUserVo { private Integer id; private String userName; //字段名字不一样时 @ResultEntityField(property = "password") private String pwd; //映射一个对象 1对1 @NestedResultEntity(target = SysRole.class) prviate SysRole sysRole; //映射多个对象 1对多 @NestedResultEntity(target = SysRole.class) prviate List<SysRole> sysRoles; } List<SysUserRoleVO> list = QueryChain.of(sysUserMapper) .from(SysUser.class) .join(SysUser.class, SysRole.class) .returnType(SysUserRoleVO.class) .list(); 还有很多很多超级方便有趣的写法,欢迎大家来使用https://xbatis.cn 例如: 1 . 多表 join A 内嵌 B B 内嵌 C 都可以 2 . 不使用 join 使用 @Fetch 注解 + fetchFilter 方法实现 将 A JOIN B 变成 query A + query B 3 . 使用 @Paging 注解 实现你的 xml 自动分页 4 . 使用 SQL 模板,让你 ORM 更简单更容易扩展,再也不怕被框架限制了