WEB-WORKER进阶学习(二)
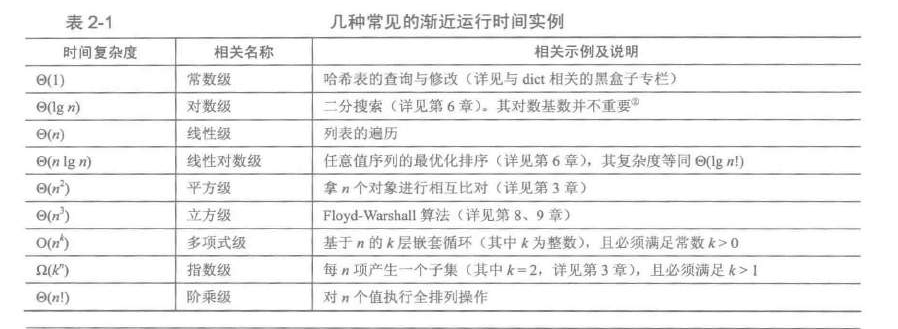
由于JS单线程模型的原因,虽然可以通过异步来处理请求。但是最终还是需要由主线成处理 出于希望将渲染 / (请求、计算) 解耦的想法,所以对现在由axios构建的api请求层做改造,所有的数据请求交予web-work处理。达到渲染与请求分开的目的 问题 同时存在多少个Worker比较合适 ? 理论上worker没有上限,开启多少个都可以,根据实际情况即可。不建议按照CPU(navigator.hardwareConcurrency)核心数开启对应的数量 像目前做的请求/渲染分离就是开启4个作为守护线程。因为除了IE6,7最少支持4个并发请求 多个Worker如何协同工作 ? 需要考虑开启多个worker的统一调配的问题,与负载均衡的问题。 开启的worker可以通过数组存储 负载均衡可以使用轮询,最有可用等算法来处理 消息该如何处理 ? 与axios不同的是,worker处理请求跨越不同的线程,真正的实现异步的请求。那如何保证正确的触发回调 内部通过Promise构建,返回调用者Promise对象,同时为任务分配唯一ID。将任务ID, resolve,reject 同时存储记录 worker将返回数据/异常与接受到的任务ID一并打包返回 通过任务ID将任务从任务池中pop出,执行对应的回调 请求使用什么技术? 仍然使用axios还是fetch ? 这点其实比较纠结 axios使用方便 但是不使用axios可以缩减压缩包体积 如果是项目改造需要将axios的格式与fetch的api格式做转换处理 最终选用fetch, 在内部实现时,增加拦截器对数据做处理。 另外考虑的一点是, fetch脱离了xhr的。理论上性能更好,但是也有缺点 fetch只对网络请求报错,对400,500都当做成功的请求,需要封装去处理 fetch默认不会带cookie,需要添加配置项 fetch不支持abort,不支持超时控制,使用setTimeout及Promise.reject的实现的超时控制并不能阻止请求过程继续在后台运行,造成了量的浪费 fetch没有办法原生监测请求的进度,而XHR可以 全局配置如何处理,例如请求头? 通过拦截器前置处理 跨域的问题 ? 不建议使用jsonp, 可以增加cors头或者增加一个node做中转 如何将worker的代码混淆压缩? 通过 对web-worker做处理,配置如下 // 整合worker-loader,基于vue-cli3 config.module .rule('worker') .test(/\.worker\.js$/) .use('worker-loader') .loader('worker-loader') .end() config.module.rule('js').exclude.add(/\.worker\.js$/) webpack外链(未测试) 实现 整体构思将分为两块 线程组 工作组内部持有所有活动work的实例,提供消息转发,均衡算法支持,回调机制实现,内部包含 interceptor 拦截器 参考axios的前后置拦截机制,提供默认的请求、相应的处理并对外暴露 export const interceptors = { // 前置适配转换数据类型 transfer(config) { return { url: `${window.location.origin}${process.env.VUE_APP_BASE_API}${config.url}${config.params ? '?' + param(config.params) : ''}`, options: { body: config.data ? JSON.stringify(config.data) : undefined, cache: config.cache, headers: config.headers || {}, method: config.method || 'GET' } } }, // 请求过滤 request(config) { if (store.getters.token) { config.options.headers['Auth'] = getToken() } return config }, // 响应过滤 async response(res) { return res } } balance 负载均衡 内部实现负载均衡的实现 const balance = (function() { let index = 0 /** 均衡算法 */ const BALANCE_ALGORITHM = { /** 轮询下标 */ ROUND_ROBIN() { const next = workers[index % workers.length] index++ return next } } const tasks = {} const addTask = (option, resolve, reject) => { const id = uuid() option.id = id tasks[id] = { resolve: resolve, reject: reject } } return { next() { return BALANCE_ALGORITHM.ROUND_ROBIN() }, postMessage(option, resolve, reject) { addTask(option, resolve, reject) this.next().postMessage(option) }, popTask(id) { const task = tasks[id] delete task[id] return task } } })() workers worker线成组,持有对应实例 const workers = new Array(4) for (let i = 0; i < workers.length; i++) { const worker = new Worker() worker.onmessage = receive workers[i] = worker } 工作组 工作组内部实现队列机制,接受到的任务逐一消费回复,通过队列机制防止高并发的请求峰值,通过合理的机制对请求削峰,并且浏览器对单域请求存在上限(以Chrome为例,上限为6)。所以内部实际是一个状态机,其内部包含: queue 请求任务队列 const queue = [] state 当前运行状态, 默认空闲 /** 运行中 */ const RUNNING = 'RUNNING' /** 空闲 */ const IDLE = 'IDLE' /** 当前状态 */ let state = IDLE request 请求函数 /** * 执行请求 * 通过fetch发送请求,将反馈发送到主线程 * 结束后检查队列 * @param event event main-thread message */ const request = (event) => { state = RUNNING const { data } = event fetch(data.url, data.options) .then(response => response.json()) .then(json => { postMessage({ success: true, response: json, id: data.id }) }) .catch(reason => { postMessage({ error: true, message: reason.message, id: data.id }) }) .finally(() => { const next = queue.pop() if (next) { request(next) } else { state = IDLE } }) } 不足 超时等问题如何处理? 文件上传如何处理? 增加轮询之外的负载策略?