阿里巴巴淘票票专家分享:如何利用阿里云ARMS,搭建国际化在线售票的业务监控系统
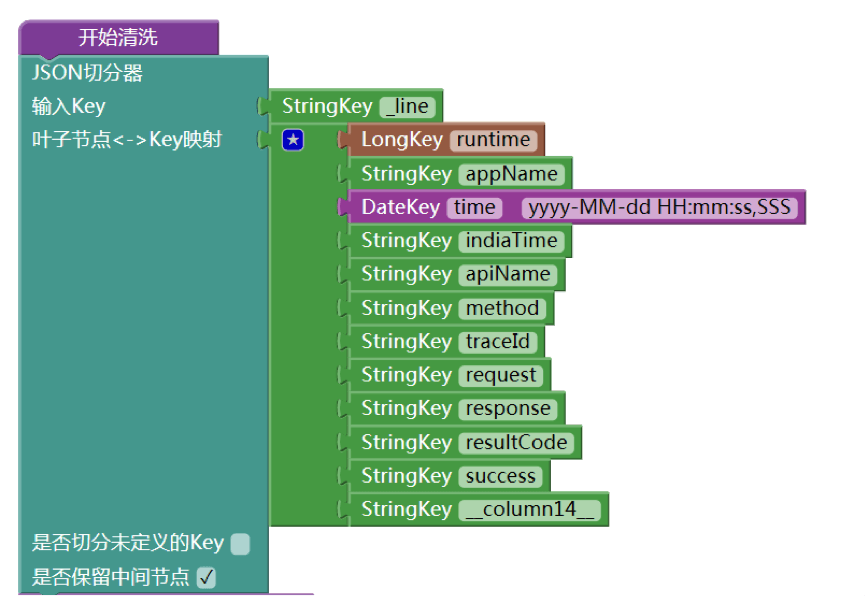
阿里巴巴旗下-淘票票 王伟 撰稿 1. 简介 淘票票为了开拓国际业务,需要做国际化的在线售票,并选择了阿里云新加坡节点作为技术方案,项目上线后急需一套自动化的监控系统代替人肉维护监控。看了ARMS的功能说明,发现其刚好以很低的接入成本来满足我们业务实时监控的需求,因此决定采用阿里云的业务实时监控服务(ARMS)做业务监控。 业务的基本需求是需要实时大盘和报警功能,对要实时统计订票接口的各种状态进行统计和报警,包括: 订票成功率,从业务层面看是否系统运行正常。 订票接口状态,如响应时间,同比环比调用,等,从系统层面看是否系统运行正常。 以下篇幅从日志设计到配置,到最终大盘展示。 2. 监控配置 2.1. 采集日志 ARMS基本原理是采集日志通过实时流式计算出聚合数据监控业务,可以通过ECS,LogHub,SDK等多种方式获得日志源,这里我们选择LogHub,因为我们所有使用阿里云的ECS已经采集日志到日志服务上,只需要简单通过配置即可让ARMS从LogHub上获取日志。 采集到LogHub上的原始日志示例为: 2017-08-21 13:54:48,805|20170821|2f58c35e15033448888056471d27aa|tibizrouter|HSFBizProcessor-5-thread-265|INFO|API_DIGEST:108|RegionAPIImpl|getRegionNotice|1|0|Y[{"appChannel":"000100","appDevice":"458805f1934f07_dwada29t0gCNkDAIQwAJI4EOia__353317069054105","appEnv":"PROD","appPlatform":"ANDROID","appVersion":"4.1.2","regionId":1}]|- 2017-08-21 13:54:48,806|20170821|2f58d75c13231228888057385d7976|tibizrouter|HSFBizProcessor-5-thread-244|INFO|API_DIGEST:108|ConfigAPIImpl|getByGroup|3|0|Y|[{"appChannel":"000100","appDevice":"660d3b4bd6872442__WX/m9PEqA2cDANH6dYHwh2k6__3550awdaw61314546","appEnv":"PROD","appPlatform":"ANDROID","appVersion":"4.2.0"}]|- 按照我们定义的分隔符解析日志格式为JSON,格式示例如下: {"__column15__":"28667","__column16__":"","runtime":"449","__column17__":"","__column14__":"4","response":"-","appName":"tigateway","time":"2017-04-19 21:24:20,462","apiName":"ticketnew","logLevel":"INFO","request":"{\"boxOffice\":\"TICKETNEW\",\"extAreaId\":\"3\",\"extCinemaId\":\"4\",\"extScheduleId\":\"28667\"}","traceId":"2f58d75c1492608260eeaa2072d7d0f","thread":"HSFBizProcessor-5thread-42","resultCode":"0","__column18__":"","indiaTime":"20170419","logName":"API:73","method":"PULL_SOLD_SEAT","success":"Y"} {"runtime":"1","response":"-","appName":"tibizrouter","time":"2017-04-19 21:24:21,102","apiName":"MovieAPIImpl","logLevel":"INFO","request":"[{\"appChannel\":\"000100\",\"appDevice\":\"ANcca0bff117c2faaf__WPnpLeWzcDAIlMjjPv2LJS\",\"appEnv\":\"PROD\",\"appPlatform\":\"ANDROID\",\"appVersion\":\"4.1.0\",\"movieId\":2515,\"regionId\"1}]","traceId":"2f58d75c1492adwa611022076d7d0f","thread":"HSFBizProcessor-5-thread-40","resultCode":"0","indiaTime":"20170419","logName":"API_DIGEST:108","method":"getMovieDetail","success":"Y"} 其中: • method是业务方法名,通过appName,apiName和method来唯一确定某个应用系统上某个接口的业务方法; • success用来表示该业务方法执行成功与否; • resultCode来用表示方法返回的错误码; • runtime表示该方法执行的时间,单位为毫秒,可以用来统计哪些方法执行较慢,做后期优化; • request为方法请求参数。 2.2.配置切分 对以上已经存在的字段按照JSON切分器切分,为了计算成功率,还需要把成功数转换成数字类型,方便在数据集做累加来计算。 2.3.配置数据集 配置接口成功率,通过sum累加得到成功的数量successCount,通过count得到总数量totalCount,使用successCount/totalCount得到成功率,当然也可以额外计算平均接口耗时等参数,在通过下砖维度获取按维度的成功率。 2.4.配置报警 由数据集可以直接配置报警,当成功率低于一定阈值的时候直接发出报警,实时监控线上业务,最大成都降低业务影响范围。 2.5.配置业务大盘 通过配置好的数据集就可以配置业务接口成功率大盘了,用来监控各个业务的实时稳定性。 3. 业务提升 我们通过ARMS对目前线上大部分业务性能指标如成功率,接口错误码分布,接口平均响应时间等性能参数做了实时监控,尤其在前段时间两次重大活动中及时发现线上性能问题,针对特定问题及时响应解决起了巨大的作用,提升了业务稳定性和业务响应速度。 除稳定性方面,我们也通过ARMS配置实时业务数据监控,通过按维度统计订单,用户访问等业务数据,根据不同时间段的业务数据快速调整业务运营和决策,对业务增长起了很好的推动作用。 ARMS正在公测,速来