HarmonyOS官方模板学习 之 Grid Ability(Java)
@[toc](目录) # Grid Ability(Java) ## 介绍 使用Java语言开发,用于Phone设备的Feature Ability模板,使用XML布局,显示内容为两部分网格表,网格每行显示4个项目,网格内元素可进行拖拽排序。 ## 搭建环境 安装DevEco Studio,详情请参考[DevEco Studio下载](https://developer.harmonyos.com/cn/develop/deveco-studio)。 设置DevEco Studio开发环境,DevEco Studio开发环境需要依赖于网络环境,需要连接上网络才能确保工具的正常使用,可以根据如下两种情况来配置开发环境: 如果可以直接访问Internet,只需进行[下载HarmonyOS SDK](https://developer.harmonyos.com/cn/docs/documentation/doc-guides/environment_config-0000001052902427)操作。 如果网络不能直接访问Internet,需要通过代理服务器才可以访问,请参考[配置开发环境](https://developer.harmonyos.com/cn/docs/documentation/doc-guides/environment_config-0000001052902427)。 ## 代码结构解读 注意:'#'代表注释 后台功能 ```json gridabilityjava │ MainAbility.java │ MyApplication.java │ ├─component │ DragLayout.java #自定义的拖拽功能组件 │ GridView.java #自定义的Grid视图组件,extends TableLayout │ ├─model │ GridItemInfo.java #Grid item 模型 │ ├─provider │ GridAdapter.java #给Grid提供实例化好的item 组件列表;提供了计算单个item的宽度的方法 │ ├─slice │ MainAbilitySlice.java #主能力页,负责实例化自定义的DragLayout拖拽组件 │ └─utils AppUtils.java #工具类,提供了从element资源中中获取value;获取屏幕的坐标的方法 ``` 这是几个java类之间的关系 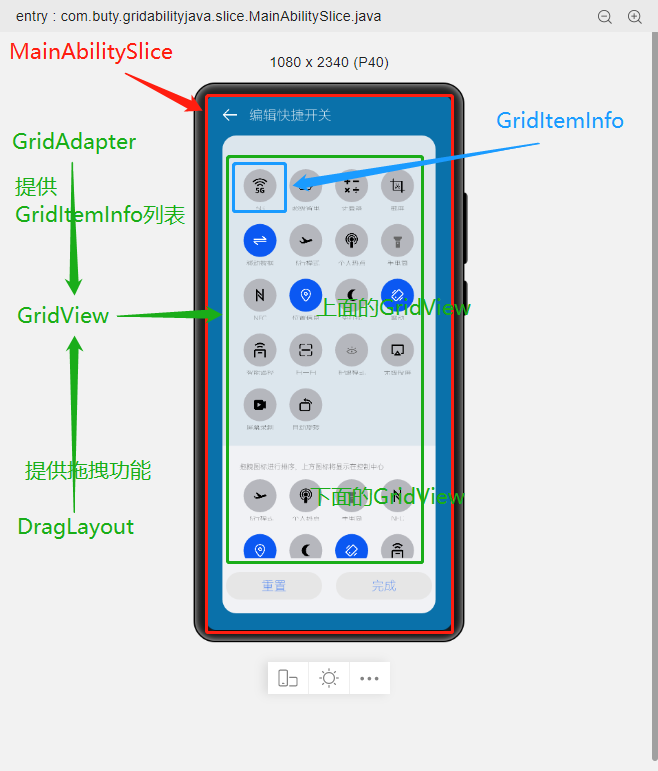 页面资源 ```json resources ├─base │ ├─element │ │ color.json │ │ float.json │ │ integer.json │ │ string.json │ │ │ ├─graphic │ │ background_bottom_button.xml #页面底部按钮形状 │ │ background_bottom_layout.xml #页面底部布局形状 │ │ background_item_active_button.xml #grid item 激活形状 │ │ background_item_button.xml #grid item 默认形状 │ │ background_table_layout_down.xml #下面的 grid 形状 │ │ background_table_layout_up.xml #上面的 grid 形状 │ │ │ ├─layout │ │ ability_main.xml #主显示页面 │ │ app_bar_layout.xml #app工具栏布局页面 │ │ grid_item.xml #单个grid item布局页面 │ │ │ ├─media │ │ 5G.png │ │ back.png │ │ back_white.png ``` ## 页面布局 ### ability_main.xml #主显示页 此页面由DirectionalLayout、StackLayout、DependentLayout 布局构成,整体布局是上下布局。 上面时app工具栏,使用了StackLayout布局,通过includ标签引入到主页面。 下面是支持拖拽的GridView,由DependentLayout 和DirectionalLayout布局组成,使用的组件有ScrollView、GridView、Text、Button、Image。 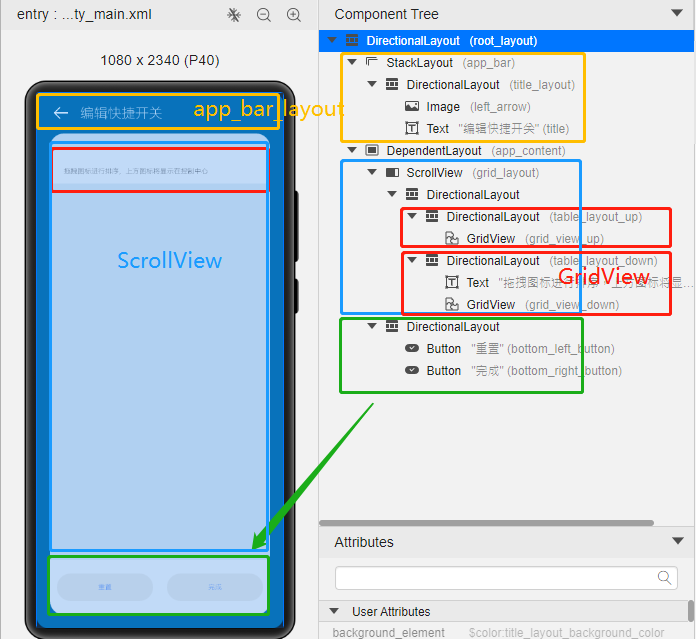 ### app_bar_layout.xml #app工具栏布局页面 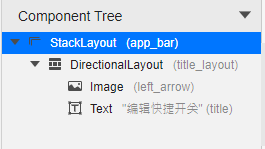 ### grid_item.xml #单个grid item布局页面 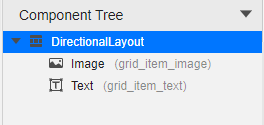 ## 后台逻辑 ### 1.初始化上面的GridView 先构建item模拟数据列表,将构建好的数据传递给GridAdapter 初始化item组件列表,通过GridView.setAdapter方法给每个item组件绑定长按事件,并设置GridView的TAG属性(TAG就是指上面的GridView还是下面的GridView)。 ```java /** * 初始化上面的Grid item */ private void initUpListItem() { //构建item模拟数据列表 List upperItemList = new ArrayList<>(); for (int i = 0; i < UP_ITEM_COUNT; i++) { int iconId = icons[i]; String text = texts[i]; upperItemList.add(new GridItemInfo(text, iconId, UP_GRID_TAG)); } GridView gridView = (GridView) slice.findComponentById(ResourceTable.Id_grid_view_up); //将构建好的数据传递给GridAdapter 初始化item组件列表 GridAdapter adapter = new GridAdapter(slice.getContext(), upperItemList); //通过GridView.setAdapter方法给每个item组件绑定长按事件 gridView.setAdapter(adapter, longClickListener); //设置GridView的TAG属性 gridView.setTag(UP_GRID_TAG); } ``` ### 2.初始化下面的GridView 逻辑同上 ```java /** * 初始化下面的Grid item */ private void initDownListItem() { String itemText = AppUtils.getStringResource(slice.getContext(), ResourceTable.String_grid_item_text); List lowerItemList = new ArrayList<>(); for (int i = 0; i < DOWN_ITEM_COUNT; i++) { //随意取的图标 int iconId = icons[i + 5]; String text = texts[i + 5]; lowerItemList.add(new GridItemInfo(text, iconId, DOWN_GRID_TAG)); } if (slice.findComponentById(ResourceTable.Id_grid_view_down) instanceof GridView) { GridView gridView = (GridView) slice.findComponentById(ResourceTable.Id_grid_view_down); GridAdapter adapter = new GridAdapter(slice.getContext(), lowerItemList); gridView.setAdapter(adapter, longClickListener); gridView.setTag(DOWN_GRID_TAG); } } ``` ### 3.初始化底部的按钮 这个地方做了一个屏幕适配,就是根据屏幕的宽度、边距来设置按钮的宽度, 同时添加了按钮的监听事件,点击按钮 关闭当前Ability。 ```java /** * Calculating button width based on screen width. * The actual width is the screen width minus the margin of the buttons. * 设置底部 2个按钮的宽度 */ private void initBottomItem() { int screenWidth = AppUtils.getScreenInfo(slice.getContext()).getPointXToInt(); //计算按钮宽度 int buttonWidth = (screenWidth - AttrHelper.vp2px(80, slice.getContext())) / 2; Component leftButton = slice.findComponentById(ResourceTable.Id_bottom_left_button); leftButton.setWidth(buttonWidth); //关闭Ability leftButton.setClickedListener(component -> slice.terminateAbility()); Component rightButton = slice.findComponentById(ResourceTable.Id_bottom_right_button); rightButton.setWidth(buttonWidth); //关闭Ability rightButton.setClickedListener(component -> slice.terminateAbility()); } ``` ### 4.初始化app工具栏 这个没做什么,似乎是想根据本地化信息,设置返回箭头的方向,因为有的语言是从右往左看的。 ```java /** * 检查指定 Locale 的文本布局是否从右到左。 * 设置返回箭头的方向 */ private void initAppBar() { if (TextTool.isLayoutRightToLeft(Locale.getDefault())) { Image appBackImg = (Image) slice.findComponentById(ResourceTable.Id_left_arrow); appBackImg.setRotation(180); } } ``` ### 5.初始化监听事件 包括返回按钮的返回事件、ScrollView的touch事件。 touch事件包含大量的细节操作,如拖拽时有一个阴影效果,滚动条的处理,拖拽交换结束的处理,过渡效果,上下grid 有效区域的计算,拖拽完成将拖拽的组件添加到对应grid的操作等,参照着拿来用吧。 ```java /** * 初始化监听事件,包括返回按钮返回事件、ScrollView的touch事件 */ private void initEventListener() { //‘返回按钮’的监听事件 if (slice.findComponentById(ResourceTable.Id_left_arrow) instanceof Image) { Image backIcon = (Image) slice.findComponentById(ResourceTable.Id_left_arrow); // backIcon.setClickedListener(component -> slice.terminateAbility()); } //ScrollView的 Touch事件监听,拿来用就可以了 scrollView.setTouchEventListener( (component, touchEvent) -> { //按下屏幕的位置 MmiPoint downScreenPoint = touchEvent.getPointerScreenPosition(touchEvent.getIndex()); switch (touchEvent.getAction()) { //表示第一根手指触摸屏幕。这表示交互的开始 case TouchEvent.PRIMARY_POINT_DOWN: currentDragX = (int) downScreenPoint.getX(); currentDragY = (int) downScreenPoint.getY(); //获取指针索引相对于偏移位置的 x 和 y 坐标。 MmiPoint downPoint = touchEvent.getPointerPosition(touchEvent.getIndex()); scrollViewTop = (int) downScreenPoint.getY() - (int) downPoint.getY(); scrollViewLeft = (int) downScreenPoint.getX() - (int) downPoint.getX(); return true; //表示最后一个手指从屏幕上抬起。这表示交互结束 case TouchEvent.PRIMARY_POINT_UP: //恢复下面grid的描述 changeTableLayoutDownDesc(ResourceTable.String_down_grid_layout_desc_text); case TouchEvent.CANCEL: if (isViewOnDrag) { selectedView.setScale(1.0f, 1.0f); selectedView.setAlpha(1.0f); selectedView.setVisibility(Component.VISIBLE); isViewOnDrag = false; isScroll = false; return true; } break; //表示手指在屏幕上移动 case TouchEvent.POINT_MOVE: if (!isViewOnDrag) { break; } int pointX = (int) downScreenPoint.getX(); int pointY = (int) downScreenPoint.getY(); this.exchangeItem(pointX, pointY); if (UP_GRID_TAG.equals(selectedView.getTag())) { this.swapItems(pointX, pointY); } this.handleScroll(pointY); return true; } return false; } ); } ``` ## 归纳总结 ### 1.自定义组件在构造函数中传递slice 这样的目的是便于获取页面的其它组件。 ```java Component itemLayout=LayoutScatter.getInstance(slice.getContext()) .parse(ResourceTable.Layout_grid_item, null, false); ``` 需要注意的是slice指代的是页面,但是自定义组件往往是有自己的布局文件的,一般不在slice中,所以不要通过slice获取自定义组件的子组件,获取不到,不过可以通过LayoutScatter获取 ```java //错误的方式 Component gridItem= slice.findComponentById(ResourceTable.Layout_grid_item); //正确的方式 Component gridItem = LayoutScatter.getInstance(context).parse(ResourceTable.Layout_grid_item, null, false); ``` ### 2.单位转换vp2px java组件对象宽高、边距的单位默认时px, 从element中获取的值需要进行单位转换,可以使用AttrHelper.vp2px 将vp转换为px。 ```java if (gridItem.findComponentById(ResourceTable.Id_grid_item_text) instanceof Text) { Text textItem = (Text) gridItem.findComponentById(ResourceTable.Id_grid_item_text); textItem.setText(item.getItemText()); textItem.setTextSize(AttrHelper.fp2px(10, context)); } ``` ### 3.子组件的获取 获取一个组件对象后,可以使用该组件对象的findComponentById方法继续获取内部的子组件 ```java Component gridItem = LayoutScatter.getInstance(context).parse(ResourceTable.Layout_grid_item, null, false); Image imageItem = (Image) gridItem.findComponentById(ResourceTable.Id_grid_item_image); ``` ### 4.TableLayout的使用 TableLayout继承自ComponentContainer,提供用于在带有表格的组件中排列组件的布局。 TableLayout 提供了用于对齐和排列组件的接口,以在带有表格的组件中显示组件。 排列方式、行列数、元件位置均可配置。 例如 removeAllComponents();可以用来清除 ComponentContainer 管理的所有组件,addComponent 用来将组件添加到ComponentContainer 容器中。示例中GridView就是继承自TableLayout。 ```java /** * The setAdapter * * @param adapter adapter * @param longClickedListener longClickedListener */ void setAdapter(GridAdapter adapter, LongClickedListener longClickedListener) { //清除 ComponentContainer 管理的所有组件 removeAllComponents(); //遍历item组件列表 for (int i = 0; i < adapter.getComponentList().size(); i++) { //为组件中的长按事件注册一个监听器(组件被点击并按住) adapter.getComponentList().get(i).setLongClickedListener(longClickedListener); //将组件添加到容器中 addComponent(adapter.getComponentList().get(i)); } } ``` ## 效果展示 示例代码模拟了一下手机控制中心,编辑快捷开关的效果 |原效果|模拟效果| |-|-| |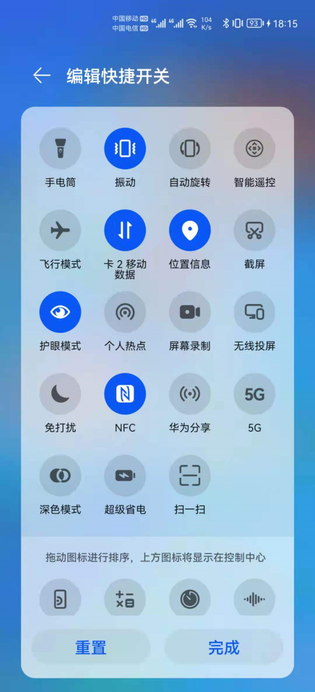|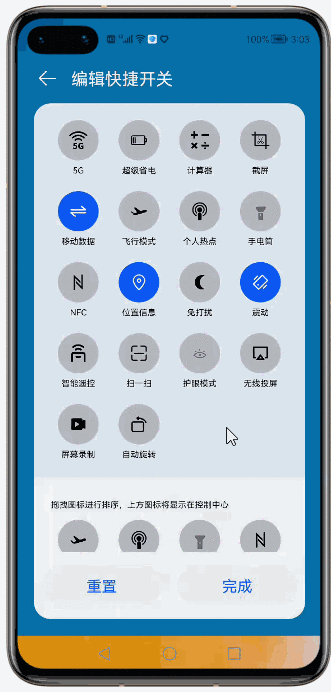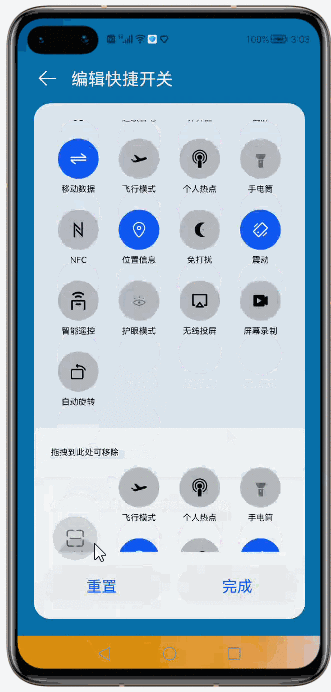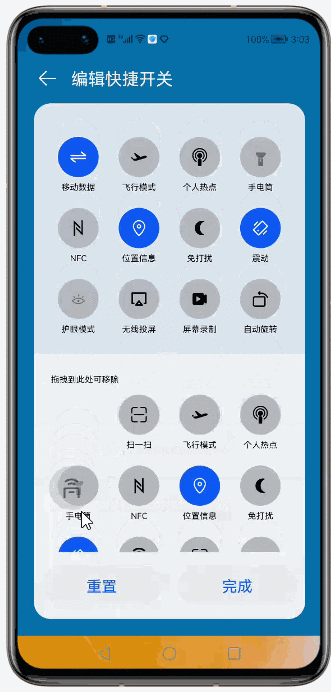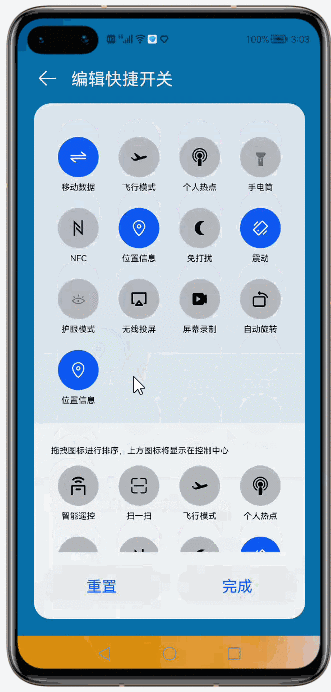| ## 完整代码 文章相关附件可以点击下面的原文链接前往下载 原文链接:https://harmonyos.51cto.com/posts/6257#bkwz