CentOS7.x Hadoop集群搭建
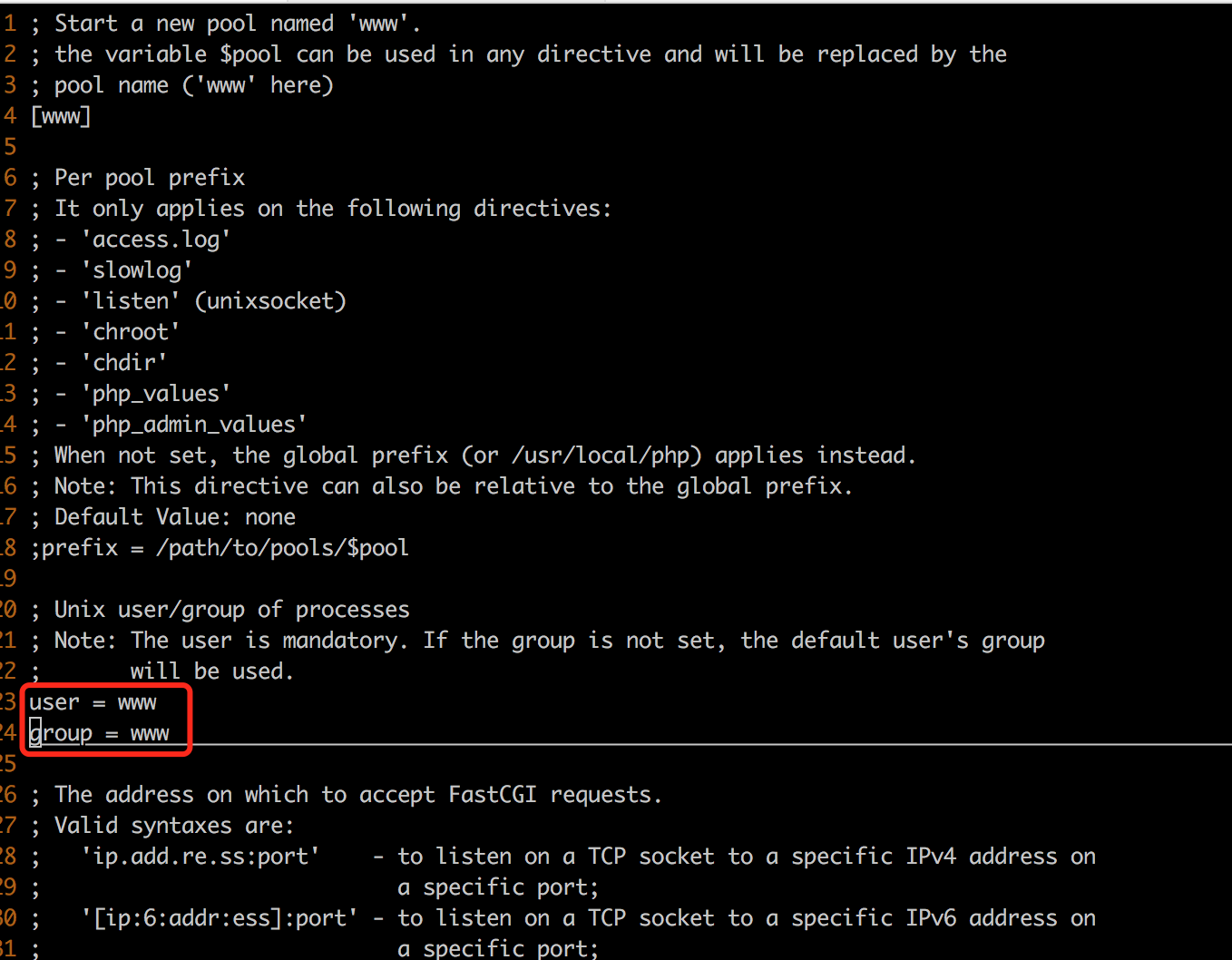
1. 准备工作 我有一个主机ip是192.168.27.166,我将再此基础上再扩展三个主机。 修改主机名 /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.27.166 s166 192.168.27.167 s167 192.168.27.168 s168 192.168.27.169 s169 其中,我将把s166作为名称节点(NameNode),其它三个作为数据节点(DataNode)。 修改hostname etc/hostname 2. 克隆虚拟机 略 3. 修改数据节点的hostname和ip地址 编辑/etc/sysconfig/network-scripts/ifcfg-eno33 编辑/etc/hostname 重启网络服务 service network restart 验证通信是否完成 [root@s166 etc]# ping s167 PING s167 (192.168.27.167) 56(84) bytes of data. 64 bytes from s167 (192.168.27.167): icmp_seq=1 ttl=64 time=0.245 ms [root@s166 etc]# ping s168 PING s168 (192.168.27.168) 56(84) bytes of data. 64 bytes from s168 (192.168.27.168): icmp_seq=1 ttl=64 time=0.203 ms [root@s166 etc]# ping s169 PING s169 (192.168.27.169) 56(84) bytes of data. 64 bytes from s169 (192.168.27.169): icmp_seq=1 ttl=64 time=0.178 ms 4. 各主机间无密码通信 SSH无密码登录设置 将s166的公钥文件id_rsa.pub远程复制到167-169主机上 测试是否配置成功 [root@s166 etc]# ssh s167 Last failed login: Wed Jul 25 15:50:22 EDT 2018 on tty1 There was 1 failed login attempt since the last successful login. Last login: Wed Jul 25 10:36:57 2018 from s166 [root@s167 ~]# ... Hadoop的4+1个文件配置 hadoop的配置文件都在/hadoop/etc/hadoop下 1. core-site.xml 设置hdfs://s166为服务器ip地址 <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://s166/</value> </property> </configuration> 2. hdfs-site.xml 分片数量设置为3 <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.replication</name> <value>3</value> </property> </configuration> 3. mapred-site.xml.template 先mapred-site.xml.template mapred-site.xml,然后对mapred-site.xml做修改执行框架设置为Hadoop YARN <?xml version="1.0"?> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> 4. yarn-site.xml RM的hostname设置为s166 <?xml version="1.0"?> <configuration> <property> <name>yarn.resourcemanager.hostname</name> <value>s166</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> 5. slaves s167 s168 s169 修改etc/hadoop/hadoop-env.sh配置 把该文件中的export JAVA_HOME属性修改成JAVA_HOME的绝对路径。 export JAVA_HOME=/home/fantj/jdk 配置分发 进入到hadoop/etc目录下,把该目录下的hadoop覆盖到各个主机。 scp -r hadoop/ root@s167:/home/fantj/hadoop/etc/ scp -r hadoop/ root@s168:/home/fantj/hadoop/etc/ scp -r hadoop/ root@s169:/home/fantj/hadoop/etc/ 格式化文件系统 hadoop namenode -format [root@s166 etc]# hadoop namenode -format DEPRECATED: Use of this script to execute hdfs command is deprecated. Instead use the hdfs command for it. 18/07/27 04:17:36 INFO namenode.NameNode: STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = s166/192.168.27.166 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.7.0 STARTUP_MSG: classpath = /home/fantj/download/hadoop-2.7.0/etc/hadoop:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-cli-1.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jetty-util-6.1.26.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/stax-api-1.0-2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-configuration-1.6.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/log4j-1.2.17.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/asm-3.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/servlet-api-2.5.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/hadoop-auth-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jsr305-3.0.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jsp-api-2.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/avro-1.7.4.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jetty-6.1.26.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/curator-framework-2.7.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-logging-1.1.3.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-net-3.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-math3-3.1.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jersey-server-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jets3t-0.9.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-compress-1.4.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/hadoop-annotations-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/gson-2.2.4.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jersey-json-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/activation-1.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/httpcore-4.2.5.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-codec-1.4.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/curator-client-2.7.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-lang-2.6.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-collections-3.2.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/paranamer-2.3.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/zookeeper-3.4.6.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jsch-0.1.42.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-io-2.4.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-httpclient-3.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jettison-1.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/xz-1.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/netty-3.6.2.Final.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/junit-4.11.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/httpclient-4.2.5.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/jersey-core-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/guava-11.0.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/commons-digester-1.8.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/hamcrest-core-1.3.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/xmlenc-0.52.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/mockito-all-1.8.5.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/hadoop-common-2.7.0-tests.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/hadoop-common-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/common/hadoop-nfs-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/asm-3.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/commons-io-2.4.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/guava-11.0.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/hadoop-hdfs-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/hdfs/hadoop-hdfs-2.7.0-tests.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/commons-cli-1.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/aopalliance-1.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/log4j-1.2.17.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/asm-3.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/servlet-api-2.5.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jersey-client-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/guice-3.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jetty-6.1.26.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jersey-server-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jersey-json-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/activation-1.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/commons-codec-1.4.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/commons-lang-2.6.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/commons-collections-3.2.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/commons-io-2.4.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jettison-1.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/xz-1.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/javax.inject-1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/jersey-core-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/lib/guava-11.0.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-server-common-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-client-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-registry-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-common-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/yarn/hadoop-yarn-api-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/asm-3.2.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/guice-3.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/xz-1.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/javax.inject-1.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/junit-4.11.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.0-tests.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.0.jar:/home/fantj/download/hadoop-2.7.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar:/home/fantj/hadoop/contrib/capacity-scheduler/*.jar:/home/fantj/download/hadoop-2.7.0/contrib/capacity-scheduler/*.jar STARTUP_MSG: build = Unknown -r Unknown; compiled by 'root' on 2015-05-21T03:49Z STARTUP_MSG: java = 1.8.0_171 ************************************************************/ 18/07/27 04:17:36 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT] 18/07/27 04:17:36 INFO namenode.NameNode: createNameNode [-format] Formatting using clusterid: CID-75fa7946-8fa3-4b09-83c4-00ec91f5f0b6 18/07/27 04:17:39 INFO namenode.FSNamesystem: No KeyProvider found. 18/07/27 04:17:39 INFO namenode.FSNamesystem: fsLock is fair:true 18/07/27 04:17:39 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000 18/07/27 04:17:39 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true 18/07/27 04:17:39 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000 18/07/27 04:17:39 INFO blockmanagement.BlockManager: The block deletion will start around 2018 Jul 27 04:17:39 18/07/27 04:17:39 INFO util.GSet: Computing capacity for map BlocksMap 18/07/27 04:17:39 INFO util.GSet: VM type = 64-bit 18/07/27 04:17:39 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB 18/07/27 04:17:39 INFO util.GSet: capacity = 2^21 = 2097152 entries 18/07/27 04:17:39 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false 18/07/27 04:17:39 INFO blockmanagement.BlockManager: defaultReplication = 3 18/07/27 04:17:39 INFO blockmanagement.BlockManager: maxReplication = 512 18/07/27 04:17:39 INFO blockmanagement.BlockManager: minReplication = 1 18/07/27 04:17:39 INFO blockmanagement.BlockManager: maxReplicationStreams = 2 18/07/27 04:17:39 INFO blockmanagement.BlockManager: shouldCheckForEnoughRacks = false 18/07/27 04:17:39 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000 18/07/27 04:17:39 INFO blockmanagement.BlockManager: encryptDataTransfer = false 18/07/27 04:17:39 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000 18/07/27 04:17:39 INFO namenode.FSNamesystem: fsOwner = root (auth:SIMPLE) 18/07/27 04:17:39 INFO namenode.FSNamesystem: supergroup = supergroup 18/07/27 04:17:39 INFO namenode.FSNamesystem: isPermissionEnabled = true 18/07/27 04:17:39 INFO namenode.FSNamesystem: HA Enabled: false 18/07/27 04:17:39 INFO namenode.FSNamesystem: Append Enabled: true 18/07/27 04:17:40 INFO util.GSet: Computing capacity for map INodeMap 18/07/27 04:17:40 INFO util.GSet: VM type = 64-bit 18/07/27 04:17:40 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB 18/07/27 04:17:40 INFO util.GSet: capacity = 2^20 = 1048576 entries 18/07/27 04:17:40 INFO namenode.FSDirectory: ACLs enabled? false 18/07/27 04:17:40 INFO namenode.FSDirectory: XAttrs enabled? true 18/07/27 04:17:40 INFO namenode.FSDirectory: Maximum size of an xattr: 16384 18/07/27 04:17:40 INFO namenode.NameNode: Caching file names occuring more than 10 times 18/07/27 04:17:40 INFO util.GSet: Computing capacity for map cachedBlocks 18/07/27 04:17:40 INFO util.GSet: VM type = 64-bit 18/07/27 04:17:40 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB 18/07/27 04:17:40 INFO util.GSet: capacity = 2^18 = 262144 entries 18/07/27 04:17:40 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033 18/07/27 04:17:40 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0 18/07/27 04:17:40 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000 18/07/27 04:17:40 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10 18/07/27 04:17:40 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10 18/07/27 04:17:40 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25 18/07/27 04:17:40 INFO namenode.FSNamesystem: Retry cache on namenode is enabled 18/07/27 04:17:40 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis 18/07/27 04:17:40 INFO util.GSet: Computing capacity for map NameNodeRetryCache 18/07/27 04:17:40 INFO util.GSet: VM type = 64-bit 18/07/27 04:17:40 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB 18/07/27 04:17:40 INFO util.GSet: capacity = 2^15 = 32768 entries 18/07/27 04:17:40 INFO namenode.FSImage: Allocated new BlockPoolId: BP-703568763-192.168.27.166-1532679460786 18/07/27 04:17:40 INFO common.Storage: Storage directory /tmp/hadoop-root/dfs/name has been successfully formatted. 18/07/27 04:17:41 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 18/07/27 04:17:41 INFO util.ExitUtil: Exiting with status 0 18/07/27 04:17:41 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at s166/192.168.27.166 ************************************************************/ 启动hadoop进程 start-all.sh [root@s166 etc]# start-all.sh This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh Starting namenodes on [s166] The authenticity of host 's166 (192.168.27.166)' can't be established. ECDSA key fingerprint is SHA256:3BePLPmiwUOy025LcIJJNvQJlKUJ3uo9T03op0XC5ws. ECDSA key fingerprint is MD5:24:ee:b2:a8:cf:df:9d:f7:cc:6c:1f:73:c5:ad:b5:b0. Are you sure you want to continue connecting (yes/no)? yes s166: Warning: Permanently added 's166,192.168.27.166' (ECDSA) to the list of known hosts. root@s166's password: s166: starting namenode, logging to /home/fantj/download/hadoop-2.7.0/logs/hadoop-root-namenode-s166.out s167: starting datanode, logging to /home/fantj/download/hadoop-2.7.0/logs/hadoop-root-datanode-s167.out s169: starting datanode, logging to /home/fantj/download/hadoop-2.7.0/logs/hadoop-root-datanode-s169.out s168: starting datanode, logging to /home/fantj/download/hadoop-2.7.0/logs/hadoop-root-datanode-s168.out Starting secondary namenodes [0.0.0.0] The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established. ECDSA key fingerprint is SHA256:3BePLPmiwUOy025LcIJJNvQJlKUJ3uo9T03op0XC5ws. ECDSA key fingerprint is MD5:24:ee:b2:a8:cf:df:9d:f7:cc:6c:1f:73:c5:ad:b5:b0. Are you sure you want to continue connecting (yes/no)? yes 0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts. root@0.0.0.0's password: 0.0.0.0: starting secondarynamenode, logging to /home/fantj/download/hadoop-2.7.0/logs/hadoop-root-secondarynamenode-s166.out starting yarn daemons starting resourcemanager, logging to /home/fantj/download/hadoop-2.7.0/logs/yarn-root-resourcemanager-s166.out s168: starting nodemanager, logging to /home/fantj/download/hadoop-2.7.0/logs/yarn-root-nodemanager-s168.out s167: starting nodemanager, logging to /home/fantj/download/hadoop-2.7.0/logs/yarn-root-nodemanager-s167.out s169: starting nodemanager, logging to /home/fantj/download/hadoop-2.7.0/logs/yarn-root-nodemanager-s169.out 配置成功校验 根据控制台打印信息查看 s166: starting namenode, logging to /home/fantj/download/hadoop-2.7.0/logs/hadoop-root-namenode-s166.out s167: starting datanode, logging to /home/fantj/download/hadoop-2.7.0/logs/hadoop-root-datanode-s167.out s169: starting datanode, logging to /home/fantj/download/hadoop-2.7.0/logs/hadoop-root-datanode-s169.out s168: starting datanode, logging to /home/fantj/download/hadoop-2.7.0/logs/hadoop-root-datanode-s168.out starting resourcemanager, logging to /home/fantj/download/hadoop-2.7.0/logs/yarn-root-resourcemanager-s166.out s168: starting nodemanager, logging to /home/fantj/download/hadoop-2.7.0/logs/yarn-root-nodemanager-s168.out s167: starting nodemanager, logging to /home/fantj/download/hadoop-2.7.0/logs/yarn-root-nodemanager-s167.out s169: starting nodemanager, logging to /home/fantj/download/hadoop-2.7.0/logs/yarn-root-nodemanager-s169.out 有报错的话,去查看日志分析。 NameNode主机校验 [root@s166 etc]# jps 1397 NameNode 1559 SecondaryNameNode 1815 Jps 1727 ResourceManager DataNode主机校验 [root@s168 ~]# jps 11281 Jps 1815 NodeManager 1756 DataNode