时序数据库Influx-IOx源码学习十一(SQL的解析)
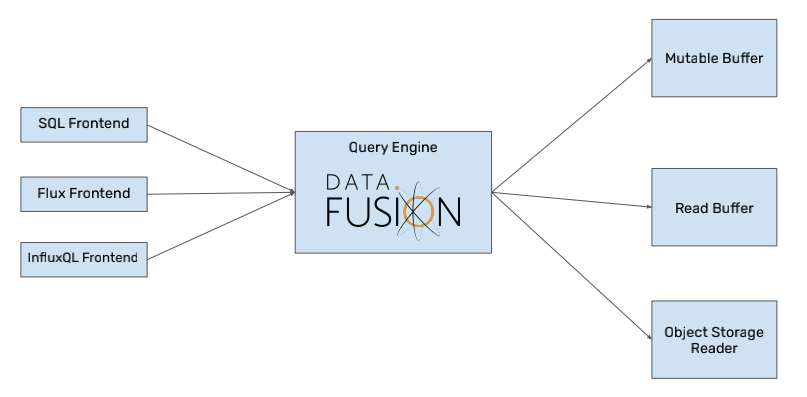
InfluxDB是一个由InfluxData开发的开源时序数据库,专注于海量时序数据的高性能读、写、高效存储与实时分析等,在DB-Engines Ranking时序型数据库排行榜上常年排名第一。 InfluxDB可以说是当之无愧的佼佼者,但 InfluxDB CTO Paul 在 2020/12/10 号在博客中发表一篇名为:Announcing InfluxDB IOx – The Future Core of InfluxDB Built with Rust and Arrow的文章,介绍了一个新项目 InfluxDB IOx,InfluxDB 的下一代时序引擎。 接下来,我将连载对于InfluxDB IOx的源码解析过程,欢迎各位批评指正,联系方式见文章末尾。 上一章介绍了查询的主流程,详情见: https://my.oschina.net/u/3374539/blog/5034513 这章记录一下SQL的解析过程。 Influx Iox 使用了 Fusion 作为sql的查询引擎(Funsion目前是apache arrow的一个子项目)。整体查询架构如图所示: 我在网上找了找Fusion相关的文档,没有找到比较详细一些的说明,所以只能自己总结了。 通常来讲,sql的语句解析分为两个大的步骤,分别是: 逻辑执行计划(LogicPlan) 物理执行计划(PhysicalPlan) 逻辑执行计划(LogicPlan) LogicPlan主要是用来描述用户输入的SQL都包含了一些什么内容,例如: selet * from table where a = 1 ,要转换到类能解释的模型上就会成为: class SelectClass{ path : "*", from: "table", where: eq(a , 1) } 这是非常简单的情况,sql中还会掺杂大量的关键字,比如SUM、JOIN、ORDER BY等等,如果需要把所有东西都记录下来,可能类图看起来就像是这样: 在Fusion中,有一个名为parser.rs的解析器他的主要工作就是将纯SQL解析为一个程序基本可以理解的结构。主要过程有: 定义所有的关键词,能够识别出来在sql语句中的含义。比如 SELECT、INSERT 等等 遍历sql语句每个空格或者遇到表达式切分一次,然后在定义的关键词里查找是否为关键字 使用一个名叫TOKEN的枚举来表示每个节点不同的含义,比如EQ,NEQ,COMMA等等 最后存储到一个数组当中,数据结构大致如下: Ok([Word(Word { value: "select", quote_style: None, keyword: SELECT }), Whitespace(Space), Mult, Whitespace(Space), Word(Word { value: "from", quote_style: None, keyword: FROM }), Whitespace(Space), Word(Word { value: "table1", quote_style: None, keyword: NoKeyword }), Whitespace(Space), Word(Word { value: "where", quote_style: None, keyword: WHERE }), Whitespace(Space), Word(Word { value: "a", quote_style: None, keyword: NoKeyword }), Whitespace(Space), Eq, Whitespace(Space), Number("1", false)]) 按照不同的开头关键字去执行不同的分支。比如CREATE 和 SELECT 肯定后面的解析方式不一样。 封装成不同的LogicPlan子类。 pub enum LogicalPlan { //基本就是纯select Projection { ... 省略 }, //带有filter的 Filter { ... 省略 }, //是聚合的 Aggregate { ... 省略 }, //带排序的 Sort { ... 省略 }, ... 省略 } 逻辑执行计划的优化 在用户输入一段sql之后,往往他并不会意识到自己是否真的输入了非常有意义的东西,并且他也不会清楚程序到底用什么样的组织方式会让程序执行的更快,所以一般来讲,用户输入的sql是最不可信的,还需要再次执行优化。 举个简单的例子,假如用户输入select * from table where is_valid = true and is_valid !=false ,很明显可以在执行前优化成 select * from table where is_valid = true,从而减少在实际执行时,对数据库的操作。 从图中可以看到Fusion提供了5种优化,有兴趣的的可以自己了解,或者以后再做分析。 物理执行计划 物理执行计划,我理解就是将用户输入的文字性描述的信息专为真正的资源来存储,比如用户写入的是from t1,那么t1作为一个字符串存在于logic阶段,但是到物理阶段的时候,要从内存或者磁盘上取来真正指向物理资源的一个类型,存储到计划里,以备后用。 例如下面的示例当中,就是一段物理执行计划,他从上面的Projection存储的各种字符串,转换到了存储表对应的schema,以及RBChunk类型。 pub(crate) struct IOxReadFilterNode<C: PartitionChunk + 'static> { table_name: Arc<String>, schema: SchemaRef, chunk_and_infos: Vec<ChunkInfo<C>>, predicate: Predicate, } 物理执行计划的优化 对于物理计划Fasion中提供了3种优化方式,如下图: 分别是批处理、分区合并、并行度优化。主要是为了在实际实行的过程中,减少因为通讯、调用、单机等造成的响应缓慢。 在文章的最后展示一下一个物理执行之计划都包含了哪些信息: ProjectionExec { expr: [ (Column { name: "fieldKey" }, "fieldKey"), (Column { name: "tag1" }, "tag1"), (Column { name: "tag2" }, "tag2"), (Column { name: "time" }, "time")], schema: Schema { fields: [Field { name: "fieldKey", data_type: Utf8, nullable: true, dict_id: 0, dict_is_ordered: false, metadata: None }, Field { name: "tag1", data_type: Dictionary(Int32, Utf8), nullable: true, dict_id: 0, dict_is_ordered: false, metadata: None }, Field { name: "tag2", data_type: Dictionary(Int32, Utf8), nullable: true, dict_id: 0, dict_is_ordered: false, metadata: None }, Field { name: "time", data_type: Timestamp(Nanosecond, None), nullable: false, dict_id: 0, dict_is_ordered: false, metadata: None }], metadata: {} }, input: RepartitionExec { input: IOxReadFilterNode { table_name: "myMeasurement", schema: Schema { fields: [Field { name: "fieldKey", data_type: Utf8, nullable: true, dict_id: 0, dict_is_ordered: false, metadata: None }, Field { name: "tag1", data_type: Dictionary(Int32, Utf8), nullable: true, dict_id: 0, dict_is_ordered: false, metadata: None }, Field { name: "tag2", data_type: Dictionary(Int32, Utf8), nullable: true, dict_id: 0, dict_is_ordered: false, metadata: None }, Field { name: "time", data_type: Timestamp(Nanosecond, None), nullable: false, dict_id: 0, dict_is_ordered: false, metadata: None }], metadata: {} }, chunk_and_infos: [ChunkInfo { chunk_table_schema: Schema { inner: Schema { fields: [Field { name: "fieldKey", data_type: Utf8, nullable: true, dict_id: 0, dict_is_ordered: false, metadata: None }, Field { name: "tag1", data_type: Dictionary(Int32, Utf8), nullable: true, dict_id: 0, dict_is_ordered: false, metadata: None }, Field { name: "tag2", data_type: Dictionary(Int32, Utf8), nullable: true, dict_id: 0, dict_is_ordered: false, metadata: None }, Field { name: "time", data_type: Timestamp(Nanosecond, None), nullable: false, dict_id: 0, dict_is_ordered: false, metadata: None }], metadata: {"tag2": "iox::column_type::tag", "time": "iox::column_type::timestamp", "fieldKey": "iox::column_type::field::string", "tag1": "iox::column_type::tag"} } }, chunk: MutableBuffer { 。。。省略MBChunk数据 } } 就到这里,祝玩儿的开心。 欢迎关注微信公众号: 或添加微信好友: liutaohua001