Hadoop MapReduce概念学习系列之mr程序组件全貌(二十)
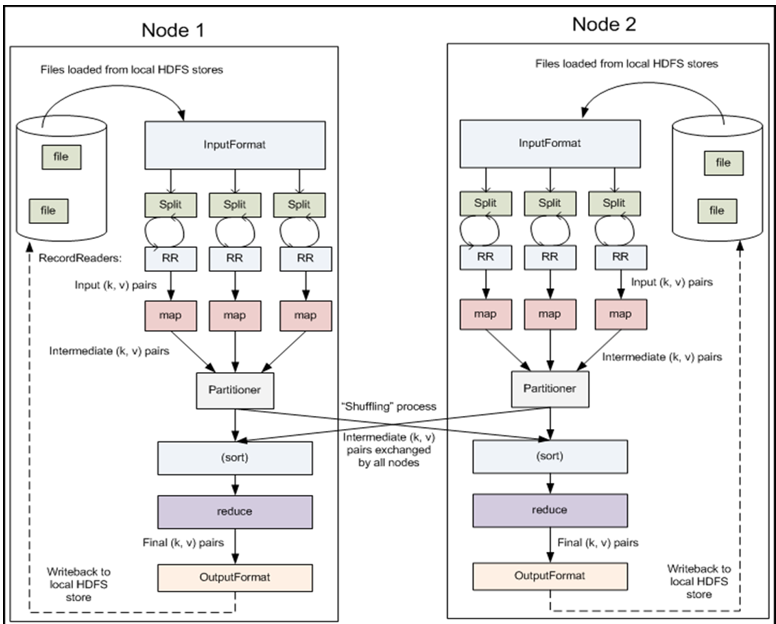
其实啊,spilt是,控制Apache Hadoop Mapreduce的map并发任务数,详细见http://www.cnblogs.com/zlslch/p/5713652.html map,是mapper代码 reduce,是reducer代码 缓存,分组,排序,转发, 最重要的是,mr程序的组件InputFormat和OutputFormat啊!(重要的话,说三遍) 最重要的是,mr程序的组件InputFormat和OutputFormat啊! 最重要的是,mr程序的组件InputFormat和OutputFormat啊! 我们知道,在大数据里,数据源是非常之广,比如,hdfs(默认,而且还是TextInputFormat),数据库,文件,ftp,网页,网络端口..... 那么,对于用户来说,不需要具体去管,特推出mr程序的组件-------InputFormat 往数据库、HBase、ftp、hdfs(默认是往hdfs写,而且还是TextOutputFormat),文件,,,用户不用管,特推出mr程序的组件------OutputFormat But,在生产环境,可是最重要的是具体业务... 注意: 比如,对于图片,视频,,,这些,InputFormat,就不能了。 可以看到,DBInputFormat是去数据库里读, 可以看到,DBOutputFormat是往数据库里写。 其它更深以后会补上。。。。。 本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/5713872.html,如需转载请自行联系原作者