Unity C#基础之 反射反射,程序员的快乐
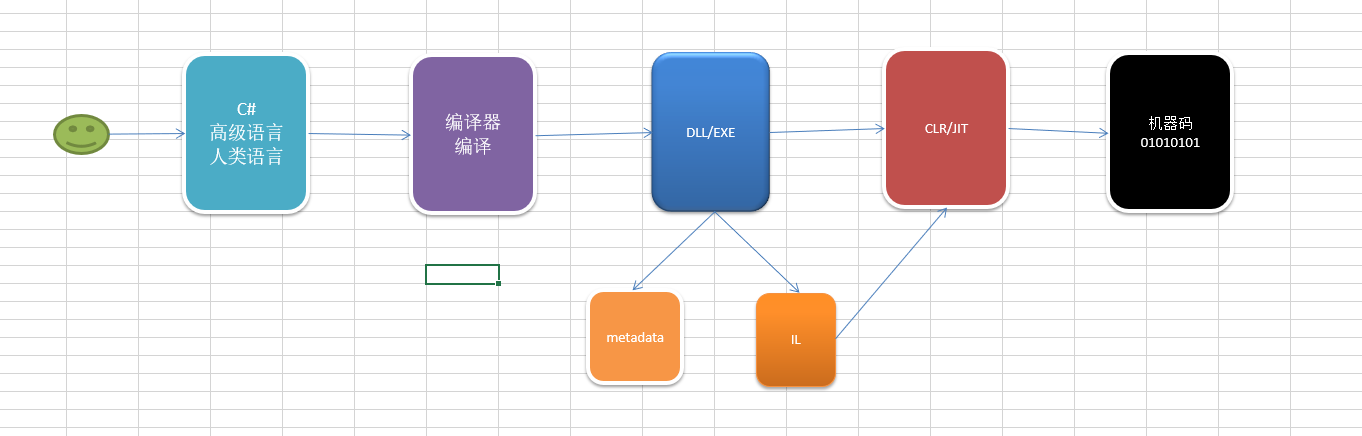
反射反射,程序员的快乐 这句话想必大家都经常听过,基本上在绝大多数的框架和一些设计模式中都能看到反射的身影(MVC、IOC、AOP、O/RM), 反射:是.Net Framework提供的一个帮助类库,可以访问dll的metadata,并且使用它。 反射给我们带来的优缺点如下: 极大的解耦 动态创建 代码多编写量大 避开编译器的检查 性能问题 反射性能要差普通的400+倍 但是绝对值小,几乎不影响项目性能 而且还可以优化,空间换时间(非常适合泛型缓存) 下面一些示例介绍一些反射比较实用的基本用法 (Unity版本:2017.3.0 P4 .NET 4.6) 示例工程下载 using System; using System.Collections; using System.Collections.Generic; using System.Reflection; using UnityEngine; public class InvokeReflection : MonoBehaviour { void Start() { Learn00(); } public void Learn00() { /* *System.Reflection.Assembly类有两个静态方法:Assembly.Load(string assemblyname)和Assembly.LoadFrom(string filename) 。 * 通常用这两个方法把程序集加载到应用程序域中。 如果你希望加载的程序集超出了CLR的预定探查范围,你可以用 Assembly.LoadFrom直接从一个文件位置加载程序集。 * Assembly.LoadFrom()和Assembly.LoadFile(),两者的主要区别有两点: * 一:Assembly.LoadFile()只载入指定的dll文件,而不会自动加载相关的dll文件。如果下文例子使用Assembly.LoadFile()加载SayHello.dll,那么程序就只会加载 * SayHello.dll而不会去加载SayHello.dll引用的BaseClass.dll文件。 *二:用Assembly.LoadFrom()载入一个Assembly时,会先检查前面是否已经载入过相同名字的Assembly; * 而Assembly.LoadFile()则不会做类似的检查。 */ //C:\Users\Administrator\Desktop\New Unity Project\Assets\DLL Assembly assemly2 = Assembly.LoadFrom(@"C:\Users\Administrator\Desktop\New Unity Project\Assets\Scripts\TestReflection.dll"); Assembly assemly1 = Assembly.LoadFile(@"C:\Users\Administrator\Desktop\New Unity Project\Assets\Scripts\TestReflection.dll"); Assembly assemly = Assembly.Load("TestReflection");//1填加DLL Type testType = assemly.GetType("HaiLan.TestReflection.TestReflectionDLL");//2获取对应的类信息,需要填加对应的命名空间 object oTestReflectionDLL = Activator.CreateInstance(testType);//3 创建对象 IReflectionDLL iTestReflectionDLL = oTestReflectionDLL as IReflectionDLL;//4 类型转换 iTestReflectionDLL.TestShow1();//5 方法调用 foreach (var item in assemly.GetModules()) { Debug.Log(item.Name);//打印结果 TestReflection.dll } foreach (var type in assemly.GetTypes()) { Debug.Log(type.Name); foreach (var item in type.GetMethods()) { Debug.Log(item.Name); } } } } 运行结果如下: public void Learn01() { Console.WriteLine("************************Reflection*****************"); Assembly assemly = Assembly.Load("TestReflection"); Type testType = assemly.GetType("HaiLan.TestReflection.TestReflectionDLL"); object oTest1 = Activator.CreateInstance(testType); object oTest2 = Activator.CreateInstance(testType, new object[] { }); object oTest3 = Activator.CreateInstance(testType, new object[] { 9257 }); object oTest4 = Activator.CreateInstance(testType, new object[] { "海澜" }); Type genericType = assemly.GetType("HaiLan.TestReflection.GenericClass`3");//泛型类还有3个未指定的类型 Type genericNewType = genericType.MakeGenericType(typeof(int), typeof(string), typeof(InvokeReflection)); object oGeneric = Activator.CreateInstance(genericNewType); GenericClass<int,string, InvokeReflection> TempGenericClass = oGeneric as GenericClass<int, string, InvokeReflection>; TempGenericClass.Show(9257,"海澜", this); Type singletonType = assemly.GetType("HaiLan.TestReflection.Singleton"); object oSingleton1 = Activator.CreateInstance(singletonType, true);//单例模型依然可以创建新类 object oSingleton2 = Activator.CreateInstance(singletonType, true); object oSingleton3 = Activator.CreateInstance(singletonType, true); } 运行结果如下: public void Learn02() { Assembly assemly = Assembly.Load("TestReflection"); Type testType = assemly.GetType("HaiLan.TestReflection.ReflectionTest"); object oTest = Activator.CreateInstance(testType); { MethodInfo method = testType.GetMethod("Show1");//以前写的具体方法,换成字符串 method.Invoke(oTest, null); } { MethodInfo method = testType.GetMethod("Show2");//带参数 method.Invoke(oTest, new object[] { 9257 }); } { MethodInfo method = testType.GetMethod("Show5");//静态 method.Invoke(oTest, new object[] { "海澜" }); method.Invoke(null, new object[] { "海澜" }); } { MethodInfo method = testType.GetMethod("Show3", new Type[] { });//重载方法 method.Invoke(oTest, new object[] { }); } { MethodInfo method = testType.GetMethod("Show3", new Type[] { typeof(int) });//重载方法 method.Invoke(oTest, new object[] { 9257 }); } { MethodInfo method = testType.GetMethod("Show3", new Type[] { typeof(string) });//重载方法 method.Invoke(oTest, new object[] { "海澜" }); } { MethodInfo method = testType.GetMethod("Show3", new Type[] { typeof(int), typeof(string) });//重载方法 method.Invoke(oTest, new object[] { 9257, "海澜" }); } { MethodInfo method = testType.GetMethod("Show3", new Type[] { typeof(string), typeof(int) });//重载方法 method.Invoke(oTest, new object[] { "海澜", 9257 }); } { MethodInfo method = testType.GetMethod("Show4", BindingFlags.Instance | BindingFlags.NonPublic);//私有方法 method.Invoke(oTest, new object[] { "海澜" }); } { Type genericType = assemly.GetType("HaiLan.TestReflection.GenericMethod"); object oGeneric = Activator.CreateInstance(genericType); MethodInfo method = genericType.GetMethod("Show"); //MethodInfo method = genericType.GetMethod("Show`3");//错误写法,应为在编译期间就是无法通过的 MethodInfo methodNew = method.MakeGenericMethod(typeof(int), typeof(string), typeof(int)); methodNew.Invoke(oGeneric, new object[] { 9257, "海澜", 92570 }); } } 运行结果如下: public void Learn03() { { People people = new People(); people.Id = 9257; people.Name = "海澜"; people.Description = "菜鸟海澜"; Debug.Log($"people.Id={people.Id}"); Debug.Log($"people.Name={people.Name}"); Debug.Log($"people.Description={people.Description}"); } { Type type = typeof(People); object oPeople = Activator.CreateInstance(type); foreach (var item in type.GetProperties())//反射可以给对象的属性 动态 赋值/获取值, { Debug.Log(item.Name); Debug.Log(item.GetValue(oPeople)); if (item.Name.Equals("Id")) { item.SetValue(oPeople, 1235); } else if (item.Name.Equals("Name")) { item.SetValue(oPeople, "菜鸟海澜"); } Debug.Log(item.GetValue(oPeople)); } foreach (var item in type.GetFields())//反射可以给对象的字段 动态 赋值/获取值, { Debug.Log(item.Name); Debug.Log(item.GetValue(oPeople)); if (item.Name.Equals("Description")) item.SetValue(oPeople, "菜鸟海澜,ID:9257"); Debug.Log(item.GetValue(oPeople)); } } } 运行结果如下: 反射介绍如下: 反射是.NET中的重要机制,通过反射,可以在运行时获得程序或程序集中每一个类型(包括类、结构、委托、接口和枚举等)的成员和成员的信息。有了反射,即可对每一个类型了如指掌。另外我还可以直接创建对象,即使这个对象的类型在编译时还不知道。 反射的用途: 使用Assembly定义和加载程序集,加载在程序集清单中列出模块,以及从此程序集中查找类型并创建该类型的实例。 使用Module了解包含模块的程序集以及模块中的类等,还可以获取在模块上定义的所有全局方法或其他特定的非全局方法。 使用ConstructorInfo了解构造函数的名称、参数、访问修饰符(如pulic 或private)和实现详细信息(如abstract或virtual)等。 使用MethodInfo了解方法的名称、返回类型、参数、访问修饰符(如pulic 或private)和实现详细信息(如abstract或virtual)等。 使用FiedInfo了解字段的名称、访问修饰符(如public或private)和实现详细信息(如static)等,并获取或设置字段值。 使用EventInfo了解事件的名称、事件处理程序数据类型、自定义属性、声明类型和反射类型等,添加或移除事件处理程序。 使用PropertyInfo了解属性的名称、数据类型、声明类型、反射类型和只读或可写状态等,获取或设置属性值。 使用ParameterInfo了解参数的名称、数据类型、是输入参数还是输出参数,以及参数在方法签名中的位置等。 反射用到的命名空间: System.Reflection System.Type System.Reflection.Assembly 反射用到的主要类: System.Type 类--通过这个类可以访问任何给定数据类型的信息。 System.Reflection.Assembly类--它可以用于访问给定程序集的信息,或者把这个程序集加载到程序中。 System.Type类: System.Type 类对于反射起着核心的作用。但它是一个抽象的基类,Type有与每种数据类型对应的派生 类,我们使用这个派生类的对象的方法、字段、属性来查找有关该类型的所有信息。 获取给定类型的Type引用有3种常用方式: ● 使用 C# typeof 运算符。 Type t = typeof(string); ● 使用对象GetType()方法。 string s = "grayworm"; Type t = s.GetType(); ● 还可以调用Type类的静态方法GetType()。 Type t = Type.GetType("System.String"); 上面这三类代码都是获取string类型的Type,在取出string类型的Type引用t后,我们就可以通过t来探测string类型的结构了。 string n = "grayworm"; Type t = n.GetType(); foreach (MemberInfo mi in t.GetMembers()) { Console.WriteLine("{0}/t{1}",mi.MemberType,mi.Name); } Type类的属性: Name 数据类型名 FullName 数据类型的完全限定名(包括命名空间名) Namespace 定义数据类型的命名空间名 IsAbstract 指示该类型是否是抽象类型 IsArray 指示该类型是否是数组 IsClass 指示该类型是否是类 IsEnum 指示该类型是否是枚举 IsInterface 指示该类型是否是接口 IsPublic 指示该类型是否是公有的 IsSealed 指示该类型是否是密封类 IsValueType 指示该类型是否是值类型 Type类的方法: GetConstructor(), GetConstructors():返回ConstructorInfo类型,用于取得该类的构造函数的信息 GetEvent(), GetEvents():返回EventInfo类型,用于取得该类的事件的信息 GetField(), GetFields():返回FieldInfo类型,用于取得该类的字段(成员变量)的信息 GetInterface(), GetInterfaces():返回InterfaceInfo类型,用于取得该类实现的接口的信息 GetMember(), GetMembers():返回MemberInfo类型,用于取得该类的所有成员的信息 GetMethod(), GetMethods():返回MethodInfo类型,用于取得该类的方法的信息 GetProperty(), GetProperties():返回PropertyInfo类型,用于取得该类的属性的信息 可以调用这些成员,其方式是调用Type的InvokeMember()方法,或者调用MethodInfo, PropertyInfo和其他类的Invoke()方法。 //查看类中的构造方法: NewClassw nc = new NewClassw(); Type t = nc.GetType(); ConstructorInfo[] ci = t.GetConstructors(); //获取类的所有构造函数 foreach (ConstructorInfo c in ci) //遍历每一个构造函数 { ParameterInfo[] ps = c.GetParameters(); //取出每个构造函数的所有参数 foreach (ParameterInfo pi in ps) //遍历并打印所该构造函数的所有参数 { Console.Write(pi.ParameterType.ToString()+" "+pi.Name+","); } Console.WriteLine(); } 用构造函数动态生成对象: Type t = typeof(NewClassw); Type[] pt = new Type[2]; pt[0] = typeof(string); pt[1] = typeof(string); //根据参数类型获取构造函数 ConstructorInfo ci = t.GetConstructor(pt); //构造Object数组,作为构造函数的输入参数 object[] obj = new object[2]{"grayworm","hi.baidu.com/grayworm"}; //调用构造函数生成对象 object o = ci.Invoke(obj); //调用生成的对象的方法测试是否对象生成成功 //((NewClassw)o).show(); 用Activator生成对象: Type t = typeof(NewClassw); //构造函数的参数 object[] obj = new object[2] { "grayworm", "hi.baidu.com/grayworm" }; //用Activator的CreateInstance静态方法,生成新对象 object o = Activator.CreateInstance(t,"grayworm","hi.baidu.com/grayworm"); //((NewClassw)o).show(); //查看类中的属性: NewClassw nc = new NewClassw(); Type t = nc.GetType(); PropertyInfo[] pis = t.GetProperties(); foreach(PropertyInfo pi in pis) { Console.WriteLine(pi.Name); } //查看类中的public方法: NewClassw nc = new NewClassw(); Type t = nc.GetType(); MethodInfo[] mis = t.GetMethods(); foreach (MethodInfo mi in mis) { Console.WriteLine(mi.ReturnType+" "+mi.Name); } //查看类中的public字段 NewClassw nc = new NewClassw(); Type t = nc.GetType(); FieldInfo[] fis = t.GetFields(); foreach (FieldInfo fi in fis) { Console.WriteLine(fi.Name); } //用反射生成对象,并调用属性、方法和字段进行操作 NewClassw nc = new NewClassw(); Type t = nc.GetType(); object obj = Activator.CreateInstance(t); //取得ID字段 FieldInfo fi = t.GetField("ID"); //给ID字段赋值 fi.SetValue(obj, "k001"); //取得MyName属性 PropertyInfo pi1 = t.GetProperty("MyName"); //给MyName属性赋值 pi1.SetValue(obj, "grayworm", null); PropertyInfo pi2 = t.GetProperty("MyInfo"); pi2.SetValue(obj, "hi.baidu.com/grayworm", null); //取得show方法 MethodInfo mi = t.GetMethod("show"); //调用show方法 mi.Invoke(obj, null); System.Reflection.Assembly类 Assembly类可以获得程序集的信息,也可以动态的加载程序集,以及在程序集中查找类型信息,并创 建该类型的实例。 使用Assembly类可以降低程序集之间的耦合,有利于软件结构的合理化。 通过程序集名称返回Assembly对象 Assembly ass = Assembly.Load("ClassLibrary831"); 通过DLL文件名称返回Assembly对象 Assembly ass = Assembly.LoadFrom("ClassLibrary831.dll"); 通过Assembly获取程序集中类 Type t = ass.GetType("ClassLibrary831.NewClass"); //参数必须是类的全名 通过Assembly获取程序集中所有的类 Type[] t = ass.GetTypes(); //通过程序集的名称反射 Assembly ass = Assembly.Load("ClassLibrary831"); Type t = ass.GetType("ClassLibrary831.NewClass"); object o = Activator.CreateInstance(t, "grayworm", "http://hi.baidu.com/grayworm"); MethodInfo mi = t.GetMethod("show"); mi.Invoke(o, null); //通过DLL文件全名反射其中的所有类型 Assembly assembly = Assembly.LoadFrom("xxx.dll的路径"); Type[] aa = a.GetTypes(); foreach(Type t in aa) { if(t.FullName == "a.b.c") { object o = Activator.CreateInstance(t); } }