Java并发编程学习4-线程封闭和安全发布
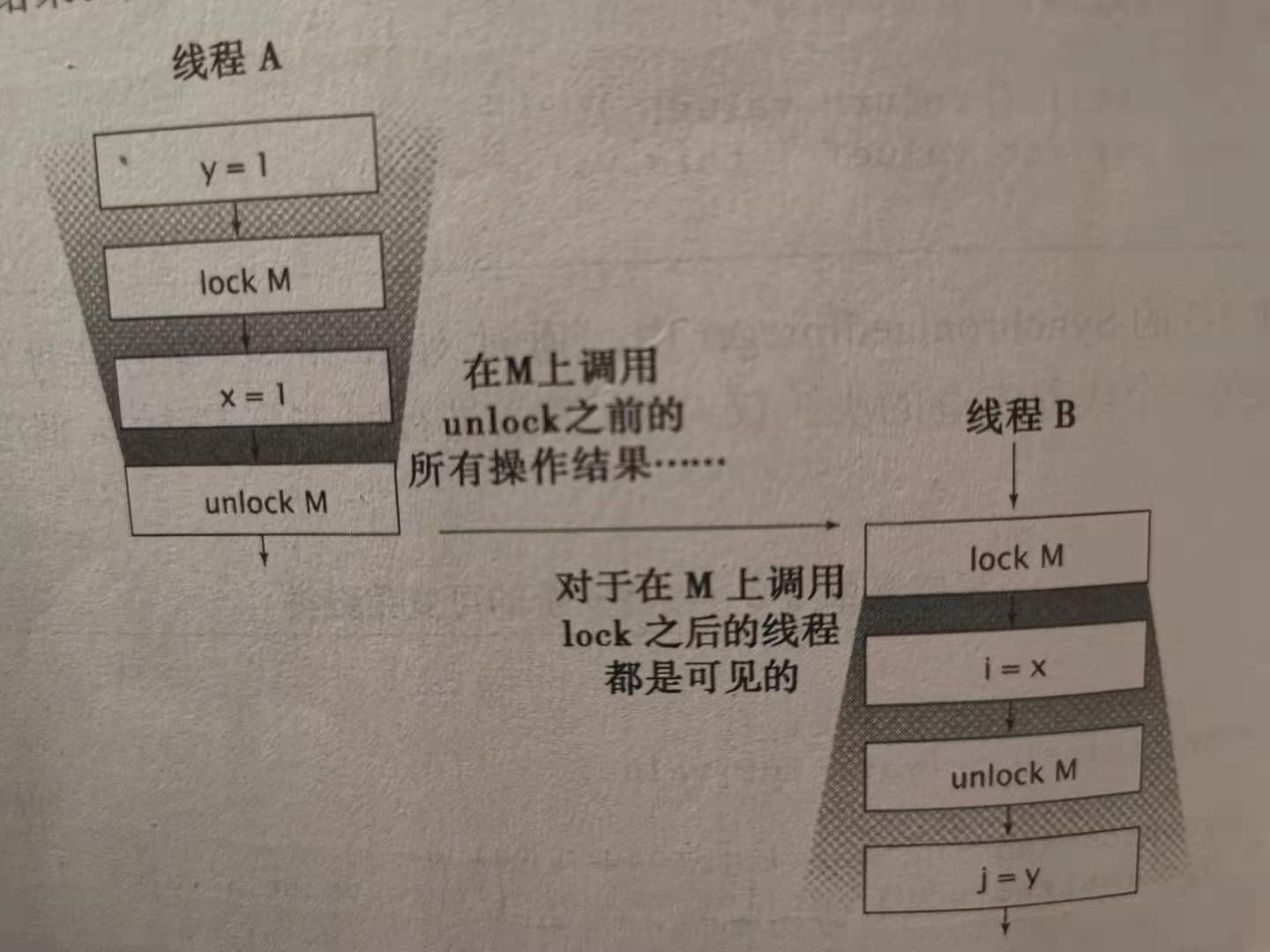
对象的共享 3. 线程封闭 线程封闭(Thread Confinement)是实现线程安全性的最简单方式之一。当某个对象封闭在一个线程中时,这种用法将自动实现线程安全性,即使被封闭的对象本身不是线程安全的。 在Java中使用线程封闭技术有:Swing 和 JDBC 的 Connection 对象。 Swing 的可视化组件和数据模型对象都不是线程安全的,Swing 通过将它们封闭到 Swing 的事件分发线程中来实现线程安全性;为了进一步简化对 Swing 的使用,Swing 还提供了 invokeLater 机制,用于将一个 Runnable 实例调度到事件线程中执行。 在典型的服务器应用程序中,线程从连接池中获得一个 Connection 对象,并且用该对象来处理请求,使用完后再将对象返还给连接池。在这个过程中,大多数请求(例如 Servlet 请求 或 EJB 调用)都是由单个线程采用同步的方式来处理,并且在 Connection 对象返回之前,连接池不会再将它分配给其他线程。也就是说,这种连接管理模式在处理请求时隐含地将 Connection 对象封闭在线程中。 3.1 Ad-hoc 线程封闭 Ad-hoc 线程封闭是指,维护线程封闭性的职责完全由程序实现来承担。因为没有任何一种语言特性,能将对象封闭到目标线程上,所以 Ad-hoc 线程封闭是非常脆弱的。而正由于 Ad-hoc 线程封闭技术的脆弱性,在程序中我们应尽量少用它,在可能的情况下,应该使用更强的线程封闭技术(例如下面要介绍的 栈封闭 或 ThreadLocal 类)。 3.2 栈封闭 栈封闭是线程封闭的一种特例(它也被称为线程内部使用或线程局部使用),在栈封闭中,只能通过局部变量才能访问对象。因为局部变量的固有属性之一就是封闭在执行线程中,它们位于执行线程的栈中,其他线程无法访问这个栈。因此栈封闭比 Ad-hoc 线程封闭更易于维护,也更加健壮。 3.3 ThreadLocal 类 ThreadLocal 对象通常用于防止对可变的单实例变量或全局变量进行共享。它提供了 get 与 set 等访问方法,这些方法为每个使用该变量的线程都存有一份独立的副本,因此 get 总是返回由当前执行线程在调用 set 时设置的最新值。 下面一起来看下面的代码示例: private static ThreadLocal<Connection> connectionHolder = new ThreadLocal<Connection>() { public Connection initialValue() { return DriverManager.getConnection(DB_URL); } }; public static Connection getConnection() { return connectionHolder.get(); } 上述代码通过将 JDBC 的连接保存到 ThreadLocal 对象中,每个线程都会拥有属于自己的连接。当某个线程初次调用 getConnection 方法时,就会调用 ThreadLocal 的 initialValue 来获取初始化的连接对象。 那么该怎么理解 ThreadLocal\<T> 对象呢 ?从概念上看,可以将 ThreadLocal\<T> 视为包含了 Map\<Thread, T> 对象,其中保存了特定于该线程的值。当然 ThreadLocal 的实现并非如此。这些特定于线程的值保存在 Thread 对象中,当线程终止后,这些值会作为垃圾回收。 值得注意的是,ThreadLocal 变量类似于全局变量,它可能会降低代码的可重用性,并在类之间引入隐含的耦合性,因此在使用时要格外小心。 4. 不变性 到目前为止,我们介绍了许多与原子性和可见性相关的问题,例如得到失效的数据,丢失更新操作或者观察到某个对象处于不一致的状态等等,都与多线程试图同时访问同一个可变的状态相关。如果对象的状态不会改变,那么这些问题自然也就迎刃而解。 如果某个对象在被创建后其状态就不能被修改,那么我们就可以称它为不可变对象。线程安全性是不可变对象的固有属性之一,它的不变性条件是由构造函数创建的,只要它的状态不改变,那么这些不变性条件就能一直维持下去。 不可变对象一定是线程安全。 虽然在 Java 语言规范和 Java 内存模型中都没有给出不可变性的正式定义,但不可变性并不等于将对象中的所有域都声明为 final 类型,即使对象中所有的域都是 final 类型的,这个对象也仍然可能是可变的,因为在 final 类型的域中可以保存对可变对象的引用。 当满足以下条件时,对象才是不可变的: 对象创建以后其状态就不能修改。 对象的所有域都是 final 类型。 对象时正确创建的(在对象创建期间,this引用没有逸出)。 在不可变对象的内部仍可以使用可变对象来管理它们的状态。 下面我们来看如下的代码示例: /** * <p> 在可变对象基础上构建的不可变类 </p> */ @Immutable public final class ThreeStooges { private final Set<String> stooges = new HashSet<>(); public ThreeStooges() { stooges.add("Tom"); stooges.add("Jerry"); stooges.add("Huazie"); } public boolean isStooge(String name) { return stooges.contains(name); } } 上述代码中 ThreeStooges 可以称为不可变对象。可以从如下三个方面来理解: 尽管保存臭皮匠姓名的 Set 对象是可变的,但从代码的设计上可以看到,在 Set 对象构造完成后无法对其进行修改。 stooges 是一个 final 类型的引用变量,因此所有的对象状态都通过的一个 final 域来访问。 ThreeStooges 的构造函数中无 this 引用的逸出,可以正确地构造对象。 4.1 Final 域 关键字 final 用于构造不可变的对象。final 类型的域是不能修改的,但如果 final 域所引用的对象是可变的,那么这些引用的对象是可以修改的。 在 Java 内存模型中,final 域能确保初始化过程的安全性,从而可以不受限制地访问不可变对象,并在共享这些对象时无须同步。 4.2 不可变对象的简单示例 在之前的博文中,我们介绍了 UnsafeCachingFactorizer,尝试用两个 AtomicReferences 变量来保存最新的数值及其因数分解结果,但这种方式并非是线程安全的,因为我们无法以原子方式来同时读取或更新这两个相关的值。 下面我们介绍一种 使用 volatile 类型来发布一个不可变对象 的方案: (1)首先,我们来看一个不可变的类 OneValueCache ,用于存储最新的数值及其因数分解的结果。 /** * <p> 对数值及其因数分解结果进行缓存的不可变容器类 </p> */ @Immutable public class OneValueCache { private final BigInteger lastNumber; private final BigInteger[] lastFactors; public OneValueCache(BigInteger lastNumber, BigInteger[] lastFactors) { this.lastNumber = lastNumber; if (null != lastFactors) { this.lastFactors = Arrays.copyOf(lastFactors, lastFactors.length); } else { this.lastFactors = null; } } public BigInteger[] getFactors(BigInteger i) { if (null == lastNumber || !lastNumber.equals(i)) return null; else return Arrays.copyOf(lastFactors, lastFactors.length); } } 对于在访问和更新多个相关变量时出现的的竞态条件问题,可以通过将这些变量全部保存在一个不可变对象中来消除。如果要更新这些变量,那么可以创建一个新的容器对象,而其他使用原有对象的线程仍然会看到对象处于一致的状态。 注意: 如果在 OneValueCache 的 getFactors 方法和构造函数中,没有调用 Arrays.copyOf , 那么 OneValueCache 就不是不可变的。 (2)然后,我们来看使用了修饰为 volatile 类型的 OneValueCache 的因数分解实现。 /** * <p> 使用执行不可变容器对象的 volatile 类型引用以缓存最新的结果 </p> */ public class VolatileCachedFactorizer extends HttpServlet { private volatile OneValueCache cache = new OneValueCache(null, null); protected void doGet(HttpServletRequest req, HttpServletResponse resp) throws IOException { BigInteger i = CommonUtils.extractFromRequest(req); BigInteger[] factors = cache.getFactors(i); if (null == factors) { factors = Factor.factor(i); cache = new OneValueCache(i, factors); } CommonUtils.encodeIntoResponse(resp, factors); } } (3)最后,我们简单分析下上述代码。因为 OneValueCache 是不可变的,并且在每条相应的代码路径中只会访问它一次,所以与 cache 变量相关的操作不会互相干扰,也就保证了因数分解过程的线程安全。通过使用包含多个状态变量的容器对象来维持不变性条件,并使用一个 volatile 类型的引用来确保可见性,使得 VolatileCachedFactorizer 在没有显式地使用锁的情况下仍然是线程安全的。 5. 安全发布 到目前为止,我们上面介绍了这么多的内容,重点讨论的还是如何确保对象不被发布,例如让对象封闭在线程或另一个对象的内部。某些情况下,我们其实希望在多个线程间共享对象,此时必须确保安全地进行共享。 下面我们先看一个发布对象的简单示例: // 在没有足够同步的情况下发布对象 public Holder holder; public void initialize() { holder = new Holder(42); } 上述代码由于存在可见性问题,其他线程看到的 Holder 对象将处于不一致的状态,即便在该对象的构造函数中已经正确地构建了不变性条件。这种不正确的发布导致其他线程看到尚未创建完成的对象。 5.1 不正确的发布:正确的对象被破坏 下面我们直接来看如下代码示例: /** * <p> 由于未被正确发布,因此这个类在调用 assertSanity时将抛出 AssertionError </p> */ public class Holder { private int n; public Holder(int n) { this.n = n; } public void assertSanity() { if (n != n) { throw new AssertionError("This statement is false."); } } } 上述代码中由于没有使用同步来确保 Holder 对其他线程可见,因此将 Holder 称为 “未被正确发布”。 在未被正确发布的对象中存在两个问题: 除了发布对象的线程外,其他线程可以看到的 Holder 域是一个失效值,因此将看到一个空引用或者之前的旧值。 发布对象的线程看到 Holder 引用的值是最新的,但 Holder 状态的值却是失效的。某个线程在第一次读取域时得到失效值,而再次读取这个域时会得到一个更新值,这也是 Holder 类调用 assertSanity 抛出 AssertionError 的原因。 注意: 尽管在构造函数中设置的域值似乎是第一次向这些域中写入的值,因此不会有 “更旧的” 值被视为失效值,但 Object 的构造函数会在子类构造函数运行之前先将默认值写入所有的域。因此,某个域的默认值可能被视为失效值。 5.2 不可变对象与初始化安全性 Java内存模型为不可变对象的共享提供了一种特殊的初始化安全性保证。即使在发布不可变对象的引用时没有使用同步,也仍然可以安全地访问该对象。 这种安全性保证还将延伸到被正确创建对象中所有 final 类型的域。在没有额外同步的情况下,也可以安全地访问 final 类型的域。但是如果 final 类型的域所指向的是可变对象,那么在访问这些域所指向的对象的状态时仍然需要同步。 5.3 安全发布的常用模式 要安全地发布一个对象,对象的引用以及对象的状态必须同时对其他线程可见。 可以通过以下方式来安全的发布一个正确构造的对象: 在静态初始化函数中初始化一个对象引用。 将对象的引用保存到 volatile 类型的域 或者 AtomicReference 对象中。 将对象的引用保存到某个正确构造对象的 final 类型域中。 将对象的引用保存到一个由锁保护的域中。 在线程安全容器内部的同步意味着,在将对象放入到某个容器,将满足上述最后一条方式。如果线程 A 将对象 X 放入一个线程安全的容器,随后线程 B 读取这个对象,那么可以确保 B 看到 A 设置的 X 状态,即便这段读/写 X 的应用程序代码没有包含显式的同步。 Java的线程安全库中的容器类有很多,下面列举一些它们提供的安全发布保证: 通过将一个键或者值放入 Hashtable、Collections.synchronizedMap 或者 ConcurrentMap 中,可以安全地将它发布给任何从这些容器中访问它的线程(无论是直接访问还是通过迭代器访问)。 通过将某个元素放入 Vector、CopyOnWriteArrayList、CopyOnWriteArraySet、Collections.synchronizedList 或 Collections.synchronizedSet 中,可以将该元素安全地发布到任何从这些容器中访问该元素的线程。 通过将某个元素放入 BlockingQueue 或者 ConcurrentLinkedQueue 中,可以将该元素安全地发布到任何从这些队列中访问该元素的线程。 类库中的其他数据传递机制(例如 Future 和 Exchanger)同样能实现安全发布,这些后续介绍这些机制将会仔细讨论。 要发布一个静态构造的对象,最简单和最安全的方式就是使用静态的初始化器: public static Holder holder = new Holder(42); 静态初始化器由 JVM 在类的初始化阶段执行。由于在 JVM 内部存在着同步机制,因此通过这种方式初始化的任何对象都可以被安全地发布。 5.4 事实不可变对象 如果对象从技术上来看是可变的,但其状态在发布后不会再改变,那么这种对象也称为 “事实不可变对象【Effectively Immutable Object】”。 所有的安全发布机制都能确保,当对象的引用对所有访问该对象的线程可见时,对象发布时的状态对于所有线程也将是可见的,并且如果该对象状态不会再改变,那么就足以确保任何访问都是安全的。 在没有额外的同步的情况下,任何线程都可以安全地使用被安全发布的事实不可变对象。 下面我们来看一个代码示例: public Map<String, Date> lastLogin = Collections.synchronizedMap(new HashMap<String, Date>()); 上述代码假设需要维护一个保存了每位用户的最近登录时间的 Map。如果 Date 对象的值在被放入 Map 后就不会改变,那么 synchronizedMap 中的同步机制就足以使 Date 值被安全地发布,并且在访问这些 Date 值时不需要额外的同步。 5.5 可变对象 如果对象在构造后可以修改,那么安全发布只能确保 “发布当时” 状态的可见性。对于可变对象不仅在发布对象时需要使用同步,而且在每次对象访问时同样需要使用同步来确保后续修改操作的可见性。 对象的发布需求取决于它的可变性: 不可变对象可以通过任意机制来发布。 事实不可变对象必须通过安全方式来发布。 可变对象必须通过安全方式来发布,并且必须是线程安全的或者由某个锁保护起来。 5.6 安全地共享对象 在并发程序中使用和共享对象时,可以使用如下一些实用的方法: 线程封闭。 线程封闭的对象只能由一个线程拥有,对象被封闭在该线程中,并且只能由这个线程修改。 只读共享。 在没有额外同步的情况下,共享的只读对象可以由多个线程并发访问,但任何线程都不能修改它。共享的只读对象包括不可变对象和事实不可变对象。 线程安全共享。 线程安全的对象在其内部实现同步,因此多个线程可以通过对象的公有接口来进行访问而不需要进一步的同步。 保护对象。 被保护的对象只能通过持有特定的锁来访问。保护对象包括封装在其他线程安全对象中的对象,以及已发布的并且由某个特定锁保护的对象。 结语 对象的共享 到这里就介绍完毕了,下一篇我们将开始了解 对象的组合,敬请期待!!!