Python全栈 MongoDB 数据库(Mongo、 正则基础、一篇通)
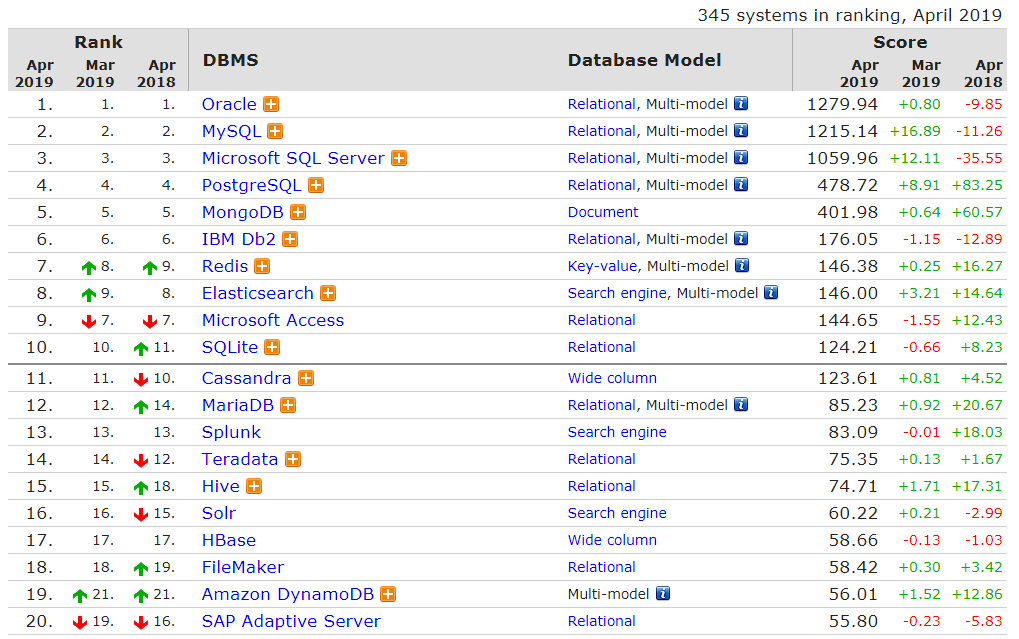
终端命令: 在线安装: sudo apt-get install mongodb 默认安装路径 : /var/lib/mongodb 配置文件 : /etc/mongodb.conf 命令集 : /usr/bin /usr/local/bin 下载解压: PATH=$PATH:/opt/mongodb.../bin export PATH 将以上两句写入 /etc/rc.local 备份: mongodump -h 主机地址 -d 库名 -o 文件名 恢复: mongorestore -h 主机地址: 端口号 -d 库名 文件路径 mongod --port 8080 设置端口(默认27017) mongo 进入mongo shell quit() exit ctrl+c/z/d 退出mongo shell mongostat 监测速度 (command 命令次数 flushes IO次数 vsize 虚拟内存) mongotop 监测时长 ( ns 数据集合、 total 总时长、 read 读时长 、write 写时长) Mongo命令: use 库名 创建/选择库 show dbs 查询库 db.dropDatabase() 删除库 db.createCollection(“集合名”) 创建集合 db.集合名.insert(...) 创建集合 show collections 查询集合 show tables 查询集合 db.getCollection("集合名") 查询集合所在库 db.集合名.drop() 删除集合 db.集合名.renameCollion("新集合名") 重命名集合 db.集合名.insert({name:"tom"..}) 插入文档 db.集合名.save({name:"tom",...}) 插入文档 db.集合名.insert([{}, {}...]) 插入多个文档 db.集合名.save([{} {}...]) 插入多个文档(加_id键会覆盖原文档) db.集合名.find(查找条件,域) 查找文档 db.集合名.findOne(查找条件,域) 只显示找到的第一条文档 db.集合名.distinct("集合名") 查看集合内某个域的取值范围 db.集合名.remove(query,justOne) 删除指定条件文档(默认false删除所有) db.集合名.update(query, update,upert,multi) 修改文档 db.集合名.find().count() 计数统计查询结果文档的个数 db.集合名.find().pretty() 将查询结果格式化显示 db.集合名.find().limit(n) 显示查找结果的前n条结果 db.集合名.find().skip(n) 跳n过前条显示后面的结果 db.集合名.find().count() 计数统计查询结果文档的个数 db.集合名.find().sort({filed:1/-1,...}) 排序 1:升序, -1:降序,第项相同按照第项二排序 db.集合名.find({'域名.下标':内容{_id:0}) 操作组中的某一项 db.集合名.find({"外域名.内部文档域":内容}, {_id:0}) 操作内部文档(Object)的域 db.集合名.ensureIndex({域:1/-1}) 创建索引(1:正向索引 -1:反向) db.集合名.getIndexes() 查看某个集合中的索引 db.集合名.ensureIndex({域:1/-1}},{name:'索引名'}) 自定义索引名称 db.集合名.dropIndex(({域:1/-1}) 删除索引 db.集合名.dropIndex("索引名") 删除索引 db.集合名.dropIndexes() 删除所有索引(默认_id索引无法删除) db.集合名.ensureIndex({域名1:1/-1,域名2:1/-1}) 创建符合索引 更节省空间 db.集合名.find({'数组.下标':值},{_id:0}) 如果对数组创建索引 查找值也属于索引查找 db.集合名.ensureIndex({域:1/-1},{unique:true}) 创建唯一索引 db.集合名.ensureIndex({域:1/-1},{sparse:true}) 创建稀疏索引 db.createCollection('集合名',{capped:true,size:10000,max:3}) 创建固定集合 比较操作符: $eq 等于 $lt 小于(字符串也可以比较大小) $lte 小于等于 $gt 大于 $gte 大于等于 $ne 不等于 $in 在什么里(in) $nin 不在什么里(not in) 逻辑操作符: $and 与 query内如果多个条件用逗号隔开默认就是and关系 $or 或 $not 非 $nor 既不也不 数组操作符: $size 只显示指定个size个数的文档] $all 查找数组中包含多项的 $slic 取数组中部分显示,在域(field)中声明 其他query查询: $exists 判断一个域是否存在 $mod 余数查找 $type 数据类型查找 修改操作符: $set 修改一个直 不存在则添加 $unset 删除一个域 $rename 修改域名 $setOnInsert 第三个参数为true作为补充插入数据 否则无用 $inc 加减修改器可以使整数小数正数负数 $mul 乘法修改器可以使整数小数正数负数 $min 设置域的值为上线 超过min修改为min $max 设置域的值为下线 小于max修改为max 数组修改符: $push 向数组中添加一项 $pushAll 向数组中添加多项 $pull 从数组中删除一项 $pullAll 从数组中删除多项 $each 对多个值进行逐一操作 $position 指定插入位置(配合each使用) $sort 对数组进行排序(配合each使用) $pop 弹出一项(1:弹出第一项 -1:最后一项) $addToSet 向数组中添加一项(不允许重复) 时间类型:ISODate() nuw Date() 自动生成当前时间 Date() 获取当前计算机时间格式字符串 ISODate() 生成当前时间 ISODate("2018-01-01 12:12:12") 自定义时间 ISODate("20180101 12:12:12") 自定义时间 ISODate("20180101") 自定义时间 valueOf() 生成时间戳 null 如果某个域的值不存在可以设置为null 修改参数: query: 筛选要查找要修改的文档 update: 将筛选的文档修改为什么内容需要配合修改操作符 upsert: bool值 默认false 如果query的文档不存在则不进行任何操作 设置为true 如果query和文档不存在 就根据query和update插入新文档 multi: bool值 默认false 如果query文档有多条则只修改第一条 设置为true 则修改所有符合条件的文档 查找参数: query(条件): 键值对的形式给出要展示的文档 field(域): 以键值对对的形式给出要展示或不展示的域 0为值不显示该域 1为值显示该域 如果使用0设置某些域不显示默认其他域显示 如果使用1设置某些域显示默认其他域不显示 *_id 只有设置为0才不显示否则默认显示 除_id以外,其他域必须同时设置0或1 索引: 指建立指定键值及所在文档中存储位置的对照清单 使用索引可以方便我们进行快速查找,减少数据遍历次数,从而提高查找效率 覆盖索引: 查找操作需要获取的域,只有索引域没有其他域。 此时索引表可以直接提供给用户想要的内容,提高查找效率 唯一索引: 创建的索引,索引域值无重复,此时可以创建唯一索引 唯一索引数据结构更加便于查找 稀疏索引: 只针对有指定域的文档创建索引表,如果某个文档没有该域则不会插入到索引表中 索引约束: 1. 索引表也需要占用一定的磁盘空间 2. 当数据发生更新时索引表也要随之更新 综上 : 1. 数据量比较大时更适合创建索引,数据量较小时没有必要付出索引代价 2. 频繁进行查找操作而不是更新删除插入操作,此时更适合使用索引 固定集合: 大小固定的集合,称之为固定集合 插入速度更快,顺序查找更快 可以控制集合的空间大小 能够自动淘汰早期数据 参数: capped:true 创建固定集合 size:10000 固定集合的大小 字节数 max :1000 表示最多多少条文档 正则基础 Python re模块正则接口详解