【SpringCloud技术专题】「Feign」从源码层面让你认识Feign工作流程和运作机制
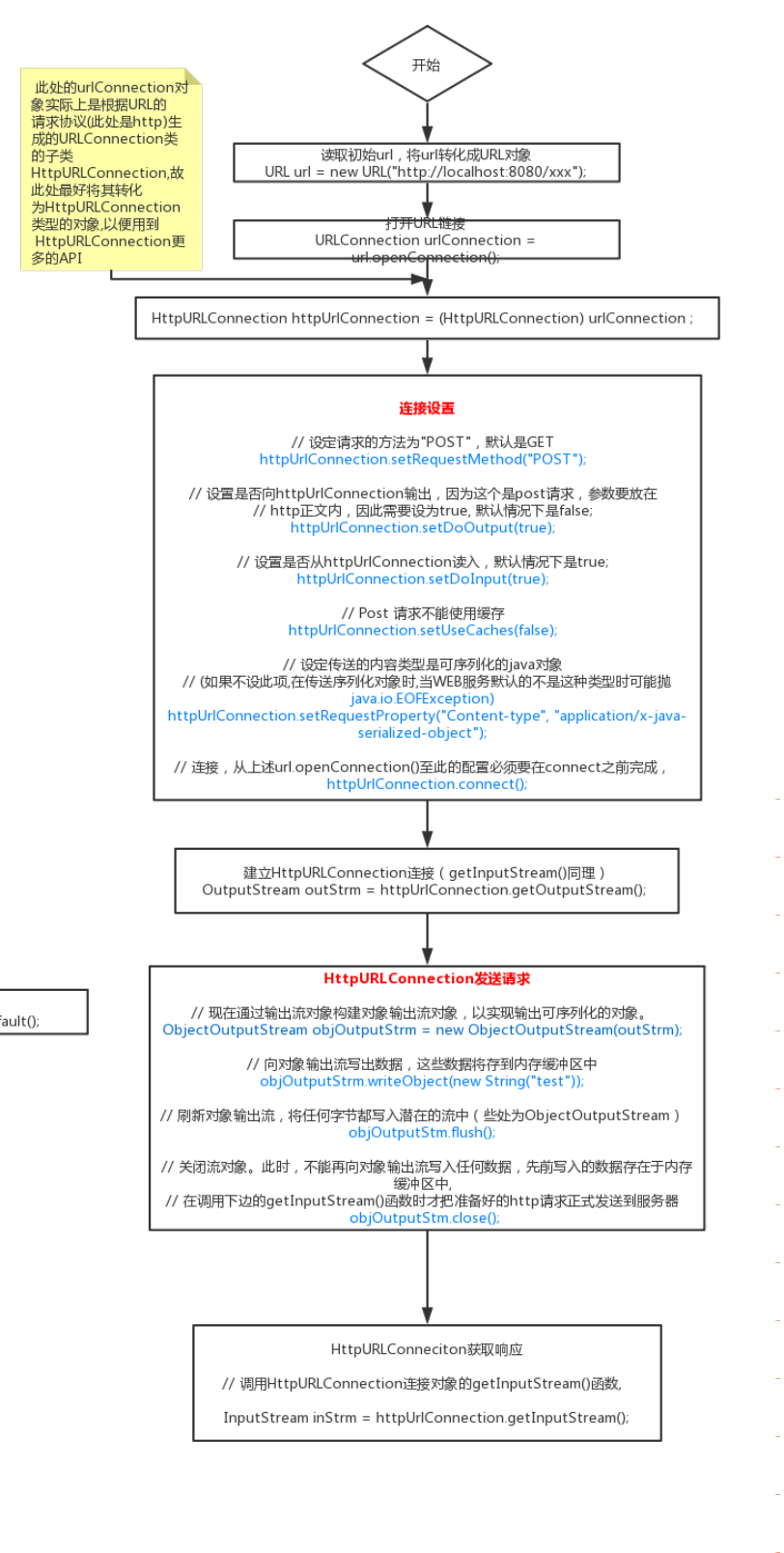
Feign工作流程源码解析 什么是feign:一款基于注解和动态代理的声明式restful http客户端。 原理 Feign发送请求实现原理 微服务启动类上标记@EnableFeignClients注解,然后Feign接口上标记@FeignClient注解。@FeignClient注解有几个参数需要配置,这里不再赘述,都很简单。 Feign框架会扫描注解,然后通过Feign类来处理注解,并最终生成一个Feign对象。 解析@FeignClient注解,生成MethodHandler 具体的解析类是ParseHandlerByName。这个类是ReflectiveFeign的内部类。 // 解析注解元数据,使用Contract解析 List<MethodMetadata> metadata = this.contract.parseAndValidateMetadata(key.type()); 拿到注解元数据以后,循环处理注解元数据,创建每个方法对应的MethodHandler,这个MethodHandler最终会被代理对象调用。最终MethodHandler都会保存到下面这个集合中,然后返回。 Map<String, MethodHandler> result = new LinkedHashMap(); 解析完成以后,调用ReflectiveFeign.newInstance()生成代理类。 MethodHandler是feign的一个接口,这个接口的invoke方法,是动态代理调用者InvocationHandler的invoke()方法最终调用的方法。 重新表述一遍:InvocationHandler的invoke()方法最终回调MethodHandler的invoke()来发送http请求。这就是Feign动态代理的具体实现。 ReflectiveFeign类的newInstance()方法的第57行: // 创建动态代理调用者 InvocationHandler handler = this.factory.create(target, methodToHandler); // 反射生成feign接口代理 T proxy = Proxy.newProxyInstance(加载器, 接口数组, handler); InvocationHandler.invoke()的具体实现在FeignInvocationHandler.invoke(),FeignInvocationHandler也是ReflectiveFeign的一个内部类。里面有很多细节处理这里不再赘述,我们直接进入核心那一行代码,以免影响思路,我们是理Feign的实现原理的!不要在意这些细节! // InvocationHandler的invoke()方法最终回调MethodHandler的invoke()来发送http请求 ReflectiveFeign类的invoke()方法,第323行,代码的后半段,如下: (MethodHandler)this.dispatch.get(method). invoke(args); this.dispatch:这是一个map,就是保存所有的MethodHandler的集合。参考创建InvocationHandler的位置:ReflectiveFeign类的newInstance()方法的第57行。 this.dispatch.get(method):这里的method就是我们开发者写的feign接口中定义的方法的方法名!这段代码的意思就是从MethodHandler集合中拿到我们需要调用的那个方法。 this.dispatch.get(method). invoke(args):这里的invoke就是调用的MethodHandler.invoke()!动态代理回调代理类,就这样完成了,oh my god,多么伟大的创举! MethodHandler.invoke()的具体实现:SynchronousMethodHandler.invoke() 到了这里,就是发送请求的逻辑了。发送请求前,首先要创建请求模板,然后调用请求拦截器RequestInterceptor进行请求处理。 // 创建RequestTemplate RequestTemplate template = this.buildTemlpateFromArgs.create(argv); // 创建feign重试器,进行失败重试 Retryer retryer = this.retryer.clone(); while(true){ try{ // 发送请求 return this.executeAndDecode(template); } catch(RetryableException var5) { // 失败重试,最多重试5次 retryer.continueOrPropagate(); } } RequestTemplate处理 RequestTemplate模板需要经过一系列拦截器的处理,主要有以下拦截器: BasicAuthRequestInterceptor:授权拦截器,主要是设置请求头的Authorization信息,这里是base64转码后的用户名和密码。 FeignAcceptGzipEncodingInterceptor:编码类型拦截器,主要是设置请求头的Accept-Encoding信息,默认值{gzip, deflate}。 FeignContextGzipEncodingInterceptor:压缩格式拦截器,该拦截器会判断请求头中Context-Length属性的值,是否大于请求内容的最大长度,如果超过最大长度2048,则设置请求头的Context-Encoding信息,默认值{gzip, deflate}。注意,这里的2048是可以设置的,可以在配置文件中进行配置: feign.compression.request.enabled=true feign.compression.request.min-request-size=2048 min-request-size是通过FeignClientEncodingProperties来解析的,默认值是2048。 我们还可以自定义请求拦截器,我们自定义的拦截器,也会在此时进行调用,所有实现了RequestTemplate接口的类,都会在这里被调用。比如我们可以自定义拦截器把全局事务id放在请求头里。 使用feign.Request把RequestTemplate包装成feign.Request feign.Request由5部分组成: method url headers body charset http请求客户端 Feign发送http请求支持下面几种http客户端: JDK自带的HttpUrlConnection Apache HttpClient OkHttpClient // 具体实现有2个类Client.Default 和LoadBalancerFeignClient response = this.client.execute(request, this.options); Client接口定义了execute()的接口,并且通过接口内部类实现了Client.execute()。 HttpURLConnection connection = this.convertAndSend(request, options); return this.convertResponse(connection).toBuilder(). request(request).build(); 这里的Options定义了2个参数: connectTimeoutMillis:连接超时时间,默认10秒。 readTimeoutMillis:读取数据超时时间,默认60秒。 这种方式是最简单的实现,但是不支持负载均衡,Spring Cloud整合了Feign和Ribbon,所以自然会把Feign和Ribbon结合起来使用。也就是说,Feign发送请求前,会先把请求再经过一层包装,包装成RibbonRequest。 也就是发送请求的另一种实现LoadBalancerFeignClient。 // 把Request包装成RibbonRequest RibbonRequest ribbonRequest = new (this.delegate, request, uriWithoutHost); // 配置超时时间 IClientConfig requestConfig = this.getClientConfig(options, clientName); // 以负载均衡的方式发送请求 return ((RibbonResponse)this.IbClient(clientName).executeWithLoadBalancer(ribbonRequest, requestConfig)).toResponse(); 以负载均衡的方式发送请求 this.IbClient(clientName).executeWithLoadBalancer(ribbonRequest, requestConfig))的具体实现在AbstractLoadBalancerAwareClient类中。 executeWithLoaderBalancer()方法的实现也参考了响应式编程,通过LoadBalancerCommand提交请求,然后使用Observable接收响应信息。 AbstractLoadBalancerAwareClient类的executeWithLoadBalancer()方法的第54行: Observable.just(AbstractLoadBalancerAwareClient.this.execute(requestForServer, requestConfig)); AbstractLoadBalancerAwareClient实现了IClient接口,该接口定义了execute()方法, AbstractLoadBalancerAwareClient.this.execute()的具体实现有很多种: OkHttpLoadBalancingClient RetryableOkHttpLoadBalancingClient RibbonLoadBalancingHttpClient RetryableRibbonLoadBalancingHttpClient 我们以RibbonLoadBalancingHttpClient为例来说明,RibbonLoadBalancingHttpClient.execute() 第62行代码: // 组装HttpUriRequest HttpUriRequest httpUriRequest = request.toRequest(requestConfig); // 发送http请求 HttpResponse httpResponse = ((HttpClient)this.delegate).execute(httpUriRequest); // 使用RibbonApacheHttpResponse包装http响应信息 return new RibbonApacheHttpResponse(httpResponse, httpUriRequest.getURI()); RibbonApacheHttpResponse由2部分组成: httpResponse uri 处理http相应 http请求经过上面一系列的转发以后,最终还会回到SynchronousMethodHandler,然后SynchronousMethodHandler会进行一系列的处理,然后响应到浏览器。 注册Feign客户端bean到IOC容器 查看Feign框架源代码,我们可以发现,FeignClientsRegistar的registerFeignClients()方法完成了feign相关bean的注册。 Feign架构图 第一步:基于JDK动态代理生成代理类。 第二步:根据接口类的注解声明规则,解析出底层MethodHandler 第三步:基于RequestBean动态生成request。 第四步:Encoder将bean包装成请求。 第五步:拦截器负责对请求和返回进行装饰处理。 第六步:日志记录。 第七步:基于重试器发送http请求,支持不同的http框架,默认使用的是HttpUrlConnection。