HBase编程 API入门系列之delete(管理端而言)(9)
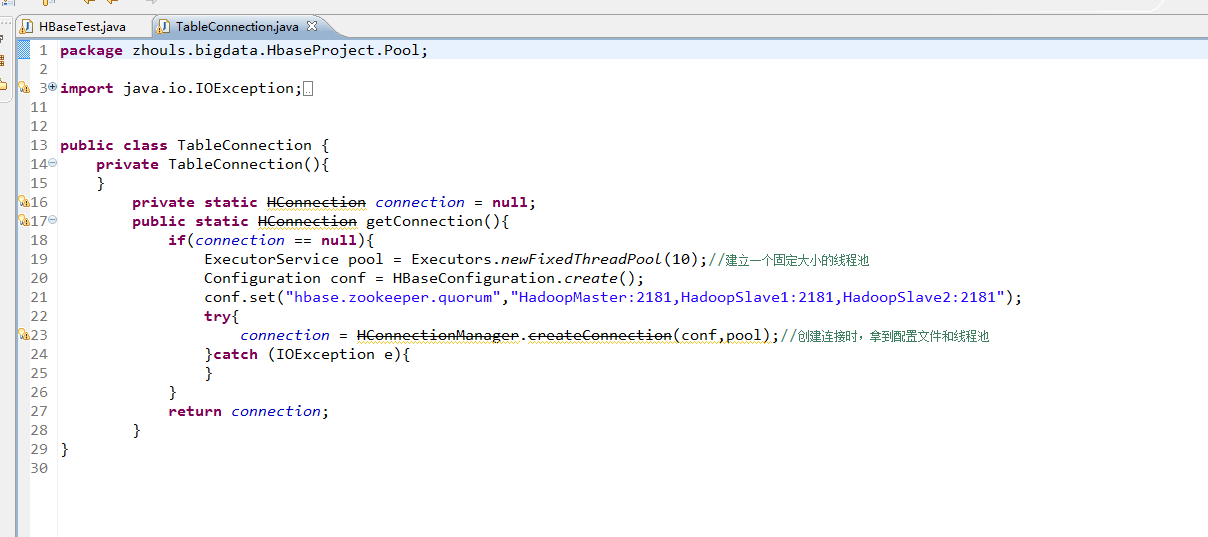
这里,我带领大家,学习更高级的,因为,在开发中,尽量不能客户端上删除表。 所以,在管理端来删除HBase表。采用线程池的方式(也是生产开发里首推的) package zhouls.bigdata.HbaseProject.Pool; import java.io.IOException; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.HConnection; import org.apache.hadoop.hbase.client.HConnectionManager; public class TableConnection { private TableConnection(){ } private static HConnection connection = null; public static HConnection getConnection(){ if(connection == null){ ExecutorService pool = Executors.newFixedThreadPool(10);//建立一个固定大小的线程池 Configuration conf = HBaseConfiguration.create(); conf.set("hbase.zookeeper.quorum","HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181"); try{ connection = HConnectionManager.createConnection(conf,pool);//创建连接时,拿到配置文件和线程池 }catch (IOException e){ } } return connection; } } 1、删除不存在的HBase表 hbase(main):062:0> list TABLE test_table test_table2 test_table3 test_table4 4 row(s) in 0.1540 seconds => ["test_table", "test_table2", "test_table3", "test_table4"] hbase(main):063:0> package zhouls.bigdata.HbaseProject.Pool; import java.io.IOException; import zhouls.bigdata.HbaseProject.Pool.TableConnection; import javax.xml.transform.Result; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.MasterNotRunningException; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.ZooKeeperConnectionException; import org.apache.hadoop.hbase.client.Delete; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.HTableInterface; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.util.Bytes; public class HBaseTest { public static void main(String[] args) throws Exception { // HTable table = new HTable(getConfig(),TableName.valueOf("test_table"));//表名是test_table // Put put = new Put(Bytes.toBytes("row_04"));//行键是row_04 // put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy1"));//列簇是f,列修饰符是name,值是Andy0 // put.add(Bytes.toBytes("f2"),Bytes.toBytes("name"),Bytes.toBytes("Andy3"));//列簇是f2,列修饰符是name,值是Andy3 // table.put(put); // table.close(); // Get get = new Get(Bytes.toBytes("row_04")); // get.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"));如现在这样,不指定,默认把所有的全拿出来 // org.apache.hadoop.hbase.client.Result rest = table.get(get); // System.out.println(rest.toString()); // table.close(); // Delete delete = new Delete(Bytes.toBytes("row_2")); // delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("email")); // delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("name")); // table.delete(delete); // table.close(); // Delete delete = new Delete(Bytes.toBytes("row_04")); //// delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));//deleteColumn是删除某一个列簇里的最新时间戳版本。 // delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));//delete.deleteColumns是删除某个列簇里的所有时间戳版本。 // table.delete(delete); // table.close(); // Scan scan = new Scan(); // scan.setStartRow(Bytes.toBytes("row_01"));//包含开始行键 // scan.setStopRow(Bytes.toBytes("row_03"));//不包含结束行键 // scan.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name")); // ResultScanner rst = table.getScanner(scan);//整个循环 // System.out.println(rst.toString()); // for (org.apache.hadoop.hbase.client.Result next = rst.next();next !=null;next = rst.next() ) // { // for(Cell cell:next.rawCells()){//某个row key下的循坏 // System.out.println(next.toString()); // System.out.println("family:" + Bytes.toString(CellUtil.cloneFamily(cell))); // System.out.println("col:" + Bytes.toString(CellUtil.cloneQualifier(cell))); // System.out.println("value" + Bytes.toString(CellUtil.cloneValue(cell))); // } // } // table.close(); HBaseTest hbasetest =new HBaseTest(); // hbasetest.insertValue(); // hbasetest.getValue(); // hbasetest.delete(); // hbasetest.scanValue(); // hbasetest.createTable("test_table4", "f"); hbasetest.deleteTable("test_table5");//假如这里,删除不存在的表 } //生产开发中,建议这样用线程池做 // public void insertValue() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Put put = new Put(Bytes.toBytes("row_01"));//行键是row_01 // put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy0")); // table.put(put); // table.close(); // } //生产开发中,建议这样用线程池做 // public void getValue() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Get get = new Get(Bytes.toBytes("row_03")); // get.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name")); // org.apache.hadoop.hbase.client.Result rest = table.get(get); // System.out.println(rest.toString()); // table.close(); // } // //生产开发中,建议这样用线程池做 // public void delete() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Delete delete = new Delete(Bytes.toBytes("row_01")); // delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));//deleteColumn是删除某一个列簇里的最新时间戳版本。 //// delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));//delete.deleteColumns是删除某个列簇里的所有时间戳版本。 // table.delete(delete); // table.close(); // // } //生产开发中,建议这样用线程池做 // public void scanValue() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Scan scan = new Scan(); // scan.setStartRow(Bytes.toBytes("row_02"));//包含开始行键 // scan.setStopRow(Bytes.toBytes("row_04"));//不包含结束行键 // scan.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name")); // ResultScanner rst = table.getScanner(scan);//整个循环 // System.out.println(rst.toString()); // for (org.apache.hadoop.hbase.client.Result next = rst.next();next !=null;next = rst.next() ) // { // for(Cell cell:next.rawCells()){//某个row key下的循坏 // System.out.println(next.toString()); // System.out.println("family:" + Bytes.toString(CellUtil.cloneFamily(cell))); // System.out.println("col:" + Bytes.toString(CellUtil.cloneQualifier(cell))); // System.out.println("value" + Bytes.toString(CellUtil.cloneValue(cell))); // } // } // table.close(); // } // //生产开发中,建议这样用线程池做 // public void createTable(String tableName,String family) throws MasterNotRunningException, ZooKeeperConnectionException, IOException{ // Configuration conf = HBaseConfiguration.create(getConfig()); // HBaseAdmin admin = new HBaseAdmin(conf); // HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName)); // HColumnDescriptor hcd = new HColumnDescriptor(family); // hcd.setMaxVersions(3); //// hcd.set//很多的带创建操作,我这里只抛砖引玉的作用 // tableDesc.addFamily(hcd); // admin.createTable(tableDesc); // admin.close(); // } public void deleteTable(String tableName)throws MasterNotRunningException, ZooKeeperConnectionException, IOException{ Configuration conf = HBaseConfiguration.create(getConfig()); HBaseAdmin admin = new HBaseAdmin(conf); admin.disableTable(tableName); admin.deleteTable(tableName); admin.close(); } public static Configuration getConfig(){ Configuration configuration = new Configuration(); // conf.set("hbase.rootdir","hdfs:HadoopMaster:9000/hbase"); configuration.set("hbase.zookeeper.quorum", "HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181"); return configuration; } } 2016-12-11 16:04:48,141 INFO [org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper] - Process identifier=hconnection-0x1417e278 connecting to ZooKeeper ensemble=HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181 2016-12-11 16:04:48,150 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 2016-12-11 16:04:48,150 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:host.name=WIN-BQOBV63OBNM 2016-12-11 16:04:48,150 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.version=1.7.0_51 2016-12-11 16:04:48,150 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.vendor=Oracle Corporation 2016-12-11 16:04:48,150 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.home=C:\Program Files\Java\jdk1.7.0_51\jre 2016-12-11 16:04:48,150 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.class.path=D:\Code\MyEclipseJavaCode\HbaseProject\bin;D:\SoftWare\hbase-1.2.3\lib\activation-1.1.jar;D:\SoftWare\hbase-1.2.3\lib\aopalliance-1.0.jar;D:\SoftWare\hbase-1.2.3\lib\apacheds-i18n-2.0.0-M15.jar;D:\SoftWare\hbase-1.2.3\lib\apacheds-kerberos-codec-2.0.0-M15.jar;D:\SoftWare\hbase-1.2.3\lib\api-asn1-api-1.0.0-M20.jar;D:\SoftWare\hbase-1.2.3\lib\api-util-1.0.0-M20.jar;D:\SoftWare\hbase-1.2.3\lib\asm-3.1.jar;D:\SoftWare\hbase-1.2.3\lib\avro-1.7.4.jar;D:\SoftWare\hbase-1.2.3\lib\commons-beanutils-1.7.0.jar;D:\SoftWare\hbase-1.2.3\lib\commons-beanutils-core-1.8.0.jar;D:\SoftWare\hbase-1.2.3\lib\commons-cli-1.2.jar;D:\SoftWare\hbase-1.2.3\lib\commons-codec-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\commons-collections-3.2.2.jar;D:\SoftWare\hbase-1.2.3\lib\commons-compress-1.4.1.jar;D:\SoftWare\hbase-1.2.3\lib\commons-configuration-1.6.jar;D:\SoftWare\hbase-1.2.3\lib\commons-daemon-1.0.13.jar;D:\SoftWare\hbase-1.2.3\lib\commons-digester-1.8.jar;D:\SoftWare\hbase-1.2.3\lib\commons-el-1.0.jar;D:\SoftWare\hbase-1.2.3\lib\commons-httpclient-3.1.jar;D:\SoftWare\hbase-1.2.3\lib\commons-io-2.4.jar;D:\SoftWare\hbase-1.2.3\lib\commons-lang-2.6.jar;D:\SoftWare\hbase-1.2.3\lib\commons-logging-1.2.jar;D:\SoftWare\hbase-1.2.3\lib\commons-math-2.2.jar;D:\SoftWare\hbase-1.2.3\lib\commons-math3-3.1.1.jar;D:\SoftWare\hbase-1.2.3\lib\commons-net-3.1.jar;D:\SoftWare\hbase-1.2.3\lib\disruptor-3.3.0.jar;D:\SoftWare\hbase-1.2.3\lib\findbugs-annotations-1.3.9-1.jar;D:\SoftWare\hbase-1.2.3\lib\guava-12.0.1.jar;D:\SoftWare\hbase-1.2.3\lib\guice-3.0.jar;D:\SoftWare\hbase-1.2.3\lib\guice-servlet-3.0.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-annotations-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-auth-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-client-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-common-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-hdfs-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-mapreduce-client-app-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-mapreduce-client-common-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-mapreduce-client-core-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-mapreduce-client-jobclient-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-mapreduce-client-shuffle-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-yarn-api-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-yarn-client-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-yarn-common-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-yarn-server-common-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-annotations-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-annotations-1.2.3-tests.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-client-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-common-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-common-1.2.3-tests.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-examples-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-external-blockcache-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-hadoop2-compat-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-hadoop-compat-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-it-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-it-1.2.3-tests.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-prefix-tree-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-procedure-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-protocol-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-resource-bundle-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-rest-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-server-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-server-1.2.3-tests.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-shell-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-thrift-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\htrace-core-3.1.0-incubating.jar;D:\SoftWare\hbase-1.2.3\lib\httpclient-4.2.5.jar;D:\SoftWare\hbase-1.2.3\lib\httpcore-4.4.1.jar;D:\SoftWare\hbase-1.2.3\lib\jackson-core-asl-1.9.13.jar;D:\SoftWare\hbase-1.2.3\lib\jackson-jaxrs-1.9.13.jar;D:\SoftWare\hbase-1.2.3\lib\jackson-mapper-asl-1.9.13.jar;D:\SoftWare\hbase-1.2.3\lib\jackson-xc-1.9.13.jar;D:\SoftWare\hbase-1.2.3\lib\jamon-runtime-2.4.1.jar;D:\SoftWare\hbase-1.2.3\lib\jasper-compiler-5.5.23.jar;D:\SoftWare\hbase-1.2.3\lib\jasper-runtime-5.5.23.jar;D:\SoftWare\hbase-1.2.3\lib\javax.inject-1.jar;D:\SoftWare\hbase-1.2.3\lib\java-xmlbuilder-0.4.jar;D:\SoftWare\hbase-1.2.3\lib\jaxb-api-2.2.2.jar;D:\SoftWare\hbase-1.2.3\lib\jaxb-impl-2.2.3-1.jar;D:\SoftWare\hbase-1.2.3\lib\jcodings-1.0.8.jar;D:\SoftWare\hbase-1.2.3\lib\jersey-client-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\jersey-core-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\jersey-guice-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\jersey-json-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\jersey-server-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\jets3t-0.9.0.jar;D:\SoftWare\hbase-1.2.3\lib\jettison-1.3.3.jar;D:\SoftWare\hbase-1.2.3\lib\jetty-6.1.26.jar;D:\SoftWare\hbase-1.2.3\lib\jetty-sslengine-6.1.26.jar;D:\SoftWare\hbase-1.2.3\lib\jetty-util-6.1.26.jar;D:\SoftWare\hbase-1.2.3\lib\joni-2.1.2.jar;D:\SoftWare\hbase-1.2.3\lib\jruby-complete-1.6.8.jar;D:\SoftWare\hbase-1.2.3\lib\jsch-0.1.42.jar;D:\SoftWare\hbase-1.2.3\lib\jsp-2.1-6.1.14.jar;D:\SoftWare\hbase-1.2.3\lib\jsp-api-2.1-6.1.14.jar;D:\SoftWare\hbase-1.2.3\lib\junit-4.12.jar;D:\SoftWare\hbase-1.2.3\lib\leveldbjni-all-1.8.jar;D:\SoftWare\hbase-1.2.3\lib\libthrift-0.9.3.jar;D:\SoftWare\hbase-1.2.3\lib\log4j-1.2.17.jar;D:\SoftWare\hbase-1.2.3\lib\metrics-core-2.2.0.jar;D:\SoftWare\hbase-1.2.3\lib\netty-all-4.0.23.Final.jar;D:\SoftWare\hbase-1.2.3\lib\paranamer-2.3.jar;D:\SoftWare\hbase-1.2.3\lib\protobuf-java-2.5.0.jar;D:\SoftWare\hbase-1.2.3\lib\servlet-api-2.5.jar;D:\SoftWare\hbase-1.2.3\lib\servlet-api-2.5-6.1.14.jar;D:\SoftWare\hbase-1.2.3\lib\slf4j-api-1.7.7.jar;D:\SoftWare\hbase-1.2.3\lib\slf4j-log4j12-1.7.5.jar;D:\SoftWare\hbase-1.2.3\lib\snappy-java-1.0.4.1.jar;D:\SoftWare\hbase-1.2.3\lib\spymemcached-2.11.6.jar;D:\SoftWare\hbase-1.2.3\lib\xmlenc-0.52.jar;D:\SoftWare\hbase-1.2.3\lib\xz-1.0.jar;D:\SoftWare\hbase-1.2.3\lib\zookeeper-3.4.6.jar 2016-12-11 16:04:48,151 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.library.path=C:\Program Files\Java\jdk1.7.0_51\bin;C:\Windows\Sun\Java\bin;C:\Windows\system32;C:\Windows;C:\ProgramData\Oracle\Java\javapath;C:\Python27\;C:\Python27\Scripts;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;D:\SoftWare\MATLAB R2013a\runtime\win64;D:\SoftWare\MATLAB R2013a\bin;C:\Program Files (x86)\IDM Computer Solutions\UltraCompare;C:\Program Files\Java\jdk1.7.0_51\bin;C:\Program Files\Java\jdk1.7.0_51\jre\bin;D:\SoftWare\apache-ant-1.9.0\bin;HADOOP_HOME\bin;D:\SoftWare\apache-maven-3.3.9\bin;D:\SoftWare\Scala\bin;D:\SoftWare\Scala\jre\bin;%MYSQL_HOME\bin;D:\SoftWare\MySQL Server\MySQL Server 5.0\bin;D:\SoftWare\apache-tomcat-7.0.69\bin;%C:\Windows\System32;%C:\Windows\SysWOW64;D:\SoftWare\SSH Secure Shell;. 2016-12-11 16:04:48,151 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.io.tmpdir=C:\Users\ADMINI~1\AppData\Local\Temp\ 2016-12-11 16:04:48,151 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.compiler=<NA> 2016-12-11 16:04:48,151 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:os.name=Windows 7 2016-12-11 16:04:48,152 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:os.arch=amd64 2016-12-11 16:04:48,152 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:os.version=6.1 2016-12-11 16:04:48,152 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:user.name=Administrator 2016-12-11 16:04:48,152 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:user.home=C:\Users\Administrator 2016-12-11 16:04:48,152 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:user.dir=D:\Code\MyEclipseJavaCode\HbaseProject 2016-12-11 16:04:48,153 INFO [org.apache.zookeeper.ZooKeeper] - Initiating client connection, connectString=HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181 sessionTimeout=90000 watcher=hconnection-0x1417e2780x0, quorum=HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181, baseZNode=/hbase 2016-12-11 16:04:48,199 INFO [org.apache.zookeeper.ClientCnxn] - Opening socket connection to server HadoopMaster/192.168.80.10:2181. Will not attempt to authenticate using SASL (unknown error) 2016-12-11 16:04:48,203 INFO [org.apache.zookeeper.ClientCnxn] - Socket connection established to HadoopMaster/192.168.80.10:2181, initiating session 2016-12-11 16:04:48,762 INFO [org.apache.zookeeper.ClientCnxn] - Session establishment complete on server HadoopMaster/192.168.80.10:2181, sessionid = 0x1582556e7c50027, negotiated timeout = 40000 2016-12-11 16:04:50,731 INFO [org.apache.hadoop.hbase.client.HBaseAdmin] - Started disable of test_table5 Exception in thread "main" org.apache.hadoop.hbase.TableNotFoundException: test_table5 at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:526) at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:106) at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:95) at org.apache.hadoop.hbase.util.ForeignExceptionUtil.toIOException(ForeignExceptionUtil.java:45) at org.apache.hadoop.hbase.client.HBaseAdmin$ProcedureFuture.convertResult(HBaseAdmin.java:4621) at org.apache.hadoop.hbase.client.HBaseAdmin$ProcedureFuture.waitProcedureResult(HBaseAdmin.java:4579) at org.apache.hadoop.hbase.client.HBaseAdmin$ProcedureFuture.get(HBaseAdmin.java:4512) at org.apache.hadoop.hbase.client.HBaseAdmin.disableTable(HBaseAdmin.java:1331) at org.apache.hadoop.hbase.client.HBaseAdmin.disableTable(HBaseAdmin.java:1352) at zhouls.bigdata.HbaseProject.Pool.HBaseTest.deleteTable(HBaseTest.java:164) at zhouls.bigdata.HbaseProject.Pool.HBaseTest.main(HBaseTest.java:82) Caused by: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hbase.TableNotFoundException): test_table5 at org.apache.hadoop.hbase.master.procedure.DisableTableProcedure.prepareDisable(DisableTableProcedure.java:281) at org.apache.hadoop.hbase.master.procedure.DisableTableProcedure.executeFromState(DisableTableProcedure.java:133) at org.apache.hadoop.hbase.master.procedure.DisableTableProcedure.executeFromState(DisableTableProcedure.java:54) at org.apache.hadoop.hbase.procedure2.StateMachineProcedure.execute(StateMachineProcedure.java:119) at org.apache.hadoop.hbase.procedure2.Procedure.doExecute(Procedure.java:498) at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.execProcedure(ProcedureExecutor.java:1061) at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.execLoop(ProcedureExecutor.java:856) at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.execLoop(ProcedureExecutor.java:809) at org.apache.hadoop.hbase.procedure2.ProcedureExecutor.access$400(ProcedureExecutor.java:75) at org.apache.hadoop.hbase.procedure2.ProcedureExecutor$2.run(ProcedureExecutor.java:495) 2、删除存在的HBase表 package zhouls.bigdata.HbaseProject.Pool; import java.io.IOException; import zhouls.bigdata.HbaseProject.Pool.TableConnection; import javax.xml.transform.Result; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.MasterNotRunningException; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.ZooKeeperConnectionException; import org.apache.hadoop.hbase.client.Delete; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.HTableInterface; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.util.Bytes; public class HBaseTest { public static void main(String[] args) throws Exception { // HTable table = new HTable(getConfig(),TableName.valueOf("test_table"));//表名是test_table // Put put = new Put(Bytes.toBytes("row_04"));//行键是row_04 // put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy1"));//列簇是f,列修饰符是name,值是Andy0 // put.add(Bytes.toBytes("f2"),Bytes.toBytes("name"),Bytes.toBytes("Andy3"));//列簇是f2,列修饰符是name,值是Andy3 // table.put(put); // table.close(); // Get get = new Get(Bytes.toBytes("row_04")); // get.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"));如现在这样,不指定,默认把所有的全拿出来 // org.apache.hadoop.hbase.client.Result rest = table.get(get); // System.out.println(rest.toString()); // table.close(); // Delete delete = new Delete(Bytes.toBytes("row_2")); // delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("email")); // delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("name")); // table.delete(delete); // table.close(); // Delete delete = new Delete(Bytes.toBytes("row_04")); //// delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));//deleteColumn是删除某一个列簇里的最新时间戳版本。 // delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));//delete.deleteColumns是删除某个列簇里的所有时间戳版本。 // table.delete(delete); // table.close(); // Scan scan = new Scan(); // scan.setStartRow(Bytes.toBytes("row_01"));//包含开始行键 // scan.setStopRow(Bytes.toBytes("row_03"));//不包含结束行键 // scan.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name")); // ResultScanner rst = table.getScanner(scan);//整个循环 // System.out.println(rst.toString()); // for (org.apache.hadoop.hbase.client.Result next = rst.next();next !=null;next = rst.next() ) // { // for(Cell cell:next.rawCells()){//某个row key下的循坏 // System.out.println(next.toString()); // System.out.println("family:" + Bytes.toString(CellUtil.cloneFamily(cell))); // System.out.println("col:" + Bytes.toString(CellUtil.cloneQualifier(cell))); // System.out.println("value" + Bytes.toString(CellUtil.cloneValue(cell))); // } // } // table.close(); HBaseTest hbasetest =new HBaseTest(); // hbasetest.insertValue(); // hbasetest.getValue(); // hbasetest.delete(); // hbasetest.scanValue(); // hbasetest.createTable("test_table4", "f"); hbasetest.deleteTable("test_table4");//删除存在的表 } //生产开发中,建议这样用线程池做 // public void insertValue() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Put put = new Put(Bytes.toBytes("row_01"));//行键是row_01 // put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy0")); // table.put(put); // table.close(); // } //生产开发中,建议这样用线程池做 // public void getValue() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Get get = new Get(Bytes.toBytes("row_03")); // get.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name")); // org.apache.hadoop.hbase.client.Result rest = table.get(get); // System.out.println(rest.toString()); // table.close(); // } // //生产开发中,建议这样用线程池做 // public void delete() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Delete delete = new Delete(Bytes.toBytes("row_01")); // delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));//deleteColumn是删除某一个列簇里的最新时间戳版本。 //// delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));//delete.deleteColumns是删除某个列簇里的所有时间戳版本。 // table.delete(delete); // table.close(); // // } //生产开发中,建议这样用线程池做 // public void scanValue() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Scan scan = new Scan(); // scan.setStartRow(Bytes.toBytes("row_02"));//包含开始行键 // scan.setStopRow(Bytes.toBytes("row_04"));//不包含结束行键 // scan.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name")); // ResultScanner rst = table.getScanner(scan);//整个循环 // System.out.println(rst.toString()); // for (org.apache.hadoop.hbase.client.Result next = rst.next();next !=null;next = rst.next() ) // { // for(Cell cell:next.rawCells()){//某个row key下的循坏 // System.out.println(next.toString()); // System.out.println("family:" + Bytes.toString(CellUtil.cloneFamily(cell))); // System.out.println("col:" + Bytes.toString(CellUtil.cloneQualifier(cell))); // System.out.println("value" + Bytes.toString(CellUtil.cloneValue(cell))); // } // } // table.close(); // } // //生产开发中,建议这样用线程池做 // public void createTable(String tableName,String family) throws MasterNotRunningException, ZooKeeperConnectionException, IOException{ // Configuration conf = HBaseConfiguration.create(getConfig()); // HBaseAdmin admin = new HBaseAdmin(conf); // HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName)); // HColumnDescriptor hcd = new HColumnDescriptor(family); // hcd.setMaxVersions(3); //// hcd.set//很多的带创建操作,我这里只抛砖引玉的作用 // tableDesc.addFamily(hcd); // admin.createTable(tableDesc); // admin.close(); // } public void deleteTable(String tableName)throws MasterNotRunningException, ZooKeeperConnectionException, IOException{ Configuration conf = HBaseConfiguration.create(getConfig()); HBaseAdmin admin = new HBaseAdmin(conf); admin.disableTable(tableName); admin.deleteTable(tableName); admin.close(); } public static Configuration getConfig(){ Configuration configuration = new Configuration(); // conf.set("hbase.rootdir","hdfs:HadoopMaster:9000/hbase"); configuration.set("hbase.zookeeper.quorum", "HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181"); return configuration; } } 3、先判断表是否存在,再来删除HBase表(生产开发首推) package zhouls.bigdata.HbaseProject.Pool; import java.io.IOException; import zhouls.bigdata.HbaseProject.Pool.TableConnection; import javax.xml.transform.Result; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.MasterNotRunningException; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.ZooKeeperConnectionException; import org.apache.hadoop.hbase.client.Delete; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.HTableInterface; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.util.Bytes; public class HBaseTest { public static void main(String[] args) throws Exception { // HTable table = new HTable(getConfig(),TableName.valueOf("test_table"));//表名是test_table // Put put = new Put(Bytes.toBytes("row_04"));//行键是row_04 // put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy1"));//列簇是f,列修饰符是name,值是Andy0 // put.add(Bytes.toBytes("f2"),Bytes.toBytes("name"),Bytes.toBytes("Andy3"));//列簇是f2,列修饰符是name,值是Andy3 // table.put(put); // table.close(); // Get get = new Get(Bytes.toBytes("row_04")); // get.addColumn(Bytes.toBytes("f1"), Bytes.toBytes("age"));如现在这样,不指定,默认把所有的全拿出来 // org.apache.hadoop.hbase.client.Result rest = table.get(get); // System.out.println(rest.toString()); // table.close(); // Delete delete = new Delete(Bytes.toBytes("row_2")); // delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("email")); // delete.deleteColumn(Bytes.toBytes("f1"), Bytes.toBytes("name")); // table.delete(delete); // table.close(); // Delete delete = new Delete(Bytes.toBytes("row_04")); //// delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));//deleteColumn是删除某一个列簇里的最新时间戳版本。 // delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));//delete.deleteColumns是删除某个列簇里的所有时间戳版本。 // table.delete(delete); // table.close(); // Scan scan = new Scan(); // scan.setStartRow(Bytes.toBytes("row_01"));//包含开始行键 // scan.setStopRow(Bytes.toBytes("row_03"));//不包含结束行键 // scan.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name")); // ResultScanner rst = table.getScanner(scan);//整个循环 // System.out.println(rst.toString()); // for (org.apache.hadoop.hbase.client.Result next = rst.next();next !=null;next = rst.next() ) // { // for(Cell cell:next.rawCells()){//某个row key下的循坏 // System.out.println(next.toString()); // System.out.println("family:" + Bytes.toString(CellUtil.cloneFamily(cell))); // System.out.println("col:" + Bytes.toString(CellUtil.cloneQualifier(cell))); // System.out.println("value" + Bytes.toString(CellUtil.cloneValue(cell))); // } // } // table.close(); HBaseTest hbasetest =new HBaseTest(); // hbasetest.insertValue(); // hbasetest.getValue(); // hbasetest.delete(); // hbasetest.scanValue(); // hbasetest.createTable("test_table4", "f"); hbasetest.deleteTable("test_table4");//先判断表是否存在,再来删除HBase表(生产开发首推) } //生产开发中,建议这样用线程池做 // public void insertValue() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Put put = new Put(Bytes.toBytes("row_01"));//行键是row_01 // put.add(Bytes.toBytes("f"),Bytes.toBytes("name"),Bytes.toBytes("Andy0")); // table.put(put); // table.close(); // } //生产开发中,建议这样用线程池做 // public void getValue() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Get get = new Get(Bytes.toBytes("row_03")); // get.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name")); // org.apache.hadoop.hbase.client.Result rest = table.get(get); // System.out.println(rest.toString()); // table.close(); // } // //生产开发中,建议这样用线程池做 // public void delete() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Delete delete = new Delete(Bytes.toBytes("row_01")); // delete.deleteColumn(Bytes.toBytes("f"), Bytes.toBytes("name"));//deleteColumn是删除某一个列簇里的最新时间戳版本。 //// delete.deleteColumns(Bytes.toBytes("f"), Bytes.toBytes("name"));//delete.deleteColumns是删除某个列簇里的所有时间戳版本。 // table.delete(delete); // table.close(); // // } //生产开发中,建议这样用线程池做 // public void scanValue() throws Exception{ // HTableInterface table = TableConnection.getConnection().getTable(TableName.valueOf("test_table")); // Scan scan = new Scan(); // scan.setStartRow(Bytes.toBytes("row_02"));//包含开始行键 // scan.setStopRow(Bytes.toBytes("row_04"));//不包含结束行键 // scan.addColumn(Bytes.toBytes("f"), Bytes.toBytes("name")); // ResultScanner rst = table.getScanner(scan);//整个循环 // System.out.println(rst.toString()); // for (org.apache.hadoop.hbase.client.Result next = rst.next();next !=null;next = rst.next() ) // { // for(Cell cell:next.rawCells()){//某个row key下的循坏 // System.out.println(next.toString()); // System.out.println("family:" + Bytes.toString(CellUtil.cloneFamily(cell))); // System.out.println("col:" + Bytes.toString(CellUtil.cloneQualifier(cell))); // System.out.println("value" + Bytes.toString(CellUtil.cloneValue(cell))); // } // } // table.close(); // } // //生产开发中,建议这样用线程池做 // public void createTable(String tableName,String family) throws MasterNotRunningException, ZooKeeperConnectionException, IOException{ // Configuration conf = HBaseConfiguration.create(getConfig()); // HBaseAdmin admin = new HBaseAdmin(conf); // HTableDescriptor tableDesc = new HTableDescriptor(TableName.valueOf(tableName)); // HColumnDescriptor hcd = new HColumnDescriptor(family); // hcd.setMaxVersions(3); //// hcd.set//很多的带创建操作,我这里只抛砖引玉的作用 // tableDesc.addFamily(hcd); // admin.createTable(tableDesc); // admin.close(); // } public void deleteTable(String tableName)throws MasterNotRunningException, ZooKeeperConnectionException, IOException{ Configuration conf = HBaseConfiguration.create(getConfig()); HBaseAdmin admin = new HBaseAdmin(conf); if (admin.tableExists(tableName)){ admin.disableTable(tableName); admin.deleteTable(tableName); }else{ System.out.println(tableName + "not exist"); } admin.close(); } public static Configuration getConfig(){ Configuration configuration = new Configuration(); // conf.set("hbase.rootdir","hdfs:HadoopMaster:9000/hbase"); configuration.set("hbase.zookeeper.quorum", "HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181"); return configuration; } } 2016-12-11 16:27:50,172 INFO [org.apache.hadoop.hbase.zookeeper.RecoverableZooKeeper] - Process identifier=hconnection-0x75e56da connecting to ZooKeeper ensemble=HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181 2016-12-11 16:27:50,187 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT 2016-12-11 16:27:50,187 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:host.name=WIN-BQOBV63OBNM 2016-12-11 16:27:50,187 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.version=1.7.0_51 2016-12-11 16:27:50,187 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.vendor=Oracle Corporation 2016-12-11 16:27:50,187 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.home=C:\Program Files\Java\jdk1.7.0_51\jre 2016-12-11 16:27:50,187 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.class.path=D:\Code\MyEclipseJavaCode\HbaseProject\bin;D:\SoftWare\hbase-1.2.3\lib\activation-1.1.jar;D:\SoftWare\hbase-1.2.3\lib\aopalliance-1.0.jar;D:\SoftWare\hbase-1.2.3\lib\apacheds-i18n-2.0.0-M15.jar;D:\SoftWare\hbase-1.2.3\lib\apacheds-kerberos-codec-2.0.0-M15.jar;D:\SoftWare\hbase-1.2.3\lib\api-asn1-api-1.0.0-M20.jar;D:\SoftWare\hbase-1.2.3\lib\api-util-1.0.0-M20.jar;D:\SoftWare\hbase-1.2.3\lib\asm-3.1.jar;D:\SoftWare\hbase-1.2.3\lib\avro-1.7.4.jar;D:\SoftWare\hbase-1.2.3\lib\commons-beanutils-1.7.0.jar;D:\SoftWare\hbase-1.2.3\lib\commons-beanutils-core-1.8.0.jar;D:\SoftWare\hbase-1.2.3\lib\commons-cli-1.2.jar;D:\SoftWare\hbase-1.2.3\lib\commons-codec-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\commons-collections-3.2.2.jar;D:\SoftWare\hbase-1.2.3\lib\commons-compress-1.4.1.jar;D:\SoftWare\hbase-1.2.3\lib\commons-configuration-1.6.jar;D:\SoftWare\hbase-1.2.3\lib\commons-daemon-1.0.13.jar;D:\SoftWare\hbase-1.2.3\lib\commons-digester-1.8.jar;D:\SoftWare\hbase-1.2.3\lib\commons-el-1.0.jar;D:\SoftWare\hbase-1.2.3\lib\commons-httpclient-3.1.jar;D:\SoftWare\hbase-1.2.3\lib\commons-io-2.4.jar;D:\SoftWare\hbase-1.2.3\lib\commons-lang-2.6.jar;D:\SoftWare\hbase-1.2.3\lib\commons-logging-1.2.jar;D:\SoftWare\hbase-1.2.3\lib\commons-math-2.2.jar;D:\SoftWare\hbase-1.2.3\lib\commons-math3-3.1.1.jar;D:\SoftWare\hbase-1.2.3\lib\commons-net-3.1.jar;D:\SoftWare\hbase-1.2.3\lib\disruptor-3.3.0.jar;D:\SoftWare\hbase-1.2.3\lib\findbugs-annotations-1.3.9-1.jar;D:\SoftWare\hbase-1.2.3\lib\guava-12.0.1.jar;D:\SoftWare\hbase-1.2.3\lib\guice-3.0.jar;D:\SoftWare\hbase-1.2.3\lib\guice-servlet-3.0.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-annotations-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-auth-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-client-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-common-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-hdfs-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-mapreduce-client-app-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-mapreduce-client-common-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-mapreduce-client-core-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-mapreduce-client-jobclient-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-mapreduce-client-shuffle-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-yarn-api-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-yarn-client-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-yarn-common-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hadoop-yarn-server-common-2.5.1.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-annotations-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-annotations-1.2.3-tests.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-client-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-common-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-common-1.2.3-tests.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-examples-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-external-blockcache-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-hadoop2-compat-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-hadoop-compat-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-it-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-it-1.2.3-tests.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-prefix-tree-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-procedure-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-protocol-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-resource-bundle-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-rest-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-server-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-server-1.2.3-tests.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-shell-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\hbase-thrift-1.2.3.jar;D:\SoftWare\hbase-1.2.3\lib\htrace-core-3.1.0-incubating.jar;D:\SoftWare\hbase-1.2.3\lib\httpclient-4.2.5.jar;D:\SoftWare\hbase-1.2.3\lib\httpcore-4.4.1.jar;D:\SoftWare\hbase-1.2.3\lib\jackson-core-asl-1.9.13.jar;D:\SoftWare\hbase-1.2.3\lib\jackson-jaxrs-1.9.13.jar;D:\SoftWare\hbase-1.2.3\lib\jackson-mapper-asl-1.9.13.jar;D:\SoftWare\hbase-1.2.3\lib\jackson-xc-1.9.13.jar;D:\SoftWare\hbase-1.2.3\lib\jamon-runtime-2.4.1.jar;D:\SoftWare\hbase-1.2.3\lib\jasper-compiler-5.5.23.jar;D:\SoftWare\hbase-1.2.3\lib\jasper-runtime-5.5.23.jar;D:\SoftWare\hbase-1.2.3\lib\javax.inject-1.jar;D:\SoftWare\hbase-1.2.3\lib\java-xmlbuilder-0.4.jar;D:\SoftWare\hbase-1.2.3\lib\jaxb-api-2.2.2.jar;D:\SoftWare\hbase-1.2.3\lib\jaxb-impl-2.2.3-1.jar;D:\SoftWare\hbase-1.2.3\lib\jcodings-1.0.8.jar;D:\SoftWare\hbase-1.2.3\lib\jersey-client-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\jersey-core-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\jersey-guice-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\jersey-json-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\jersey-server-1.9.jar;D:\SoftWare\hbase-1.2.3\lib\jets3t-0.9.0.jar;D:\SoftWare\hbase-1.2.3\lib\jettison-1.3.3.jar;D:\SoftWare\hbase-1.2.3\lib\jetty-6.1.26.jar;D:\SoftWare\hbase-1.2.3\lib\jetty-sslengine-6.1.26.jar;D:\SoftWare\hbase-1.2.3\lib\jetty-util-6.1.26.jar;D:\SoftWare\hbase-1.2.3\lib\joni-2.1.2.jar;D:\SoftWare\hbase-1.2.3\lib\jruby-complete-1.6.8.jar;D:\SoftWare\hbase-1.2.3\lib\jsch-0.1.42.jar;D:\SoftWare\hbase-1.2.3\lib\jsp-2.1-6.1.14.jar;D:\SoftWare\hbase-1.2.3\lib\jsp-api-2.1-6.1.14.jar;D:\SoftWare\hbase-1.2.3\lib\junit-4.12.jar;D:\SoftWare\hbase-1.2.3\lib\leveldbjni-all-1.8.jar;D:\SoftWare\hbase-1.2.3\lib\libthrift-0.9.3.jar;D:\SoftWare\hbase-1.2.3\lib\log4j-1.2.17.jar;D:\SoftWare\hbase-1.2.3\lib\metrics-core-2.2.0.jar;D:\SoftWare\hbase-1.2.3\lib\netty-all-4.0.23.Final.jar;D:\SoftWare\hbase-1.2.3\lib\paranamer-2.3.jar;D:\SoftWare\hbase-1.2.3\lib\protobuf-java-2.5.0.jar;D:\SoftWare\hbase-1.2.3\lib\servlet-api-2.5.jar;D:\SoftWare\hbase-1.2.3\lib\servlet-api-2.5-6.1.14.jar;D:\SoftWare\hbase-1.2.3\lib\slf4j-api-1.7.7.jar;D:\SoftWare\hbase-1.2.3\lib\slf4j-log4j12-1.7.5.jar;D:\SoftWare\hbase-1.2.3\lib\snappy-java-1.0.4.1.jar;D:\SoftWare\hbase-1.2.3\lib\spymemcached-2.11.6.jar;D:\SoftWare\hbase-1.2.3\lib\xmlenc-0.52.jar;D:\SoftWare\hbase-1.2.3\lib\xz-1.0.jar;D:\SoftWare\hbase-1.2.3\lib\zookeeper-3.4.6.jar 2016-12-11 16:27:50,188 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.library.path=C:\Program Files\Java\jdk1.7.0_51\bin;C:\Windows\Sun\Java\bin;C:\Windows\system32;C:\Windows;C:\ProgramData\Oracle\Java\javapath;C:\Python27\;C:\Python27\Scripts;C:\Windows\system32;C:\Windows;C:\Windows\System32\Wbem;C:\Windows\System32\WindowsPowerShell\v1.0\;D:\SoftWare\MATLAB R2013a\runtime\win64;D:\SoftWare\MATLAB R2013a\bin;C:\Program Files (x86)\IDM Computer Solutions\UltraCompare;C:\Program Files\Java\jdk1.7.0_51\bin;C:\Program Files\Java\jdk1.7.0_51\jre\bin;D:\SoftWare\apache-ant-1.9.0\bin;HADOOP_HOME\bin;D:\SoftWare\apache-maven-3.3.9\bin;D:\SoftWare\Scala\bin;D:\SoftWare\Scala\jre\bin;%MYSQL_HOME\bin;D:\SoftWare\MySQL Server\MySQL Server 5.0\bin;D:\SoftWare\apache-tomcat-7.0.69\bin;%C:\Windows\System32;%C:\Windows\SysWOW64;D:\SoftWare\SSH Secure Shell;. 2016-12-11 16:27:50,188 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.io.tmpdir=C:\Users\ADMINI~1\AppData\Local\Temp\ 2016-12-11 16:27:50,188 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:java.compiler=<NA> 2016-12-11 16:27:50,188 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:os.name=Windows 7 2016-12-11 16:27:50,188 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:os.arch=amd64 2016-12-11 16:27:50,188 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:os.version=6.1 2016-12-11 16:27:50,188 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:user.name=Administrator 2016-12-11 16:27:50,188 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:user.home=C:\Users\Administrator 2016-12-11 16:27:50,189 INFO [org.apache.zookeeper.ZooKeeper] - Client environment:user.dir=D:\Code\MyEclipseJavaCode\HbaseProject 2016-12-11 16:27:50,190 INFO [org.apache.zookeeper.ZooKeeper] - Initiating client connection, connectString=HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181 sessionTimeout=90000 watcher=hconnection-0x75e56da0x0, quorum=HadoopMaster:2181,HadoopSlave1:2181,HadoopSlave2:2181, baseZNode=/hbase 2016-12-11 16:27:50,251 INFO [org.apache.zookeeper.ClientCnxn] - Opening socket connection to server HadoopSlave1/192.168.80.11:2181. Will not attempt to authenticate using SASL (unknown error) 2016-12-11 16:27:50,253 INFO [org.apache.zookeeper.ClientCnxn] - Socket connection established to HadoopSlave1/192.168.80.11:2181, initiating session 2016-12-11 16:27:50,269 INFO [org.apache.zookeeper.ClientCnxn] - Session establishment complete on server HadoopSlave1/192.168.80.11:2181, sessionid = 0x25872b4d2c50021, negotiated timeout = 40000test_table4not exist 2016-12-11 16:27:51,483 INFO [org.apache.hadoop.hbase.client.ConnectionManager$HConnectionImplementation] - Closing zookeeper sessionid=0x25872b4d2c50021 2016-12-11 16:27:51,725 INFO [org.apache.zookeeper.ZooKeeper] - Session: 0x25872b4d2c50021 closed 2016-12-11 16:27:51,735 INFO [org.apache.zookeeper.ClientCnxn] - EventThread shut down 本文转自大数据躺过的坑博客园博客,原文链接:http://www.cnblogs.com/zlslch/p/6159857.html,如需转载请自行联系原作者