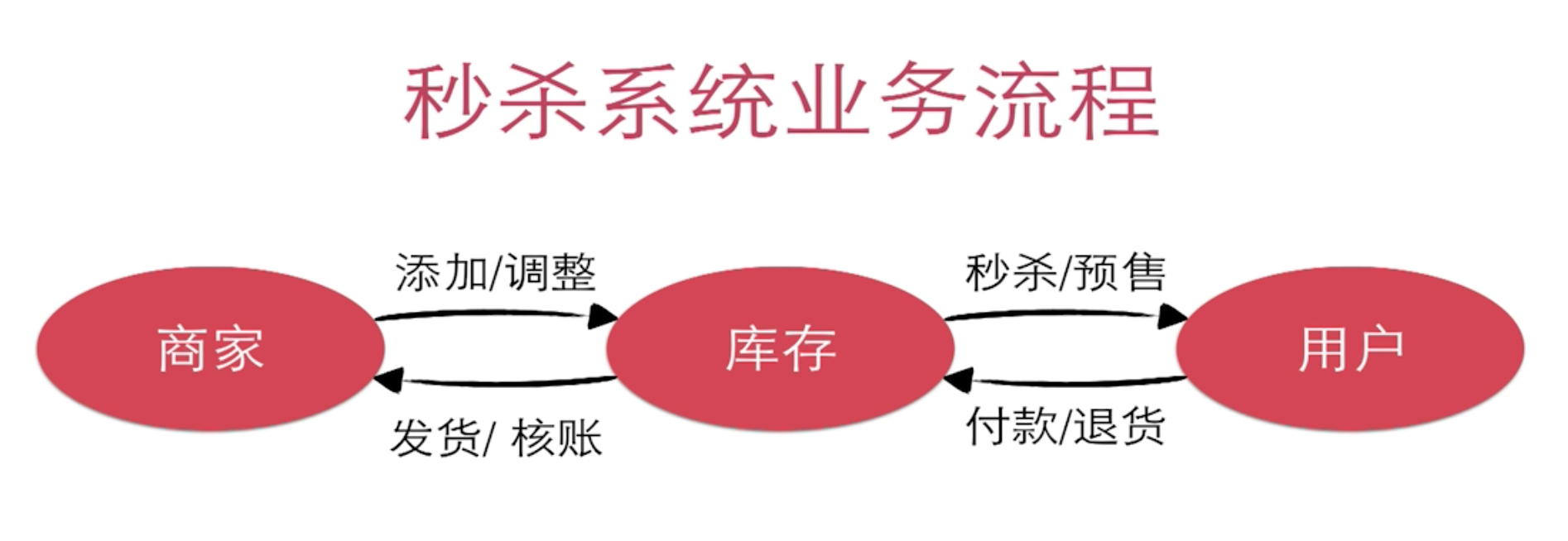
Java高并发秒杀Api-业务分析与DAO层构建3
章节目录 mybatis与spring整合过程 spring-dao.xml 配置 junit4 单元测试 1.mybatis与spring整合过程 1.1 spring-dao.xml 配置 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd"> <!--配置整合mybatis--> <!--1:配置数据库相关参数--> <!-- 1:配置数据库相关参数properties的属性:${url} --> <context:property-placeholder location="classpath:jdbc.properties"/> <!--2.数据库连接池配置--> <bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource"> <!-- 配置连接池属性--> <property name="driverClass" value="${driver}" /> <property name="jdbcUrl" value="${url}" /> <property name="user" value="${username}" /> <property name="password" value="${password}" /> <!-- c3p0连接池的私有属性--> <property name="maxPoolSize" value="30" /> <property name="minPoolSize" value="10" /> <!-- 关闭连接后不自动commit--> <property name="autoCommitOnClose" value="false" /> <!-- 获取连接超时时间 30个连接用完--> <property name="checkoutTimeout" value="1000" /> <!-- 当获取连接失败重试次数--> <property name="acquireRetryAttempts" value="2" /> </bean> <!-- 约定大于配置--> <!-- 3:配置SqlSessionFactory对象--> <bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"> <!-- 注入数据库连接池--> <property name="dataSource" ref="dataSource" /> <!-- 配置MyBatis全局配置文件:mybatis-config.xml--> <property name="configLocation" value="classpath:mybatis-config.xml" /> <!-- 扫描entity包 使用别名--> <property name="typeAliasesPackage" value="org.seckill.domain" /> <!-- 扫描sql配置文件;mapper需要的xml文件--> <property name="mapperLocations" value="classpath:mapper/*.xml" /> </bean> <!--配置扫描Dao接口包,动态实现Dao接口 mapper 代理,并注入到Spring容器中 MapperScannerConfigurer--> <bean class="org.mybatis.spring.mapper.MapperScannerConfigurer"> <!--注入sqlSessionFactory,懒加载,用到的时候才加载--> <property name="sqlSessionFactoryBeanName" value="sqlSessionFactory"></property> <!--给出扫描DAO接口包--> <property name="basePackage" value="org.seckill.dao"></property> </bean> </beans> 2.junit 单元测试 SecKillDaoTest.java - 测试秒杀 package org.seckill.dao; import org.junit.Test; import org.junit.runner.RunWith; import org.seckill.domain.SecKill; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.test.context.ContextConfiguration; import org.springframework.test.context.junit4.SpringJUnit4ClassRunner; import java.util.Date; import java.util.List; /** * 配置spring 与 junit 启动时加载Spring IOC容器 * spring-test,junit整合 * 告诉junit Spring配置文件位置 */ @RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration({"classpath:spring/spring-dao.xml"}) public class SecKillDaoTest { //注入Dao类实现 @Autowired private SecKillDao secKillDao; @Test public void queryById() throws Exception { long id = 1000; SecKill secKill = secKillDao.queryById(id); System.out.println(secKill.getName()); System.out.println(secKill); /** * 1000元秒杀iphone x SecKill{seckillId=1000, name='1000元秒杀iphone x', stock=100, startTime=Fri May 04 00:00:00 CST 2018, endTime=Sat May 05 00:00:00 CST 2018, createTime=Sat May 05 00:05:03 CST 2018 } */ } /** * @throws Exception */ @Test public void queryAll() throws Exception { // queryAll(offset,limit)->queryAll(arg0,arg1) List<SecKill> secKillList = secKillDao.queryAll(0, 100); for (SecKill secKill : secKillList) { System.out.println(secKill); } /** * SecKill{seckillId=1000, name='1000元秒杀iphone x', stock=100, startTime=Fri May 04 00:00:00 CST 2018, endTime=Sat May 05 00:00:00 CST 2018, createTime=Sat May 05 00:05:03 CST 2018} SecKill{seckillId=1001, name='500元秒杀ipad x', stock=200, startTime=Fri May 04 00:00:00 CST 2018, endTime=Sat May 05 00:00:00 CST 2018, createTime=Sat May 05 00:05:03 CST 2018} SecKill{seckillId=1002, name='300元秒杀小米4', stock=300, startTime=Fri May 04 00:00:00 CST 2018, endTime=Sat May 05 00:00:00 CST 2018, createTime=Sat May 05 00:05:03 CST 2018} SecKill{seckillId=1003, name='200元秒杀小米note', stock=400, startTime=Fri May 04 00:00:00 CST 2018, endTime=Sat May 05 00:00:00 CST 2018, createTime=Sat May 05 00:05:03 CST 2018} */ } @Test public void reduceStock() throws Exception { Date killTime = new Date(); int updateCount = secKillDao.reduceStock(1000L, killTime); System.out.println(updateCount); } } 测试秒杀明细 package org.seckill.dao; import org.junit.Test; import org.junit.runner.RunWith; import org.seckill.domain.SuccessKilled; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.test.context.ContextConfiguration; import org.springframework.test.context.junit4.SpringJUnit4ClassRunner; @RunWith(SpringJUnit4ClassRunner.class) @ContextConfiguration("classpath:spring/spring-dao.xml") public class SuccessKilledDaoTest { @Autowired private SuccessKilledDao successKilledDao; @Test public void insertSuccessKilled() throws Exception { int successCount = successKilledDao.insertSuccessKilled(1001L, "15300815999"); System.out.println("insertCount=" + successCount); } @Test public void queryByIdWithSecKill() throws Exception { //1个用户只能查询到属于自己的一个秒杀明细 long id = 1001L; String phone = "15300815999"; SuccessKilled successKilled = successKilledDao.queryByIdWithSecKill(id, phone); System.out.println(successKilled); } } 接下来是service 层的构建