【Java入门提高篇】Day15 Java泛型再探——泛型通配符及上下边界
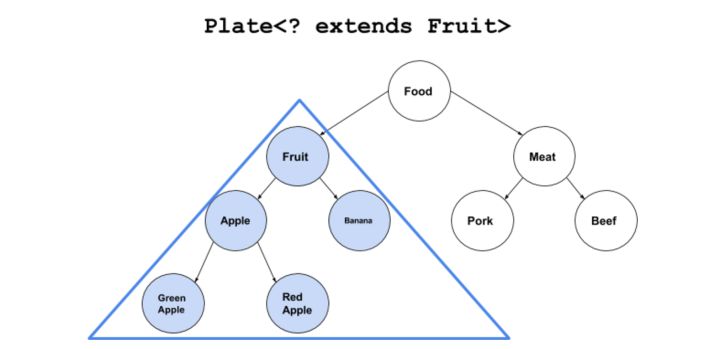
上篇文章中介绍了泛型是什么,为什么要使用泛型以及如何使用泛型,相信大家对泛型有了一个基本的了解,本篇将继续讲解泛型的使用,让你对泛型有一个更好的掌握和更深入的认识。 上篇中介绍完泛型之后,是不是觉得泛型挺好用的?既消除了Object的不安全类型转化,又可以很方便的进行类型对象的存取,但是,等一下,有没有考虑到这样的情况。 我们先定义一个水果类: public class Fruit { private String name; public Fruit(String name){ this.name = name; } public String getName() { return name; } public void setName(String name) { this.name = name; } } 然后再定义一个苹果类: public class Apple extends Fruit{ public Apple(String name) { super(name); } } 接下来定义一个泛型容器: public class GenericHolder<T> { private T obj; public GenericHolder(){} public GenericHolder(T obj){ this.obj = obj; } public T getObj() { return obj; } public void setObj(T obj) { this.obj = obj; } } 接下来开始我们的测试: public class Test { /** * 吃水果 * @param fruitHolder */ public static void eatFruit(GenericHolder<Fruit> fruitHolder){ System.out.println("我正在吃 " + fruitHolder.getObj().getName()); } public static void main(String args[]){ //这是一个贴了水果标签的袋子 GenericHolder<Fruit> fruitHolder = new GenericHolder<Fruit>(); //这是一个贴了苹果标签的袋子 GenericHolder<Apple> appHolder = new GenericHolder<Apple>(); //这是一个水果 Fruit fruit = new Fruit("水果"); //这是一个苹果 Apple apple = new Apple("苹果"); //现在我们把水果放进去 fruitHolder.setObj(fruit); //调用一下吃水果的方法 eatFruit(fruitHolder); //贴了水果标签的袋子放水果当然没有问题 //现在我们把水果的子类——苹果放到这个袋子里看看 fruitHolder.setObj(apple); //同样是可以的,其实这时候会发生自动向上转型,apple向上转型为Fruit类型后再传入fruitHolder中 //但不能再将取出来的对象赋值给redApple了 //因为袋子的标签是水果,所以取出来的对象只能赋值给水果类的变量 //无法通过编译检测 redApple = fruitHolder.getObj(); eatFruit(fruitHolder); //放苹果的标签,自然只能放苹果 appHolder.setObj(apple); // 这时候无法把appHolder 传入eatFruit // 因为GenericHolder<Fruit> 和 GenericHolder<Apple>是两种不同的类型 // eatFruit(appHolder); } } 运行结果: 我正在吃 水果 我正在吃 苹果 在这里,我们往eatFruit方法里传入fuitHolder的时候,是可以正常编译的,但是如果将appHolder传入,就无法通过编译了,因为作为参数时,GenericHolder<Fruit> 和 GenericHolder<Apple>是两种不同的类型,所以无法通过编译,那么问题来了,如果我想让eatFruit方法能同时处理GenericHolder<Fruit> 和 GenericHolder<Apple>两种类型怎么办?而且这也是很合理的需求,毕竟Apple是Fruit的子类,能吃水果,为啥不能吃苹果???如果要把这个方法重载一次,未免也有些小题大做了(而且事实上也无法通过编译,具体原因之后会有说明)。 在代码的逻辑里: 苹果 IS-A 水果 装苹果的盘子 NOT-IS-A 装水果的盘子 这个时候,泛型的边界符就有它的用武之地了。我们先来看效果: public class Test { /** * 吃水果 * @param fruitHolder */ public static void eatFruit(GenericHolder<? extends Fruit> fruitHolder){ System.out.println("我正在吃 " + fruitHolder.getObj().getName()); } public static void main(String args[]){ //这是一个贴了水果标签的袋子 GenericHolder<Fruit> fruitHolder = new GenericHolder<Fruit>(); //这是一个贴了苹果标签的袋子 GenericHolder<Apple> appHolder = new GenericHolder<Apple>(); //这是一个水果 Fruit fruit = new Fruit("水果"); //这是一个苹果 Apple apple = new Apple("苹果"); //现在我们把水果放进去 fruitHolder.setObj(fruit); //调用一下吃水果的方法 eatFruit(fruitHolder); //放苹果的标签,自然只能放苹果 appHolder.setObj(apple); // 这时候可以顺利把appHolder 传入eatFruit eatFruit(appHolder); } } 运行结果: 我正在吃 水果 我正在吃 苹果 这里我们只是使用了一点小小的魔法,把参数类型改成了GenericHolder<? extends Fruit>,这样就能将GenericHolder<Apple>类型的参数顺利传入了,怎么样?很好用吧,这就是泛型的边界符,用<? extends Fruit>的形式表示。边界符的意思,自然就是定义一个边界,这里用?表示传入的泛型类型不是固定类型,而是符合规则范围的所有类型,用extends关键字定义了一个上边界,也就是说这里的?可以代表任何继承于Fruit的类型,你也许会问,为什么是上边界,好问题,一图胜千言: 从这个图可以很好的看出这个“上边界”的概念了吧。有上边界,自然有下边界,泛型里使用形如<? super Fruit>的方式使用下边界,此时,?只能代表Fruit及其父类。 (这两个图是抠过来的,不要骂我懒。) 这两种方式基本上解决了我们之前的问题,但是同时,也有一定的限制。 1.上界<? extends T>不能往里存,只能往外取 不要太疑惑,其实很好理解,因为编译器只知道容器里的是Fruit或者Fruit的子类,但不知道它具体是什么类型,所以存的时候,无法判断是否要存入的数据的类型与容器种的类型一致,所以会拒绝set操作。 2.下界<? super T>往外取只能赋值给Object变量,不影响往里存 因为编译器只知道它是Fruit或者它的父类,这样实际上是放松了类型限制,Fruit的父类一直到Object类型的对象都可以往里存,但是取的时候,就只能当成Object对象使用了。 所以如果需要经常往外读,则使用<? extends T>,如果需要经常往外取,则使用<? super T>。 至此,本篇讲解完毕,欢迎大家继续关注! 真正重要的东西,用眼睛是看不见的。