上次分享了一篇关于 Tomcat 的文章《
写一款 Tomcat 也没有那么难》,真有读者去下载了 Tomcat 的源码来研读,但搞了很久也没有把它在 IDEA 的开发环境给成功跑起来。
因此,我写这篇文章来解答一下,也希望本文能达到抛砖引玉的作用。
要读 Tomcat 的源码,必须要提一个大神,那就是 James Duncan Davidson,这个老头不光是 Tomcat 的创始人,还是 Ant 的创始人。
曾有人问 James Duncan Davidson,Tomcat 为什么会如此流行?他回答源于Tomcat 是开源的,任何人都可以使用并修改它。
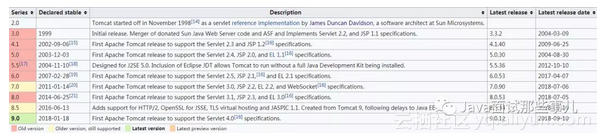
其实,只需去看看 Tomcat 的发展历史「见下图」,便会知道它是如此牛逼,历史之悠久。
![922598ec9eabcef6db8b97c6425b78d9f795f8ce]()
关于为什么叫 Tomcat?我还真去查阅了一些资料,Tomcat之父说,他当初取这个名字是为了让它未来能出现在 O'Reilly 书的封面上。
现在看起来,似乎他当年的想法并未实现,但这只小猫却坚持不懈的服务在全球成千上万的服务器上。
现在 Tomcat 已经托管于 Github 上面,你可以去上面直接下载。
![90fd8ed6b7b8a510cb70573bb87e42215ee710a4]()
当你下载完文件后,在主目录下会发现了一个文件 build.xml ,对于编码阅历比较少的同学很少知道了它了,这便是 Ant 构建项目的文件。关于 Ant 的更多细节,我在这里就不细说了,感兴趣的同学可以去谷歌查阅一下资料。
为什么 Tomcat 会选用 Ant 来构建?在我看来,一是它们都出自 James Duncan Davidson 之手,二是在那个时代没有比 Ant 更好用的自动化构建工具。
你下载完 Tomcat 下来,需要搭建 Ant 的环境,这些操作自行谷歌吧。。。
你查看 build.xml 文件,你会发现它默认给我提供了自动构建 IDEA、Eclipse及 NetBeans 的命令,我这里主要讲怎么在 IDEA 中构建。
首先,执行命令 ant ide-intellij 。
![8f1dca06baae66049f122f2aa9887c7b96a5d7df]()
接着,便会出现如下结果。
![a72b5e30dd94de2d099298ab0877270c3dedc2ab]()
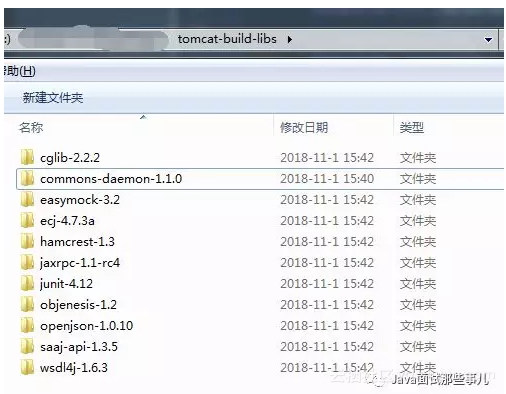
最后,你打开 tomcat-build-libs 目录,便会发现所有的依赖包都放在这里。
![b18bb683fa3095a785dcef13ef4b576ed4dffd07]()
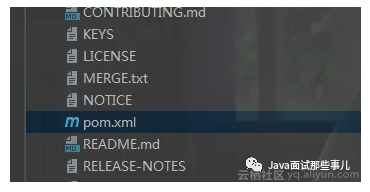
这样怎么导入包,就不用我教你了吧,如果你为了方便,也可以打开 阅读原文 的链接,来访问我已经提供好的 Maven 引入方式,在分支 read 上面,查看 pom.xml 。
![43b133a98af51023fa07b6088ae6d1f52cd11290]()
需要注意的是,你需要配置一下有一个包的依赖路径「见下图」。
![58b2153d4817b05f1f62ac01023f4f3cc179fba0]()
好了,接着来说这位读者遇到的几个问题吧。
1、 不知道启动入口在那里?
org.apache.catalina.startup.Bootstrap.java
需要配置一下 VM 启动参数。
-Dcatalina.home=D:\open-source\tomcat -Dcatalina.base=D:\open-source\tomcat -Djava.endorsed.dirs=D:\open-source\tomcat\endorsed -Djava.io.tmpdir=D:\open-source\tomcat\temp -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djava.util.logging.config.file=D:\open-source\tomcat\conf\logging.properties -Djava.protocol.handler.pkgs=org.apache.catalina.webresources -Djdk.tls.ephemeralDHKeySize=2048
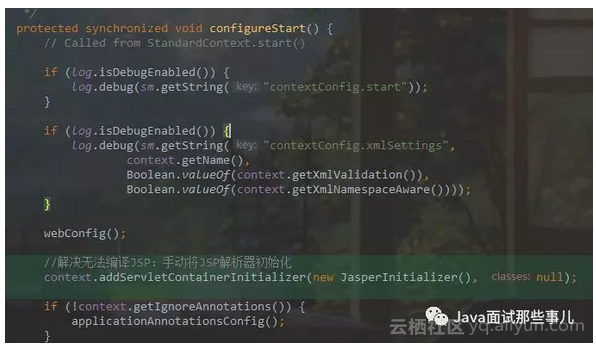
2、程序是运行了,但访问 8080 首页报 500 错误,不知道为什么?
我查看了一下,原来是没有引入 Jsp 页面编译引擎。在 org.apache.catalina.startup.ContextConfig.java 页面的 configureStart() 方法加入如下图所示代码。
![c64f9646050b2f9a7b52d8f6655702ea8ce3950d]()
最后,便能正常编译了。
![f02cb2d14589ff7a8679a0614468565ab2ab0634]()
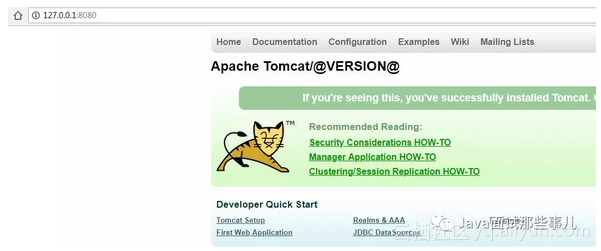
页面也能正常返回了。
![e9abae2a9fb5ca88263dc3b58aea1edb3830a232]()
这几个难住初学者的问题,在一个老手面前可能就是几分钟的事情,不管这个问题难好,简单也好,只要我知道的,我始终愿意帮助那些初学者,毕竟大家都是这么走过来的。
让我感到很高兴的是,这位读者知道,他耽误了我的时间,发了一个红包,表示感谢,说实话,我挺高兴的,不是钱的事,在于他知道从别人哪里获取不是理所应当。
关于怎么玩 IDEA ,我之前也写过一篇文章《谈谈我与 Intellij IDEA 的故事》,可进行查阅相关快捷操作。
好了,今天的分享就到了这里了,后面再给大家分享 Tomcat 内部的实现细节。
原文发布时间为:2018-11-02
本文作者: Java面试那些事儿
本文来自云栖社区合作伙伴“ Java面试那些事儿”,了解相关信息可以关注“Java面试那些事儿”。