在Java语言层面,可以通过Class类来描述普通的Java类,当JVM创建对象的同时,会生成对应的Class对象,用来描述此对象的大致模型,这也是反射的基础。那么在JVM的内部是如何描述一个普通的对象?我们先从一个简单的示例着手,这有一个Child类:
public class Child extends Person implements Action {
// 小孩上几年级
public int grade;
// Action接口就一个动作:walk
@Override
public void walk() {
}
}
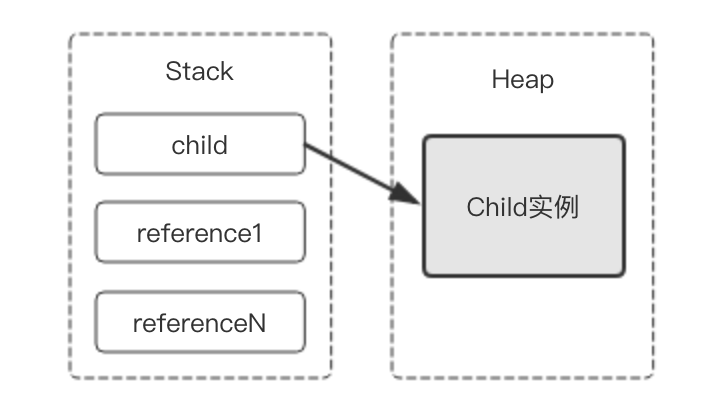
通过Child child = new Child()来创建对象时,JVM在堆中开辟空间存放对象实例数据的同时,会在栈中创建该对象的引用,用于存放child对象在堆内存中的首地址,大致的示意图如下所示。
现在请大家思考:站在JVM的角度,要完整地描述运行时的child对象,需要记录哪些信息?
脑袋里可能马上就会跳出来这些信息:
- 对象所属类的相关信息: 类(包含父类)的名称、实现了哪些接口、是否有注解、方法列表、属性列表、常量等
- 实例数据:对象存储的有效信息,比如对象各个属性存储的具体内容
除了这些呢?其实还有一些运行时的数据,比如:锁信息、线程ID、GC标记等。
JVM是如何记录这些信息的呢?HotSpot VM采用OOP-Klass的模型来描述Java对象实例。
Klass
Klass系对象 (instanceKlass、arrayKlass等) 用于描述对象的元数据,其中instanceKlass可以认为是java.lang.Class的VM级别的表示,但它们并不等价,instanceKlass主要作用于整个程序运行过程中,而Class类只用于Java的反射API,接下来将以instanceKlass为例来介绍Klass,其它对象与之类似。
Klass类定义了所有Klass类型共有的数据结构和行为,比如类型名称、与其它类之间的关系、访问标识符等等,具体可参看:
// 代码来自于hotspot/src/share/vm/oops/klass.hpp
class Klass : public Metadata {
// 反映对象整体布局的描述符,在32位系统中占用4个字节
// 如果值为正数,表示对象大小,如果值为负数,表示数组
jint _layout_helper;
// 类名称,比如:"java/lang/String"表示String对象
// 而[Ljava/lang/String描述String类型的一维数组
Symbol* _name;
// 对应的Java语言层面的Class对象实例
oop _java_mirror;
// 父类,指针指向其父类的首地址
Klass* _super;
// 第一个子类
Klass* _subklass;
// subklass指向第一个子类,如果有多个子类
// 那么可以通过_subklass->next_sibling()找到下一个子类
Klass* _next_sibling;
// Java 中类名和类加载器唯一标识了一个类
// 由同一个类加载器加载的类通过 _next_link 连接起来
Klass* _next_link;
ClassLoaderData* _class_loader_data;
// 访问标识符,Java层面通过 Class.getModifiers()获取
// 比如:1表示public
jint _modifier_flags;
// 类或者接口的访问修饰符
AccessFlags _access_flags;
// ......
HotSpot中为每一个已加载的Java类创建一个instanceKlass对象,用于在JVM层面表示Java类,它包含了虚拟机内部运行一个类所需要的全部信息,这些成员变量在类的解析阶段 (主要是将常量池中的符号引用转换为直接引用,即运行时实际内存地址) 完成赋值:
// 代码来自于hotspot/src/share/vm/oops/instanceKlass.hpp
class InstanceKlass: public Klass {
// 注解
Annotations* _annotations;
// 常量
ConstantPool* _constants;
// 方法列表
Array<Method*>* _methods;
// 方法顺序
Array<int>* _method_ordering;
Array<Method*>* _default_methods;
// 实现的接口
Array<Klass*>* _local_interfaces;
// 继承来的接口
Array<Klass*>* _transitive_interfaces;
// 静态变量的数量
u2 _static_oop_field_count;
// 成员变量的数量
u2 _java_fields_count;
// ......
接下来以文章开头的Child对象为例,观察程序运行过程中Child类型的Klass信息,以加深大家的理解。
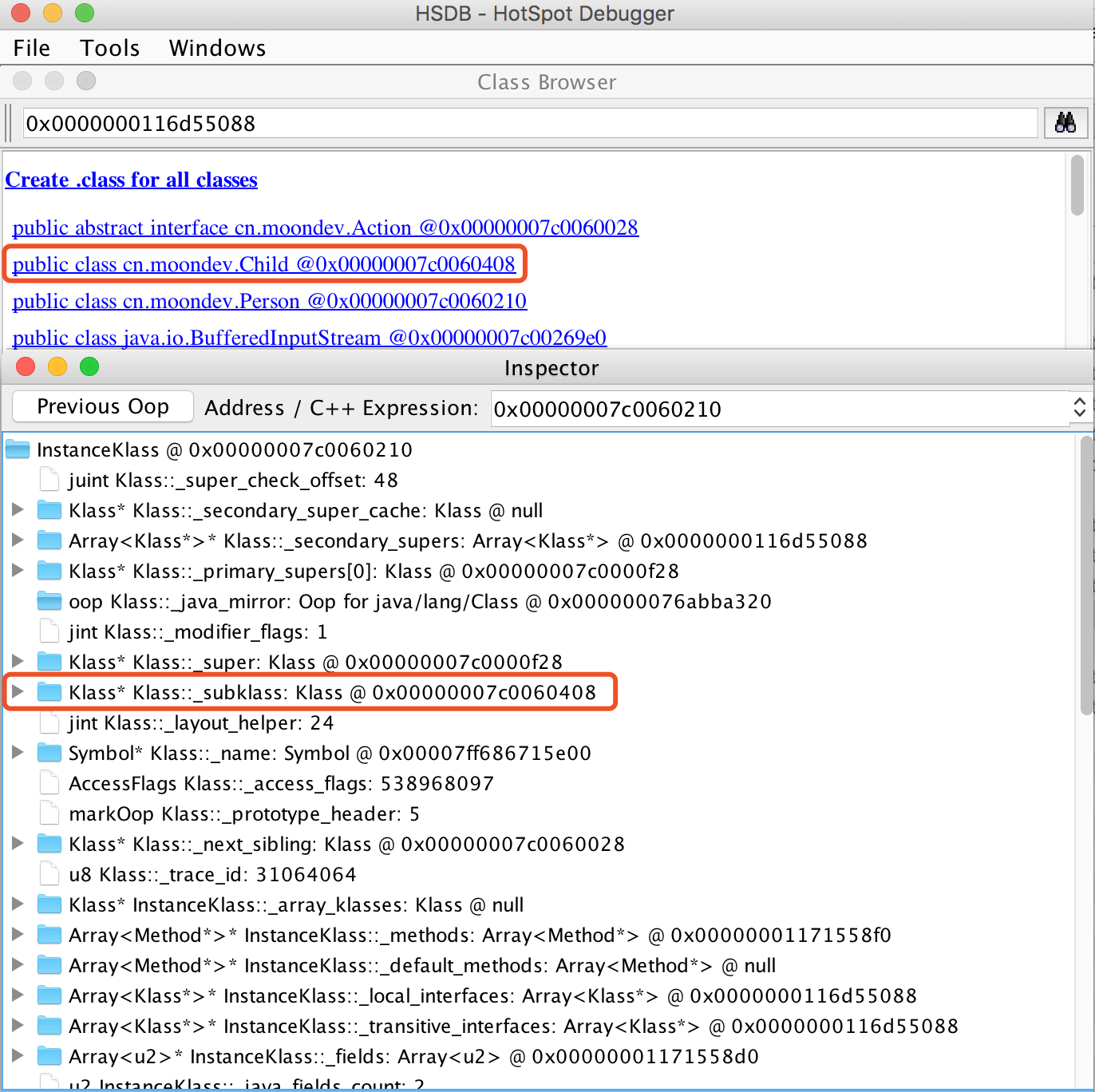
Child类继承Person类并实现的Action的所有接口,通过HSDB来探测Klass对象信息,如下图所示,首先通过HSDB的Class Browser工具列出所有的类,找到我们定义的类,比如Person类实例的内存地址为:0x00000007c0060210,然后使用这个内存地址到Inspector中搜索,即可得到Person类在HotSpot内部instanceKlass类型的全貌,如下图所示。
从图中可以得到,Person类的其中一个子类的Klass对象内存地址_subklass:Klass @ 0x00000007c0060408,通过这个地址可以在Code Browser中很方便的查找到其对应的类是:Child。除此之外,还可以找到一些非常熟悉的属性:
- _super: Klass @ 0x00000007c0000f28 Person类的父类是Object类
- _mofifier_flags: 1 表示 public
- _name: Symbol @ 0x00007ff686715e00 类名称,String对象的内存地址
- _layout_helper: 24 值为正数,表示对象的大小
- _methods: Array<Method> @ 0x00000001171558f0* 方法列表
- ……
属性太多,这里无法一一列举,鼓励大家自己尝试,随便也学习一下怎么使用HSDB来分析JVM内部的数据结构和状态,但不鼓励钻牛角尖似的非要弄清楚每个属性的含义和作用,至少在当前是不需要的。
再回到instanceKlass.hpp里面,对象的注解、常量以及方法,在VM中分别使用Annotations、ConstantPool、Method来描述,它们同Klass一样,均继承自Metadata或者MetaspaceObj类。
在 HotSpot JVM 中,永久代中用于存放类和方法的元数据以及常量池,比如Class和Method。每当一个类初次被加载的时候,它的元数据都会放到永久代中。
需要注意的是,在JDK1.8中已经引入Metaspace (元空间)来替换原来的永久代PermGen,因此,JDK1.8里的对象模型实现与1.7有很大的不同。通过上文的分析,希望能够加深你对这句话的理解。
OOP
OOP用来描述对象的实例信息,在Java程序运行过程中,每创建一个Java对象,在JVM内部也会相应的创建一个OOP对象来表示Java对象。oop的定义oopDesc如下 (oop相关类的定义均会在名称后面添加后缀Desc,比如:instanceOopDesc):
class oopDesc {
private:
// Mark Word
volatile markOop _mark;
// 元数据
// 使用了union来声明metadata是为了在64位机器上对对象指针进行压缩
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
整个oopDesc定义了如下信息:
- _mark (Mark Word):,哈希码,GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID、偏向时间戳
- _metadata (元数据指针):指向描述类型的Klass对象指针,Klass对象包含了实例对象所属类型的元数据
在_metadata中包含一个压缩指针,在32位系统中,对象的指针长度是32位,而在64位系统中,指针长度为64位。在64位系统刚刚兴起的年代,对于那些从32位系统迁移到64位系统的引用来说,平白无故的多了差不多50%的内存占用 (主要是指指针占用的内存,非整个应用的内存占用),基于节约内存的考量,可以在64位系统上对指针占用的内存进行压缩,更多的内容可以参考:-XX:+UseCompressedOops参数。
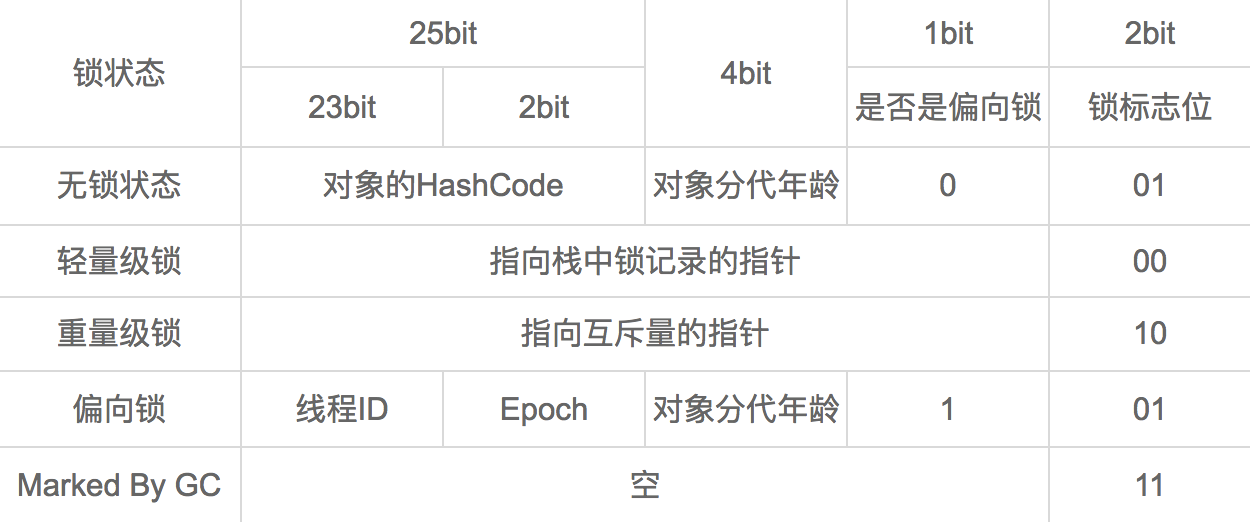
Mark Word存储对象自身的运行时数据,其被设计成一个非固定的数据结构,可在极小的空间内存储尽量多的信息,它会根据自己的状态复用自己的存储空间。比如,在32位系统中,如果对象处于无锁状态,那么Mark Word的32bit空间中的25个bit用于存储对象的hash值,4bit用于存储对象的分代年龄,2bit用于存储锁标志位,1bit用于存储锁的类型;而当对象处于有锁状态下,根据锁的类型不同,存储的数据又不同,具体的示意图如下:
关于表格中涉及到关于锁的信息仅做如下说明,更多相关内容可以关注后面的文章:
- 重量级锁采用互斥量来控制对互斥资源的访问,而轻量级锁通过CAS机制来实现,因此,两种锁的重要区别是:拿到“锁”时,是否存在线程调度和切换上下文的开销。
- 在拿到“锁”这样的描述中,“锁”所指的内容并不一致,重量级锁只要拿到互斥信号,即拿到锁,而CAS操作通过compare是否成功来判断是否拿到锁,因而我们常说的锁,其本质上是是否满足某种条件。因此,注意表格中关于指向指针的描述。
- 几种锁竞争情况由弱到强分别是:无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁。
- Mark Word中如果记录了线程ID,则认为该线程获得了锁,如果将线程ID清空,则认为自己释放了锁,当然还伴随着锁标志位的改变。线程将自己的ID与Mark Word中的线程ID对比,就知道自己是否拿到当前访问对象的锁。
- 如果当前对象被锁住,那么该MarkWord中保存着对应线程的ID,通过锁标志位、是否偏向锁、线程ID等几个值可以区分当前对象是否被锁以及被谁锁住。你可能会有个疑问,轻量级锁和重量级锁的MarkWord中并没有线程ID,那么怎么区分是被哪个线程锁住的呢?其实在轻量级锁加锁的过程中,会拷贝MarkWord到锁记录中去,因此只要知道指向锁记录的指针,也就知道锁的线程ID。那重量级锁呢?由于重量级锁是通过获取互斥信号量的方式,那么这个互斥信号量是否属于当前的线程,其实当前线程是能够判断的,这时候,线程ID就变得没有太大的意义了。
总结
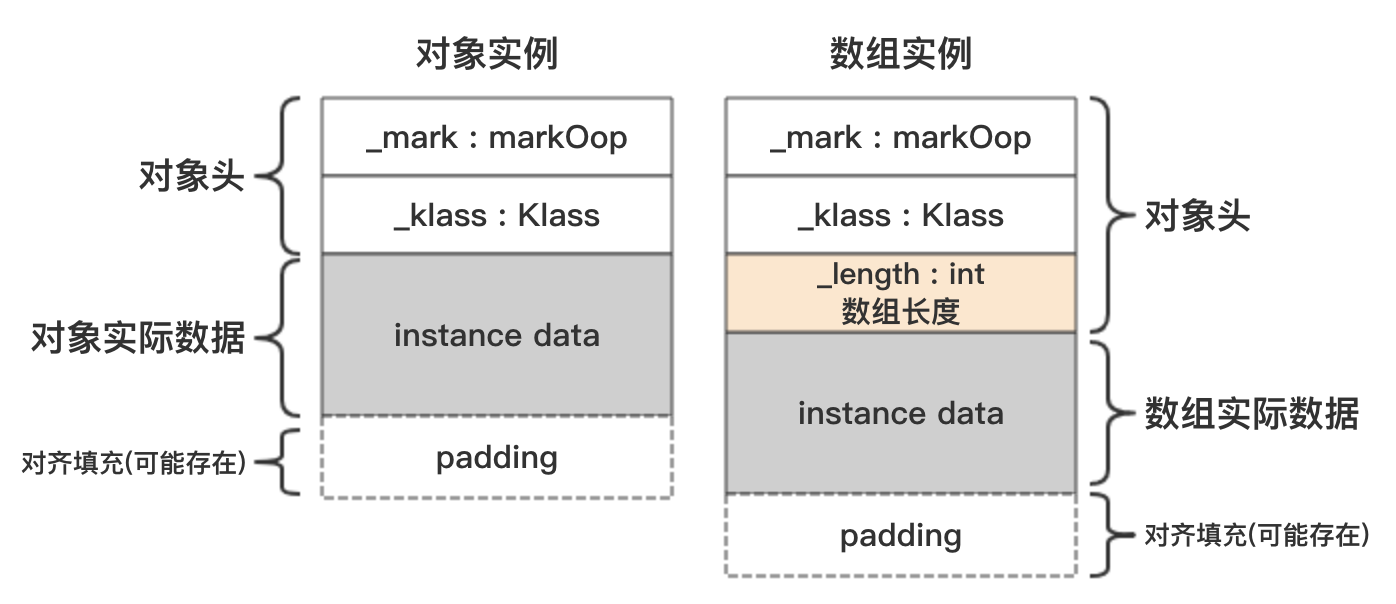
在HotSpot虚拟机中,对象在内存中的布局主要分为3个部分:对象头、实例数据、对齐填充,其示意图如下:
其中,对象头主要存储对象的状态信息以及类的元数据指针,虚拟机可以通过这个指针访问到这个类对应的所有类型信息;而实例数据则是对象真正存储的有效性信息,即在程序代码中锁定义的各种类型的字段内容;对其填充不是一定存在的,也没有特殊的含义,仅仅起到占位的作用:HotSpot要求对象起始地址必须是8字节的整数倍,也就是说对象的大小必须是8的整数倍,因此,当实例数据部分大小不满足8的整数倍时,就需要通过占位符来填充。
最后需要关注的一点是,数组实例相对于对象实例,多了一个数组长度。
引用 (Reference) 将内存中的一个又一个对象连接起来,那何为引用?请继续关注下一个小节。
参考资料
- Thread as a GC root - Stack Overflow
- JVM 中,InstanceKlass、java.lang.Class的关系?
- Java并发编程:Synchronized底层优化