秋招这个时候已经开始了,正所谓知己知彼方能百战不殆,今天就从招聘网站下手分析一波机械的就业前景。
这次获取数据的网站是前程无忧,之所以选择前程无忧,是因为数据获取没有什么难度,再者前程无忧提供的岗位信息比智联招聘,拉勾提供的数据都多。
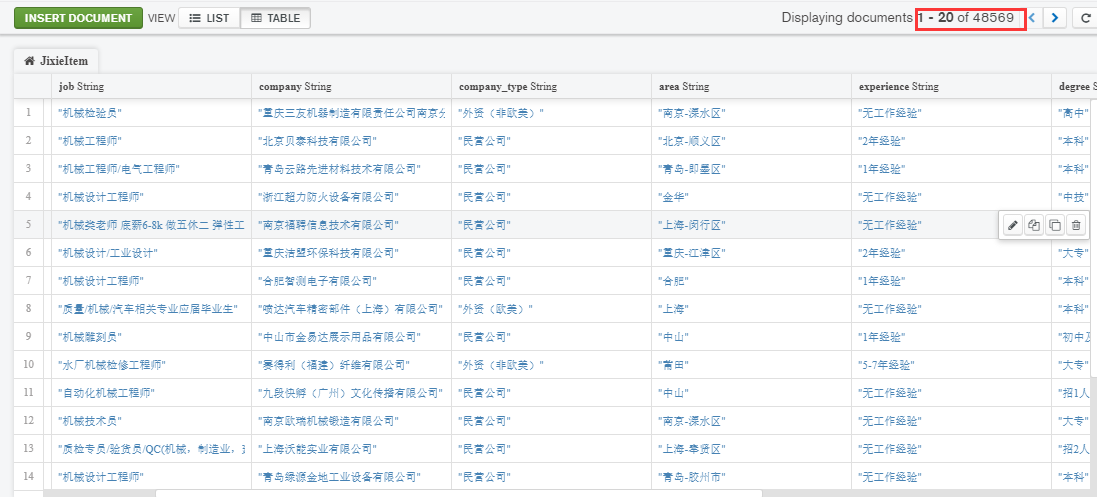
看了一下,前程无忧提供了 2000页/50条 数据,考虑到数据可能有些重复,这里获取 48569 条数据。
数据获取
- 用到的爬虫框架是 scrapy
- 解析库 xpath、re、pymongo
- 保存数据用 mongodb
- 数据处理用 pyecharts。
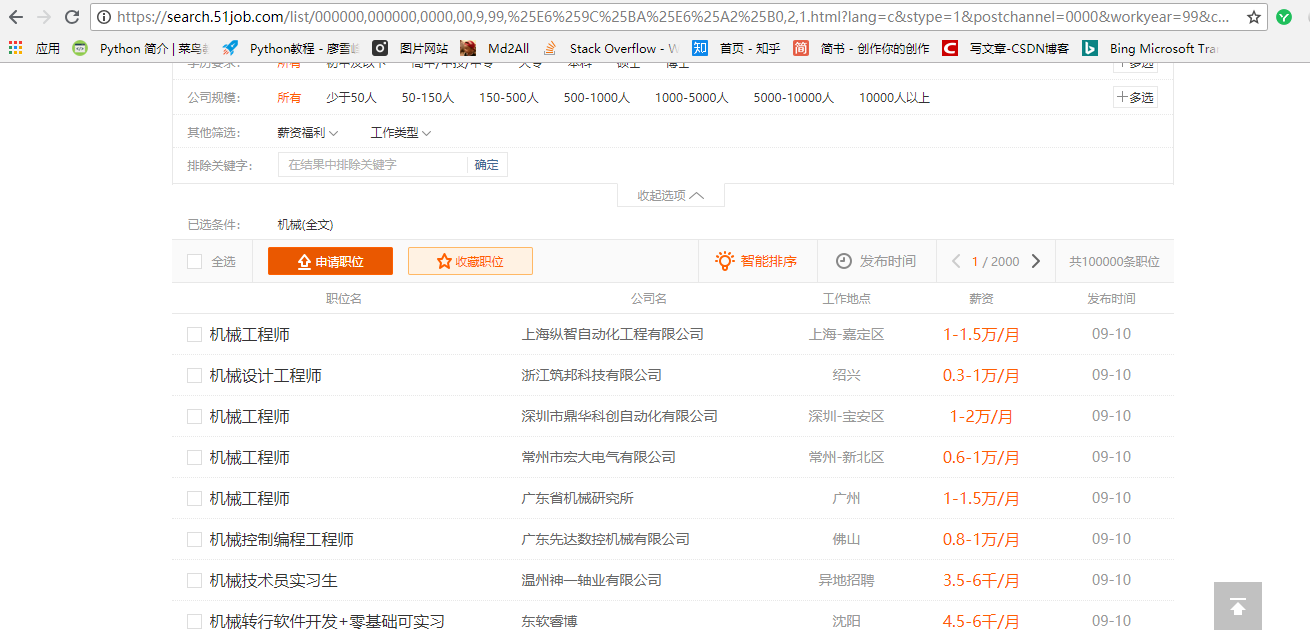
打开 https://www.51job.com/ 在搜索框输入机械,跳转到的网页是这个样子的:
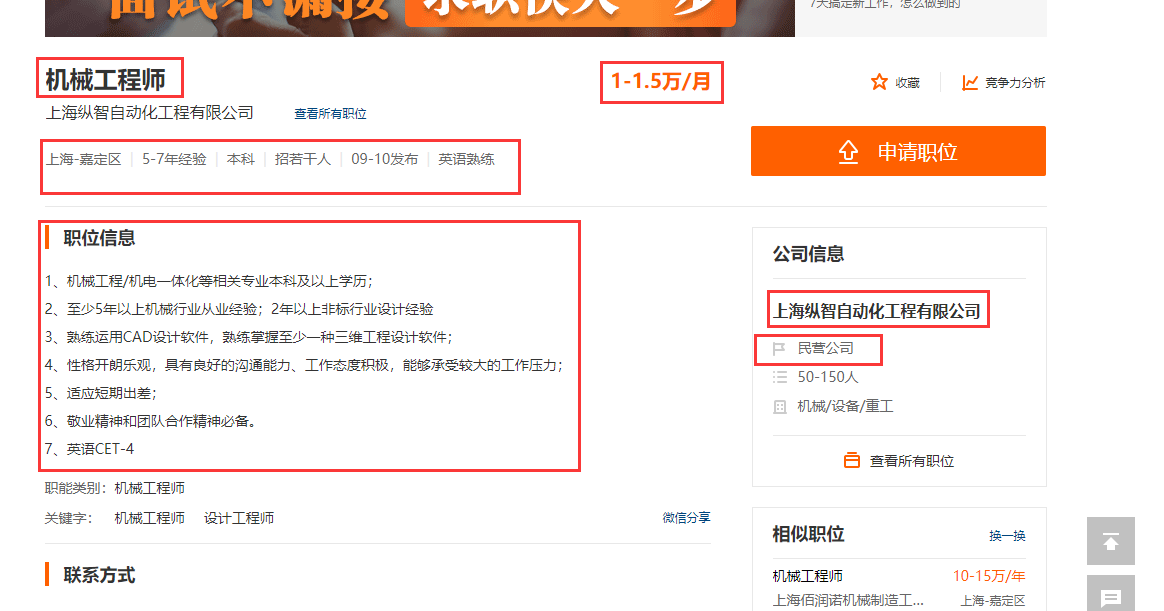
这里面的字段还不足以满足我们的需求,还想获取职位描述,和公司的类型,例如国企还是民营等这些数据。于是我们点开看看每一条数据的字段。
框起来的就是我们要获取的内容。
接下来上代码,使用scrapy 提供的默认模板创建爬虫项目。
class A51jobSpider(scrapy.Spider):
name = '51job'
allowed_domains = ['51job.com']
keyword = quote('机械')
headers = {
'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
def start_requests(self):
'''获取开始抓取的页面'''
for i in range(1,1000):
url = 'https://search.51job.com/list/000000,000000,0000,00,9,99,'+ self.keyword + ',2,{}.html'.format(str(i))
yield scrapy.Request(url=url,headers=self.headers,callback=self.parse_detial_url)
def parse_detial_url(self,response):
'''获取详情页的url'''
s = etree.HTML(response.text)
detail_urls = s.xpath('//*[@id="resultList"]/div/p/span/a/@href')
for detial_url in detail_urls:
url = detial_url
yield scrapy.Request(url=url,headers=self.headers,callback=self.parse)
这里通过重写 start_request 获取详情信息图片的链接,接下来解析具体字段数据:
def parse(self, response):
'''解析详情页具体字段'''
item = JixieItem() # 实例化类
s = etree.HTML(response.text)
jobs = s.xpath('//div[@class="tHeader tHjob"]/div/div[1]/h1/text()')
if jobs:
item['job'] = jobs[0].strip()
else:
item['job'] = ''
companys = s.xpath('//div[@class="tHeader tHjob"]/div/div[1]/p[1]/a[1]/text()')
if companys:
item['company'] = companys[0].strip()
else:
item['company'] = ''
company_types = s.xpath('//div[@class="com_tag"]/p/text()')
if company_types:
item['company_type'] = company_types[0]
else:
item['company_type'] = ''
data = s.xpath('//div[@class="tHeader tHjob"]/div/div[1]/p[2]/text()')
if data:
item['area'] = data[0].strip()
item['experience'] = data[1].strip()
item['degree'] = data[2].strip()
salarys = s.xpath('//div[@class="tHeader tHjob"]/div/div[1]/strong/text()')
if salarys:
item['salary'] = salarys[0].strip()
else:
item['salary'] = ''
describes = re.findall(re.compile('<div class="bmsg job_msg inbox">(.*?)div class="mt10"', re.S), response.text)
if describes:
item['describe'] = describes[0].strip().replace('<p>', '').replace('</p>','').replace('<p>','').replace('<span>','').replace('</span>','').replace('\t','')
yield item
items.py 文件了定义了具体的字段。items 是保存爬取数据的容器,使用方法和字典差不多。不过,相比字典,item 多了额外的保护机制,可以避免拼写错误或者定义字段的错误。
class JixieItem(scrapy.Item):
# 定义抓取的字段
job = Field()
company = Field()
company_type = Field()
area = Field()
experience = Field()
degree = Field()
salary = Field()
describe = Field()
接下来把数据保存到 MongoDB 中,这里的代码格式是一样的,几乎不需要修改就可以从 scrapy 的文档中拿过来用:
class MongoPipeline(object):
def __init__(self,mongo_uri,mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls,crawler):
return cls(
mongo_uri = crawler.settings.get('MONGO_URI'),
mongo_db = crawler.settings.get('MONGO_DB')
)
def open_spider(self,spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self,item,spider):
name = item.__class__.__name__
self.db[name].insert(dict(item))
return item
def close_spider(self,spider):
self.client.close()
数据获取成功,看一下数据:
数据分析
这一部分才是重头戏
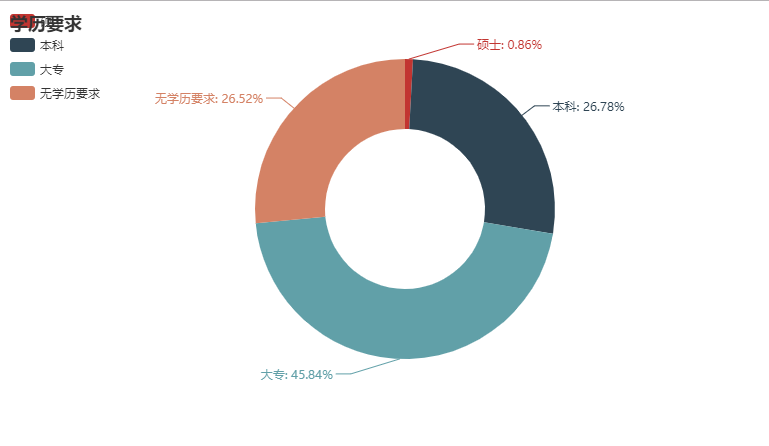
先看一下学历占比:
可以看到硕士需求不多,并不是说需求不多,而是在大的环境下,相对来说少。这里的大环境是指据统计全国本科及以上学历比例不到 10%
细心的小伙伴在求职时可以发现虽说公司打着学历要求不高,可任职要求已经完全超出了对学历的要求,所以能提高学历尽力提高学历,提高竞争力。
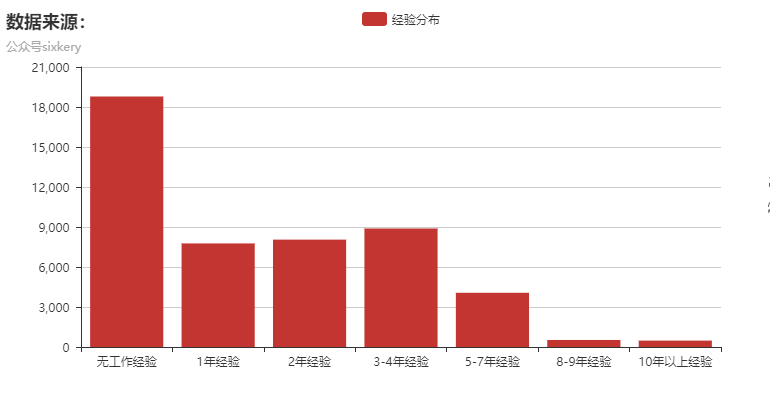
再来看一下工作经验在机械中的要求:
可以看到机械相关职位在招聘时对工作经验的要求占了很大的一部分,这对应届毕业生求职来说可是个好消息。同时看到五年以后的需求没有那么大了,这是招聘公司不需要工作经验久的员工了吗?
猜测
1、对于机械行业来说,公司福利待遇基本上一样,求职者在五六年经验后,基本生活工作稳定,不会再想着跳槽从新开始。
2、现在招聘旺季是给应届毕业生。
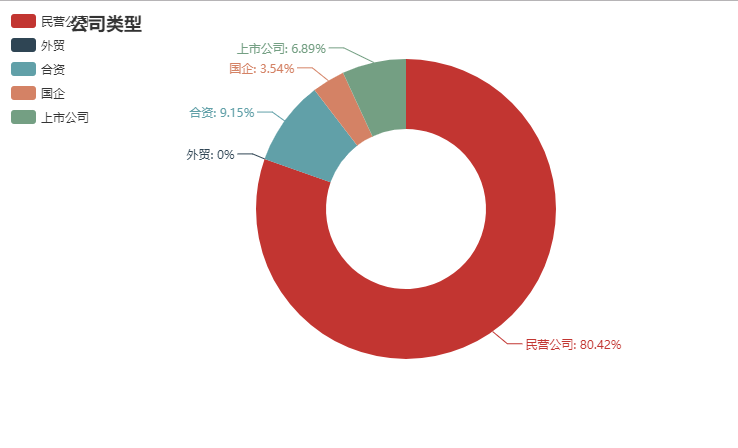
虽说民营公司占了大部分,但是能去国企还是尽量去国企。在同等情况下上市公司和有融资的公司都是不错的选择(工资高,福利好),当然在你拿到对应 offer 再说吧。
这里是根据职位描述生成的词云图,由于数据量比较大,这张图的参考价值不是很大,其实是想获取哪些具体的专业技能要求最多,但还是看出绘图软件需求高一些。同时不能忽略软实力的重要,办公软件也是要熟练掌握的。
总结
综上所述,机械的就业前景还是挺不错的,同时自身实力过硬也是必须的。没事的时候看看招聘网站上的任职要求和自身实力匹配一下,补充一下自身实力,在招聘的时候才能有所进退。
最后点赞是一种态度。