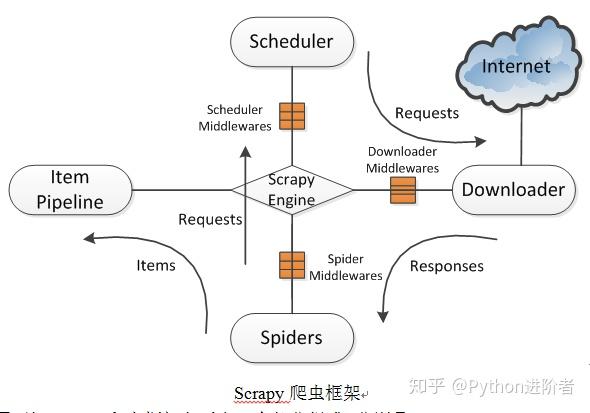
 Scrapy爬虫框架
Scrapy爬虫框架

云栖科技评论82期:乌镇上的产业新常态
【卷首语】乌镇上的产业新常态 乌镇的世界互联网大会办到了第五届,已经成为互联网乃至科技行业最受关注的全球性大会之一,两年前,世界互联网大会开始面向全球发布领先科技成果,到了今年已是第三次,成为大会上最受关注的发布活动之一。 在世界互联网大会第三次面向全球发布领先科技成果前,大会向全球范围内的互联网企业、高等院校、科研机构和个人发出成果征集邀请,收到来自20个国家的400余项互联网领域创新成果,最终,评选出年度十五项代表性领先科技成果。 今年获评的15项成果涵盖范围广泛、技术各具特色,既有清华大学CPU硬件安全动态监测管控技术,也有阿里云supET工业互联网平台,安谋科技Arm China AI Platform Zhouyi、特斯拉智能售后服务、微软公司基于微控制器的物联网安全解决方案、小米面向智能家居的人工智能开放平台…