《TopK到底怎么答?》介绍了TopK的四种解法,其中随机选择 (randomized select) 最为经典,用减治法 (Reduce & Conquer) 的思想,将数据规模急速降低,总体复杂度为O(n)。
结尾挖了一个坑:求TopK,有没有比随机选择更快的方法呢?
空间换时间,是算法优化中最常见的手段,如果有相对充裕的内存,可以有更快的算法。
画外音:即使内存不够,也可以水平切分,使用分段的方法来操作,减少每次内存使用量。
TopK问题描述
从arr[1, 12]={5,3,7,1,8,2,9,4,7,2,6,6} 这n=12个数中,找出最大的k=5个。
比特位图(bitmap)法
bitmap,是空间换时间的典型代表。它是一种,用若干个bit来表示集合的数据结构。
例如,集合S={1,3,5,7,9},容易发现,S中所有元素都在1-16之间,于是,可以用16个bit来表示这个集合:存在于集合中的元素,对应bit置1,否则置0。
画外音:究竟需要多少存存储空间,取决于集合中元素的值域,在什么范围之内。
上述集合S,可以用1010101010000000这样一个16bit的bitmap来表示,其中,第1, 3, 5, 7, 9个bit位置是1。
假设TopK的n个元素都是int,且元素之间没有重复,只需要申请2^32个bit,即4G的内存,就能够用bitmap表示这n元素。
扫描一次所有n个元素,以生成bitmap,其时间复杂度是O(n)。生成后,取TopK只需要找到最高位的k个bit即可。算法总时间复杂度也是O(n)。
伪代码为:
bitmap[4G] = make_bitmap(arr[1, n]);
return bitmap[top k bits];
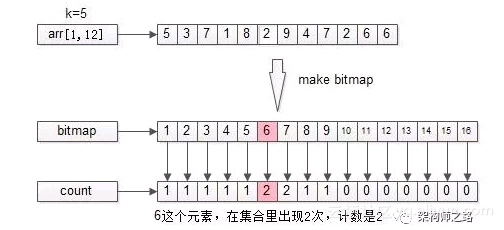
bitmap算法有个缺点,如果集合元素有重复,相同的元素会被去重,假设集合S中有5个1,最终S制作成bitmap后,这5个1只对应1个bit位,相当于4个元素被丢掉了,这样会导致,找到的TopK不准。该怎么优化呢?
比特位图计数
优化方法是,每个元素的1个bit变成1个计数。
![ae3e22b8f94302a3f515b915aa50a4607e701bcb]()
如上图所示,TopK的集合经过比特位图计数处理后,会记录每个bit对应在集合S中出现过多少次。
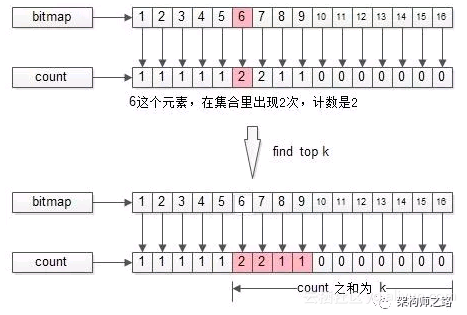
接下来,找TopK的过程,就是bitmap从高位的计数开始,往低位的计数扫描,得到count之和等于k,对应的bit就是TopK所求。
![25113ecc4910ae219990ae0b2ced381f943772fe]()
如上图所示,k=5:
(1)第一个非0的count是1,对应的bit是9;
(2)第二个非0的count也是1,对应的bit是8;
(3)第三个非0的count是2,对应的bit是7;
(4)第四个非0的count是2,对应的bit是6,但TopK只缺1个数字了,故只有1个6入选;
故,最终的TopK={9, 8, 7, 7, 6}。
结论:通过比特位图精准计数的方式,求解TopK,算法整体只需要不到2次扫描,时间复杂度为O(n),比减治法的随机选择会更快。
为了巩固今天的内容,例行挖个坑。
面试中,还有个问题问得比较多:求一个正整数的二进制表示包含多少个1?
例如:7的二进制表示是111,即7的二进制表示包含3个1。
画外音:我面试过程中从不问这个问题。
最常见的解法是:
uint32_t count_one(uint32_t n){
uint32_t count=0;
while(n){
count ++;
n &= (n-1);
}
return count;
}
提问:还有多少种更快的方法呢?
原文发布时间为:2018-09-25
本文作者:58沈剑
本文来自云栖社区合作伙伴“架构师之路”,了解相关信息可以关注“架构师之路”