它山之石,可以攻玉——要谈大数据平台的建设目标,首先要知道业界先进的实践经验,了解别人的数据平台是怎样的,然后才能结合自己公司的实际情况设定合适的目标和方向。
1 别人的大数据平台是怎样的
那么,别人的大数据平台是怎样的呢?如果参加过一些大大小小的技术分享论坛或会议,你应该不难发现,在各种各样新的诸如“×××公司大数据平台实践无敌干货分享”之类的PPT中,谈到大数据平台的技术组件时,多半都会给出一个大同小异的系统架构图。
在这个架构图中,各种日志和DB数据采集组件、存储和计算引擎、监控和调度系统,不管在实践中真实的应用情况如何,反正在图上所有组件一个都不缺,除了个别组件的增减替换,每家公司的大数据平台看起来都没有太大的区别。
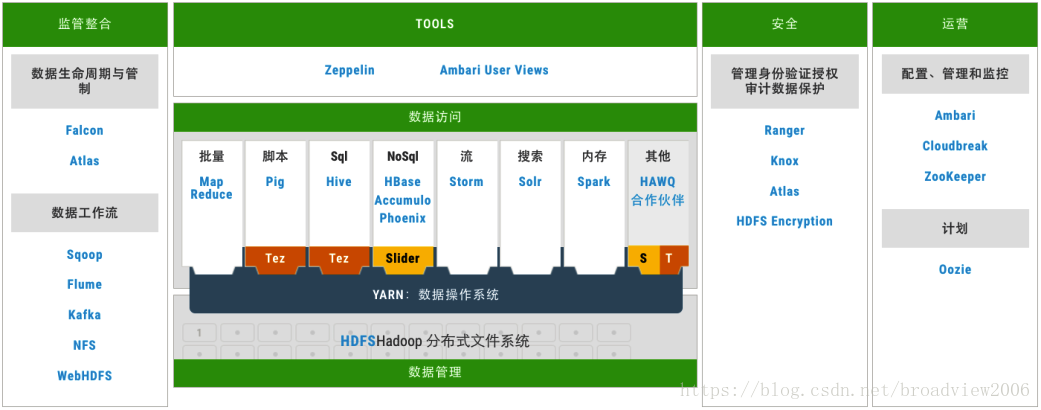
所以,如果你要问大数据平台的基础架构图长什么样,不用自己画,直接用HortonWorks公司的HDP发行版套件图来展示,估计也没啥大的不妥,如下图所示。
![]()
![]()
除了各种公开会议,过去的几年里我和北上杭的不少大数据平台从业者也常常有各种私下的交流,在交流的过程中,讨论到大数据平台的建设方向的时候,也有些人很直白地和我说:别折腾了,大数据平台建设的整体思路其实都差不多,随便找一两家靠谱的公司交流一下就好了。
所以,谈到大数据平台的技术交流,貌似可以比较的只是具体组件方面的技术细节、组件的性能、平台的稳定性,以及各自的开发平台与公司的具体业务流程的适配和应用等方面。
如此看来,稍微靠谱一点的公司的大数据平台,整体的水平应该都在差不多的水平线上,差距只是踩坑的多少和经验的积累程度吧?
那么,现实果真如此吗?显然不太可能!
2 和业内领先的大数据平台的差距
以蘑菇街的大数据平台为例,客观地说,和顶尖的行业巨头,比如阿里、腾讯的大数据平台的整体建设水平相比,有不小的差距肯定是不用怀疑的。只不过这些差距真的仅仅体现在具体组件的技术深度层面吗?我认为事情并没有那么简单。
我也接触过大量来面试我们的大数据平台开发岗位的同学,他们中的不少人已经在各种各样的公司(有些其实也不是小公司)从事过数据平台的建设工作。
在与这些同学沟通他们的项目经历时发现,在不少公司的大数据平台体系中,大数据生态里的各种主流组件其实也是一样不少的,数据规模虽小,平台五脏俱全。如果要画平台的整体组件架构图,没准还会比蘑菇街的大数据平台多出两三个组件来。但是,一旦谈到平台的实际应用水平和所提供的服务的时候,这些公司的平台往往是极度原始和简陋的。
那么,各家公司的大数据平台的成熟度水平的差距到底体现在哪里呢?
纯粹论底层组件,抛开财大气粗,自打飞天项目开始,各种基础组件都要自己做一套的阿里不说,多数公司的大数据平台建设主要依托的还是成熟的开源组件,以及在这些组件上进行的优化改进和二次开发。
从技术层面来说,大家填坑的水平固然有差距,但填坑水平的差距真的就是导致各自平台整体水平差距的最重要因素吗?
对多数公司来说,你的业务远未达到BAT的规模,所以平台架构的理论先进性,各种极端负载情况下平台的稳定性,各种集群和资源的弹性拓展能力,对大数据平台的实际产出价值,真的会造成很大的影响吗?你的平台和别人的平台的差距真的是各种类似人工智能、流式SQL之类的新技术应用速度上的差距吗?早几年别人还没开始引进这些技术的时候,平台的服务能力不是一样甩你几条街吗?
换个角度举几个大家更熟悉的例子吧!
比如制造手机这件事,从外观上来看,不就是触摸屏外加摄像头吗?至于内部的组件配置,也不外乎蓝牙、WiFi、NFC、GPS、内存、CPU等,都有极端成熟的产业链支撑。所以,你觉得山寨机和iPhone的差距在哪里呢?
再比如消费级无人机,主体结构不就是电池、马达,外加几个螺旋桨吗?那么大疆的无人机又是怎么做到横扫各种竞争对手,市场占有率遥遥领先的呢?它的产品和淘宝上几十元一个的玩具四轴飞行器又有什么区别呢?
所以,在我看来,多数公司在大数据具体组件的应用水平方面固然存在差距,但这并不是平台整体成熟度差距的根本所在。
而且,在一些具体组件的技术深度和先进技术的探索方面,小公司和大公司是无法看齐的——由于与大公司在体量和人才储备方面存在现实差距,小公司多半是学不来也赶不上的。从支撑公司业务发展和人员投入产出效益的角度来说,小公司也没有必要去学这些,大不了等到相关技术成熟的时候拿过来用就好了。
那么,差距到底在哪里呢?我认为,产品和服务形态这些看起来偏软性的、容易被忽略的方面,才是体现各家大数据平台成熟度水平最核心的因素。幸运的是,产品和服务的建设思想,也是有可能快速学习、借鉴、改进和提高的,前提是你真正意识到并重视这方面差距的存在。
3 大数据平台建设目标小结
所以,大数据平台建设的目标是什么?是比拼谁的组件更丰富,谁跟进社区技术跟进得更快,谁的团队拥有更多的Committer?No,No,No!这些方面最多也只能算手段,而非目标,甚至都不一定是实现目标最有效的手段。
评估大数据平台的能力和成熟度,重点不在于你提供了多少种存储计算引擎,覆盖了大数据生态圈多少技术组件,或者你的团队的技术能力有多么无敌。而是你为使用平台的用户解决了哪些问题,扫除了哪些障碍,提升了多少工作效率,附加了哪些增值收益。进一步来说,还包括平台内部组件的横向联通能力和业务流程上纵向贯穿打通上下游链路的能力,这些才是数据平台建设的根本目标和衡量平台成熟度水平的评估标准。
这不是我鼓吹用户至上所喊出的无关痛痒的漂亮话,这是我们在过去多年的实践中,对实际的经验教训的总结。不过,所谓知易行难,每隔一段时间,你可能都会发现之前所做的工作和这个目标还是有不小的差距。加上公司业务会发展,技术会变革,大数据平台建设目标的确定也不可能一成不变,是一个需要持续思考和检验的过程。
本文选自《大数据平台基础架构指南》,作者刘旭晖,电子工业出版社7月出版。
![]()