分享一篇大神的关于hanlp分词命名实体提取的经验文章,文章中分享的内容略有一段时间(使用的hanlp版本比较老),最新一版的hanlp已经出来了,也可以去看看新版的hanlp在这方面有何提升!
文本挖掘是抽取有效、新颖、有用、可理解的、散布在文本文件中的有价值知识,并且利用这些知识更好地组织信息的过程。对于文本来说,由于语言组织形式各异,表达方式多样,文本里面提到的很多要素,如人名、手机号、组织名、地名等都称之为实体。在工程领域,招投标文件里的这些实体信息至关重要。利用自然语言处理技术从形式各异的文件中提取出这些实体,能有效提高工作效率和挖掘实体之间的潜在联系。
文本预处理
1、文本清洗
目前,大部分招中标项目信息都是发布在各个网站上,所以我们获取的主要是网络文本。网页中存在很多与文本内容无关的信息,比如广告,导航栏,html、js代码,注释等等。文本清洗,就是通过正则匹配去掉这些干扰信息,抽取出干净的文本内容。
2、中文分词
中文分词(Chinese Word Segmentation) 指的是将一个汉字序列切分成一个一个单独的词。分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。一篇文本中不是所有词都很重要,我们只需找出起到关键作用、决定文本主要内容的词进行分析即可。目前几大主流的分词技术可移步到这篇博客中:中文分词技术小结、几大分词引擎的介绍与比较
笔者采用的是HanLP分词工具。
HanLP是由一系列模型与算法组成的Java工具包,目标是普及自然语言处理在生产环境中的应用。HanLP具备功能完善、性能高效、架构清晰、语料时新、可自定义的特点。
HanLP提供下列功能:
中文分词
1.最短路分词(Dijkstra精度已经足够,且速度比N最短快几倍)
2.N-最短路分词(与Dijkstra对比,D已够用)
3.CRF分词(对新词较有效)
4.索引分词(长词切分,索引所有可能词)
5.极速词典分词(速度快,精度一般)
6.用户自定义词典
7.标准分词(HMM-Viterbi)
命名实体识别
1.实体机构名识别(层叠HMM-Viterbi)
2.中国人名识别(HMM-Viterbi)
3.音译人名识别(层叠隐马模型)
4.日本人名识别(层叠隐马模型)
5.地名识别(HMM-Viterbi)
篇章理解
1.关键词提取( TextRank关键词提取)
2.自动摘要( TextRank自动摘要,提取关键句子)
3.短语提取( 基于互信息和左右信息熵的短语提取)
简繁拼音转换
1.拼音转换( 多音字,声母,韵母,声调)
2.简繁转换(繁体中文分词,简繁分歧词)
智能推荐
1.文本推荐(句子级别,从一系列句子中挑出与输入句子/词语最相似的那一句)
2.语义距离(基于《同义词词林扩展版》)
命名实体提取
HanLP分词提供词性标注的功能,所以调用分词接口后获得带有词性标注的单词集合。例如:
String word = "河南大明建设工程管理有限公司受林州市水土保持生态建设管理局委托,
林州市合涧镇刘家凹小流域2017年省级水土保持补偿费项目进行了公开招标";
List<Term> termList= HanLP.segment( word );
System.out.println(termList.toString());
得到的输出结果为:
[河南/ns, 大明/nz, 建设工程/nz, 管理/vn, 有限公司/nis, 受/v, 林州市/ns, 水土保持/gg, 生态/n, 建设/vn, 管理局/nis, 委托/vn, ,/w, 就/d, 林州市/ns, 合涧镇/ns, 刘家凹/nr, 小流域/nz, 2017/m, 年/qt, 省级/b, 水土保持/gg, 补偿费/n, 项目/n, 进行/vn, 了/ule, 公开招标/v]
每个词性代表什么可以参考 HanLP词性标注集
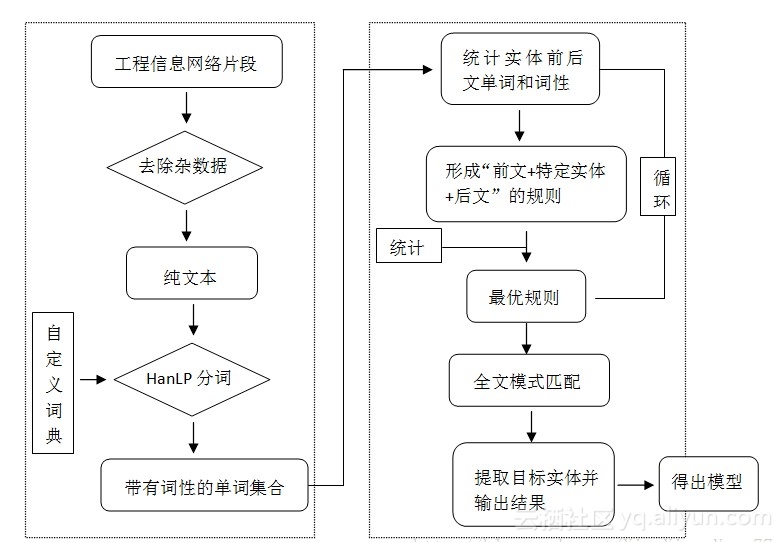
招中标项目文本样式多变、内容复杂,我们无法直接定位文本中的某一位置来提取实体。小编采用基于统计和基于规则相融合的机器学习方法。
首先,统计这些实体出现的前后文单词和词性,并考虑他们之间的联系,概括出特定实体前后出现的高频词汇。
其次,利用这些高频词汇构建出“前文+特定实体+后文”的规则。
最后,利用这一规则在全文中进行模式匹配。利用投票原理,对匹配度高的规则分配高分,相反,匹配度低的规则赋予低分。然后,对所有匹配的规则进行分数排序,得到投票分数最高的规则,并从规则中剥离出特定实体,这个实体即为我们的目标实体。
例如,招标单位的提取,我们统计出改实体出现的前文频率较高的为:招标人、招标单位、建设单位、采购人、采购单位、业主等,后文为:委托、招标等。通常出现这些词汇的前后就是招标单位。然后我们再根据这个词的词性,判断它是否属于机构名、团体名。如果是机构团体名,则判定该单词为招标单位名称。这样,就可以获得我们需要的实体。其他实体的提取与此类似。
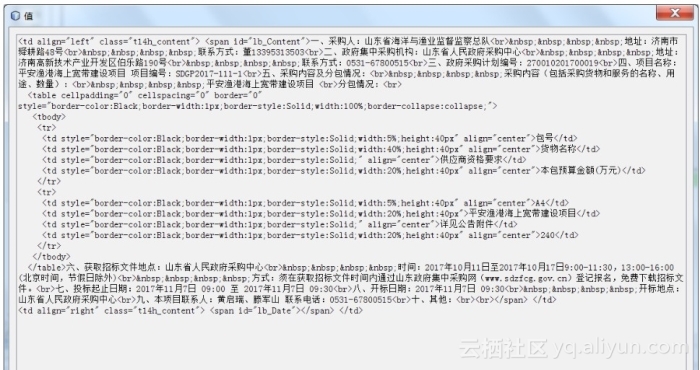
如下图:我们获得的文本是网络片段
![70c8bf1b9dd6660644e353b2e1c7df1363c7454e]()
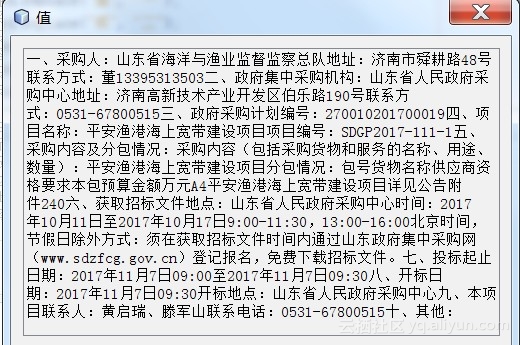
去除标签、杂数据,得到的纯文本为:
![ebc0351abd9a3eaf175751fb6a9e907bd55a90ed]()
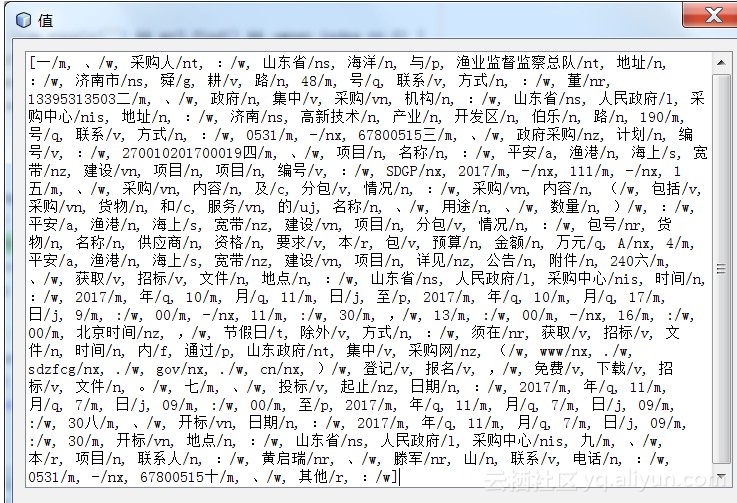
调用HanLP分词接口,得到下图的分词列表:
1.Â
Segment segment = HanLP.newSegment().enableOrganizationRecognize(true);
2. List<Term> termList = segment.seg(content);
![31105aa2a5679c649a51184fd7df731f54d17b53]()
最后,根据“前文+特定实体+后文”正则匹配,得出提取的实体,如下图:
![3361b6552fe18fb2a68a62a2108f230006115a0e]()
技术实施流程图
![0e9f2ade1732007507b406de85d6d17b35c69768]()
作者:XiaoXiao_Yang77