方向是自然语言处理的同学们有福啦,为了跟踪自然语言处理(NLP)的进展,有大量仁人志士在 Github 上维护了一个名为 NLP-Progress 的库。它记录了几乎所有NLP任务的 baseline 和 标准数据集,同时还记录了这些问题的state-of-the-art。
● Github
● https://github.com/sebastianruder/NLP-progress
● 官方网址
● https://nlpprogress.com/
● 整理报道
● huaiwen
NLP-Progress 同时涵盖了传统的NLP任务,如依赖解析和词性标注,和一些新的任务,如阅读理解和自然语言推理。它的不仅为读者提供这些任务的 baseline 和 标准数据集,还记录了这些问题的state-of-the-art。
下面小编简单列举了几个NLP-Progress 记录的任务:
● Coreference resolution 共指消解
● Dependency parsing 依存分析
● Dialogue 对话
● Domain Adaption 领域迁移
● Entity Linking 实体链接
● Information extraction 信息抽取
● Language modeling 语言模型
● Machine translation 机器翻译
● Multi-task learning 多任务学习
● Multi-modal 多模态
● Named entity recognition 命名实体是被
● Natural language inference 自然语言推理
● Part-of-speech tagging 词性标注
● Question answering 问答
● Relation prediction 关系预测
● Relationship extraction 关系抽取
● Semantic textual similarity 语义文本相似性
● Semantic parsing 语义分析
● Semantic role labeling 语义角色标注
● Sentiment analysis 情感分析
● Summarization 文本照耀
● Taxonomy learning 分类结构学习
● Temporal processing 时序分析
● Text classification 文本分类
● Word sense disambiguation 词义消岐
● 。。。
● 。。。
对于每一个任务,NLP-Progress都会简单介绍一下这个任务是做什么的,并详细列出公开的标准数据集,以及在该数据集上各个模型目前的排名情况。比如,比较火的Question answering 问答系统任务,它的组织形式如下:
![b7e79e61cba09e1ca6453901f3d8b2e6e2ff110b]()
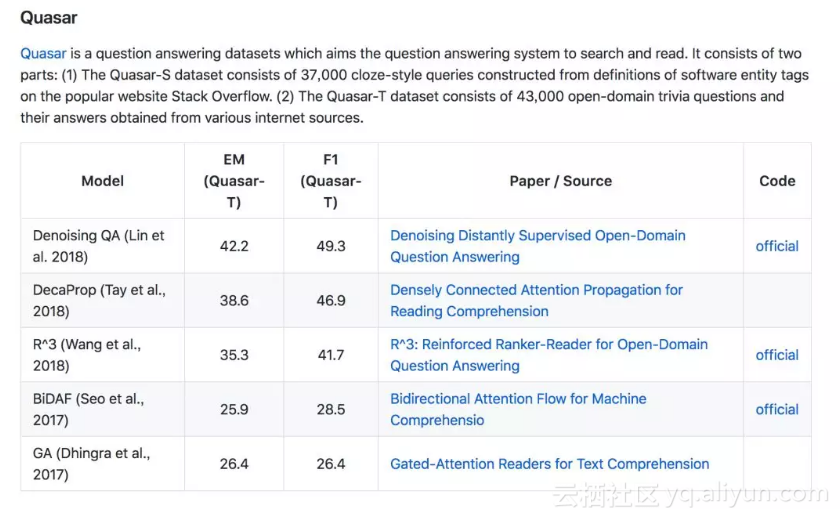
具体到某一个开放数据集,如 Quasar, 贡献者会简单介绍该数据集的组成,然后列出论文排行榜,其中每一行都包括:模型,效果,文章名和链接,以及代码链接。
![e82bc534f2b5b7119ffdfccc2eb8f7701f4a8bbc]()
还等什么,赶紧去 Star一下。
原文发布时间为:2018-11-15
本文来自云栖社区合作伙伴“专知”,了解相关信息可以关注“专知”。