如果你是一名数据科学方面的求职者,你肯定想知道在简历上写些什么才能获得面试的机会;如果你想进入这个领域,你一定想知道具备哪些技术才能成为一名有竞争力的求职者。
在本文中,我们对美国求职网站 Indeed 中一千份数据科学相关的招聘信息进行了分析,主要针对数据工程师、数据科学家和机器学习工程师这三个职位,希望能解答你的疑问。
首先,让我们来看看不同职位的技能要求。
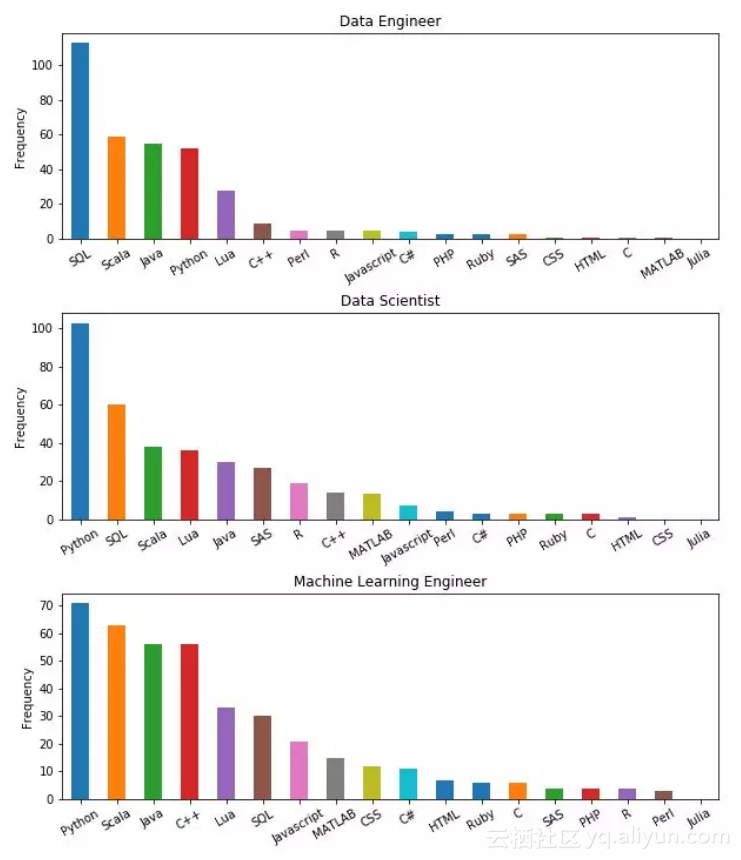
一、必备语言
1. Python 是数据科学家的首选语言
关于数据科学中的首选语言究竟是Python还是R曾有过争论。显然,根据市场需求,如今处于主导地位是Python。同样值得注意的是,从语言需求的排名来看,R语言可能还排在SAS之后。因此,如果你打算进入数据科学领域,不妨把学习重点放在Python上。作为数据库语言,SQL是数据科学家第二重要的语言。由于数据科学家职业的广泛性,其他语言也扮演着重要角色。
数据科学家必备语言排名为:Python、SQL、Scala、Lua、Java、SAS、R、C ++和Matlab。
2. 机器学习工程师使用的语言更加多样化
Python是机器学习工程师的首选语言,这并不令人惊讶。机器学习工程师需要从头开始实现算法,并在大数据环境中部署ML模型,因此C ++和Scala等相关语言也很重要。总的来说,机器学习工程师使用的语言更加多样化。
机器学习工程师必备语言排名为:Python、Scala、Java、C ++、Lua、SQL、Javascript、Matlab、CSS和C#。
3. SQL 是数据工程师的必备技能
数据工程师一直都在于数据库打交道,而SQL是数据库语言,因此SQL是首选语言也就不足为奇了。同时Python也重要,但重要性排在Scala和Java之后,因为后者能够帮助数据工程师处理大数据。
数据工程师必备语言排名为:SQL、Scala、Java、Python和Lua。
4. Scala 逐渐成为数据科学中第二重要的语言(而不是R语言)
当我们研究分析不同职位时发现,对Scala的需求排在第二或第三名。因此我们得出,数据科学领域排名前三的语言是Python、SQL和Scala。如果你打算学一门新语言,可以试试Scala。
![8eefd0107f3708fa41878c4da2514b5d83e17026]()
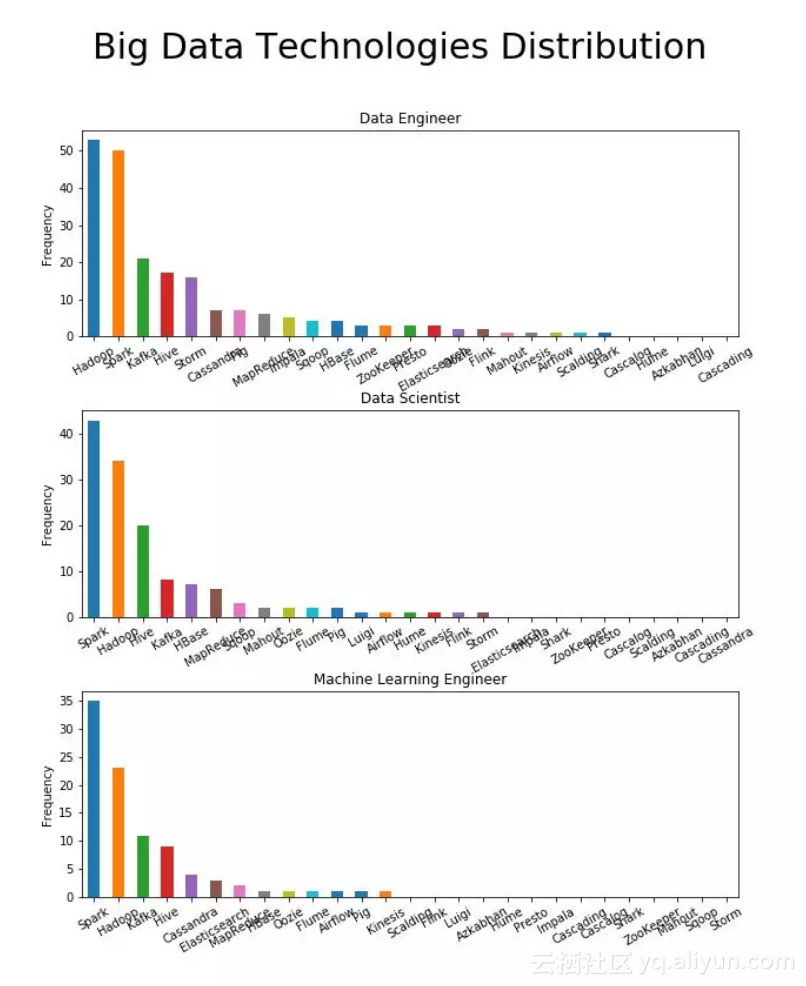
二、大数据技能
Spark是最必备的大数据技能(数据工程师除外)
仅对数据工程师而言,Hadoop比Spark更为重要。但总的来说,Spark绝对是应该首先学习的大数据框架。相对于数据科学家,Cassandra对工程师更为重要,而似乎只有数据工程师才需要用Storm。
数据科学领域必备的大数据技术排名为:Spark、Hadoop、Kafka、Hive。
![2a9ce7171501fd0b7b05b5345b612fb0ee1a6f32]()
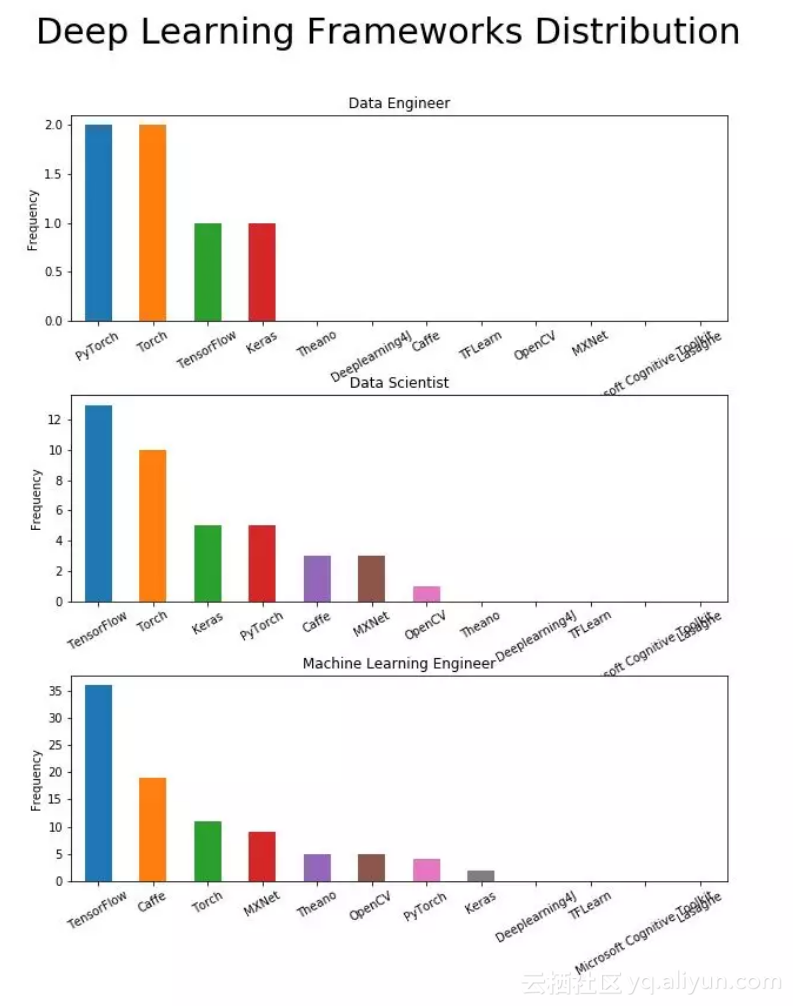
三、 深度学习框架
深度学习方面,TensorFlow 占主导地位
在数据工程师的招聘中很少提到深度学习框架,该职位可能不需要用到深度学习框架;在机器学习工程师招聘中,常常提到深度学习框架,这表明机器学习工程师需要处理机器学习建模,而不仅仅是模型部署。
此外,TensorFlow在深度学习领域绝对占据主导地位。尽管Keras作为高级深度学习框架在数据科学家中非常受欢迎,但对于机器学习工程师职位,很少要求要掌握Keras,这可能表明机器学习从业者大多使用较低级别的框架,如TensorFlow。
数据科学中要掌握的深度学习框架排名为:TensorFlow、Torch、Caffee和MXNet。
![531329462f69de1331eac00284a2b7fdf2dbba0c]()
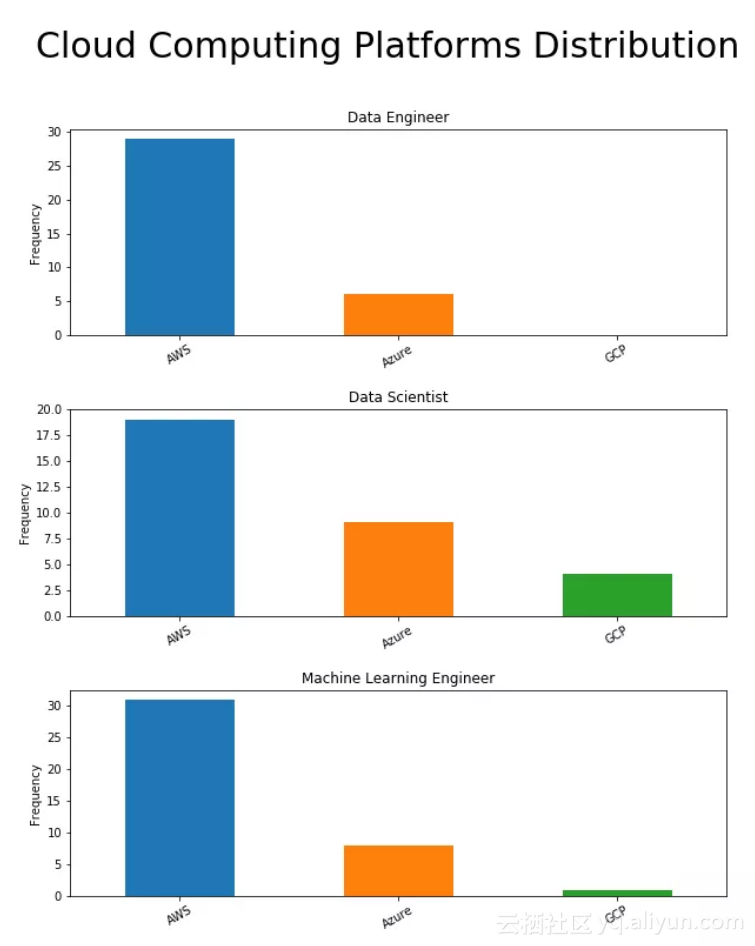
四、云计算平台
AWS占据主导地位。
![c18fe0b68ddeb40815807c1a55af0f6fc0317793]()
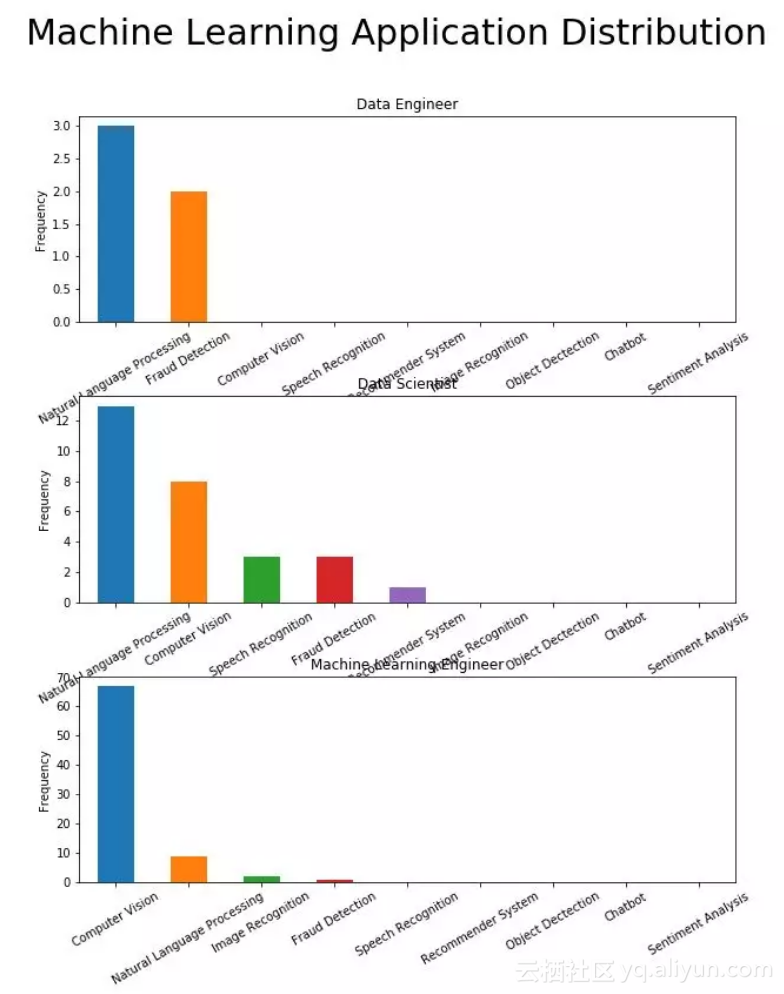
五、机器学习应用
机器学习方面,计算机视觉是最主要的技能需求
对于一般数据科学家来说,机器学习最大的应用领域是自然语言处理,其次是计算机视觉、语音识别、欺诈检测和推荐系统。有趣的是,在机器学习工程师职位招聘中,最大的需求是计算机视觉,其次才是自然语言处理。
另一方面,机器学习方面数据工程师再次成为备受专注,然而这些机器学习应用领域与他们并没有关系。
如果想成为数据科学家,你可以想进入的领域,选择不同类型的项目来展现专业知识,但对于机器学习工程师来说,计算机视觉是最佳选择!
![1273b13cfc5097087b923647e8b97f3d6fe75360]()
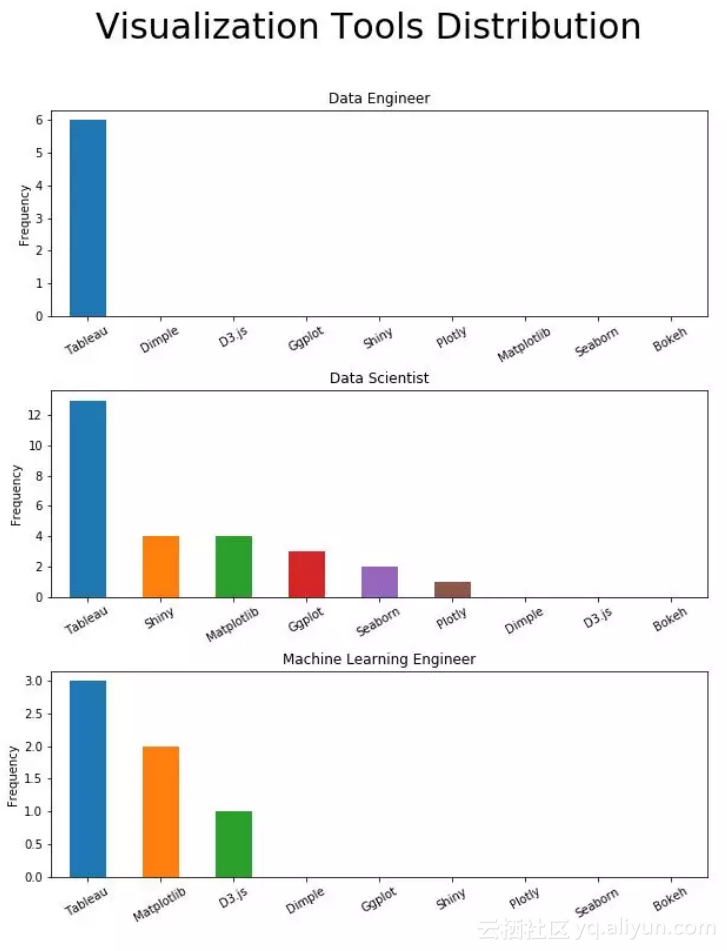
六、可视化工具
Tableau是可视化方面的必备技能
在招聘中,数据科学家大多都要求需要掌握可视化工具,而很少要求数据工程师和机器学习工程师掌握。然而对以上每个职位来说,Tableau都是首选。对于数据科学家,Shiny、Matplotlib、ggplot和Seaborn都同样重要。
![5cecd6dce65776e337f044dac4d85ebb516a07b5]()
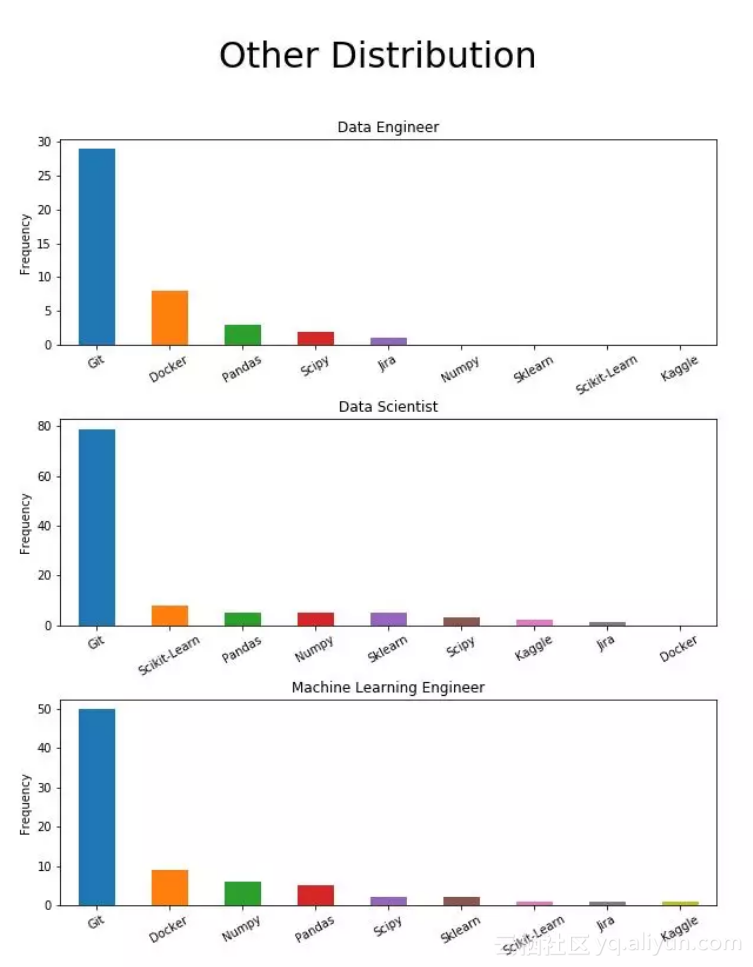
七、其他技能
在数据科学领域,Git对每种职位都都很重要,而Docker仅适用于数据工程师。
![d45ac0e6acbecaefb005cd80bd10384d0b524501]()
八、词云
接下来,我们使用词云来分析每个职位最常用的关键词,并结合相应的技能为所有数据科学角色构建理想的技能清单!
数据科学家:更注重机器学习,而不是业务或分析
数据科学家一直被认为是需要统计、分析、机器学习和商业知识的全方位职业。然而,现在看来在招聘数据科学家时,比起其他技能,更多地关注机器学习技能。
其他主要要求包括:业务、管理、通信、研究、开发、分析、产品、技术、统计、算法、模型、客户和计算机科学。
![70f862068ff8fde9e4342156ebdc5351ab20ab56]()
机器学习工程师:研究、系统设计和构建
与一般的数据科学家相比,机器学习工程师的技能要求更为集中,包括研究、设计和工程。显然,解决方案、产品、软件和系统是主要技能要求。除此之外还伴随着研究、算法、人工智能、深度学习和计算机视觉等要求。同时商业、管理、客户和沟通等也很重要。另一方面,管道和平台也很重要,这也印证了机器学习工程师主要负责构建数据管道,以及部署机器学习系统。
![10f42f0bf56673d5633cdc4b4df80cd81d7acb12]()
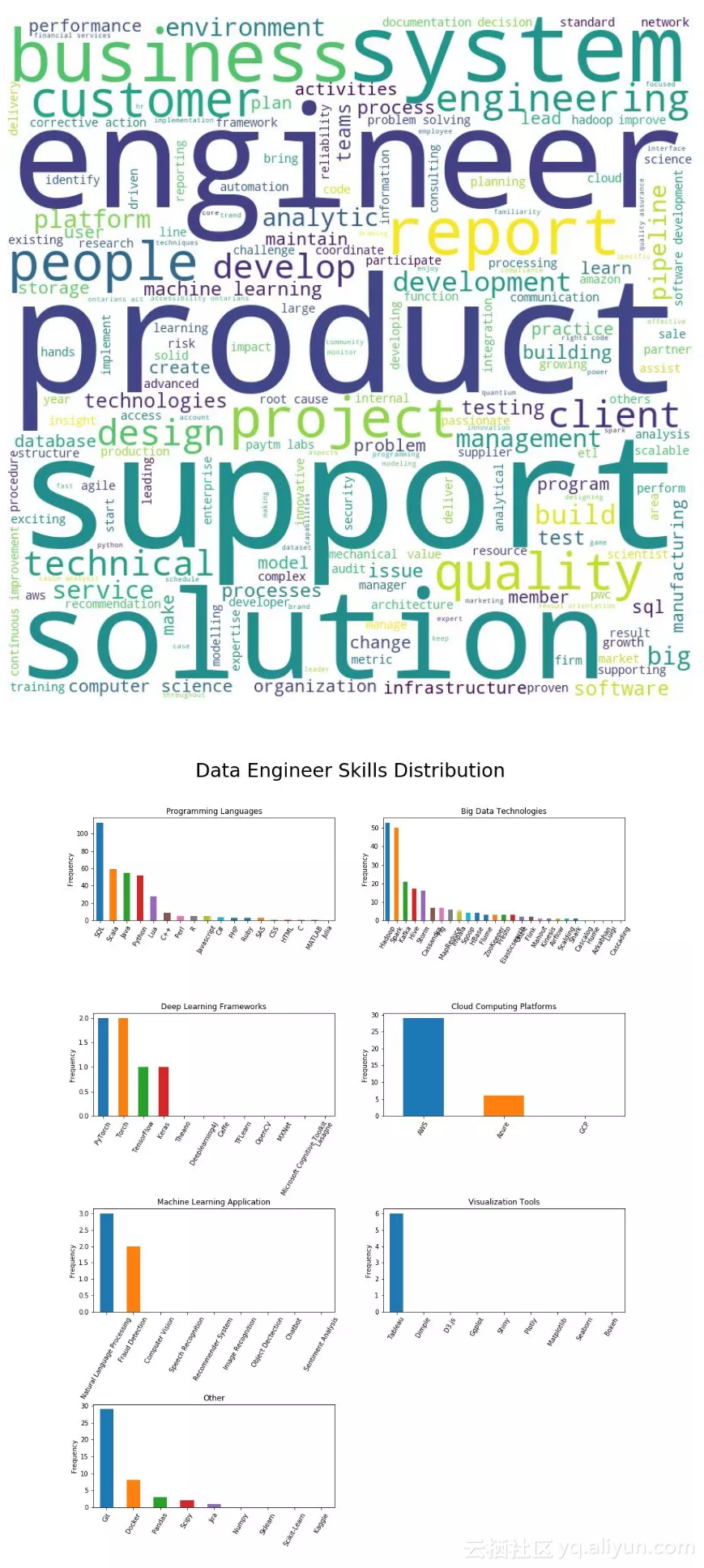
数据工程师:技能要求更为集中
与机器学习工程师相比,数据工程师的技能要求更集中。重点是通过设计和开发管道来支持产品、系统和解决方案。最主要的要求包括:技术技能、数据库、构建、测试、环境和质量。机器学习也很重要,可能因为构建管道主要为了支持机器学习模型部署数据需求。
![b719ae188896f39e01ce5542827f60b2ec6155ea]()
结语
希望通过本文能帮助你了解,在数据科学方面雇主最需要求职者的哪些技能,从而帮助你更好地制定学习计划,完善自己的技能清单。
原文发布时间为:2018-11-29
本文作者:
George Liu