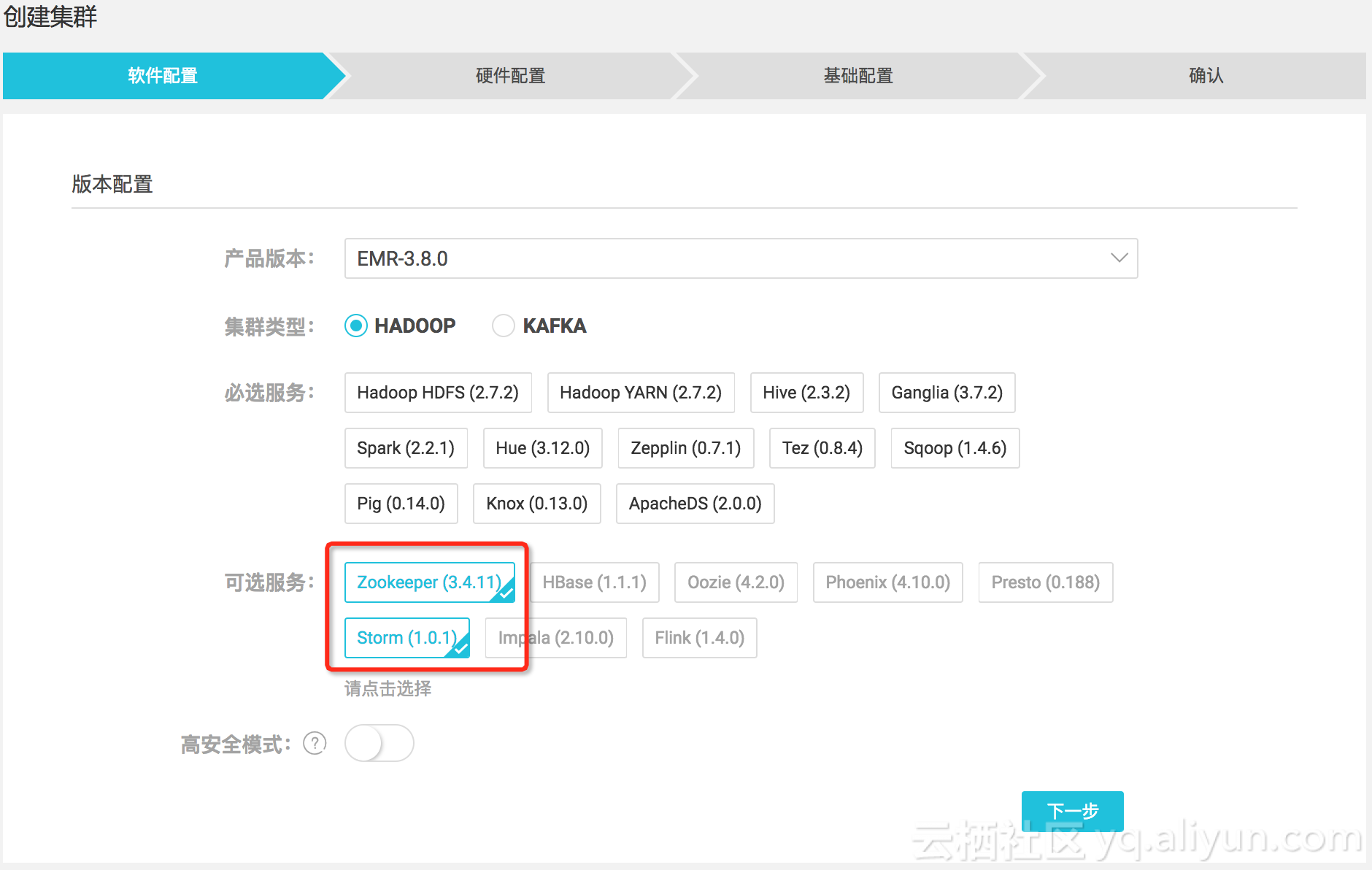
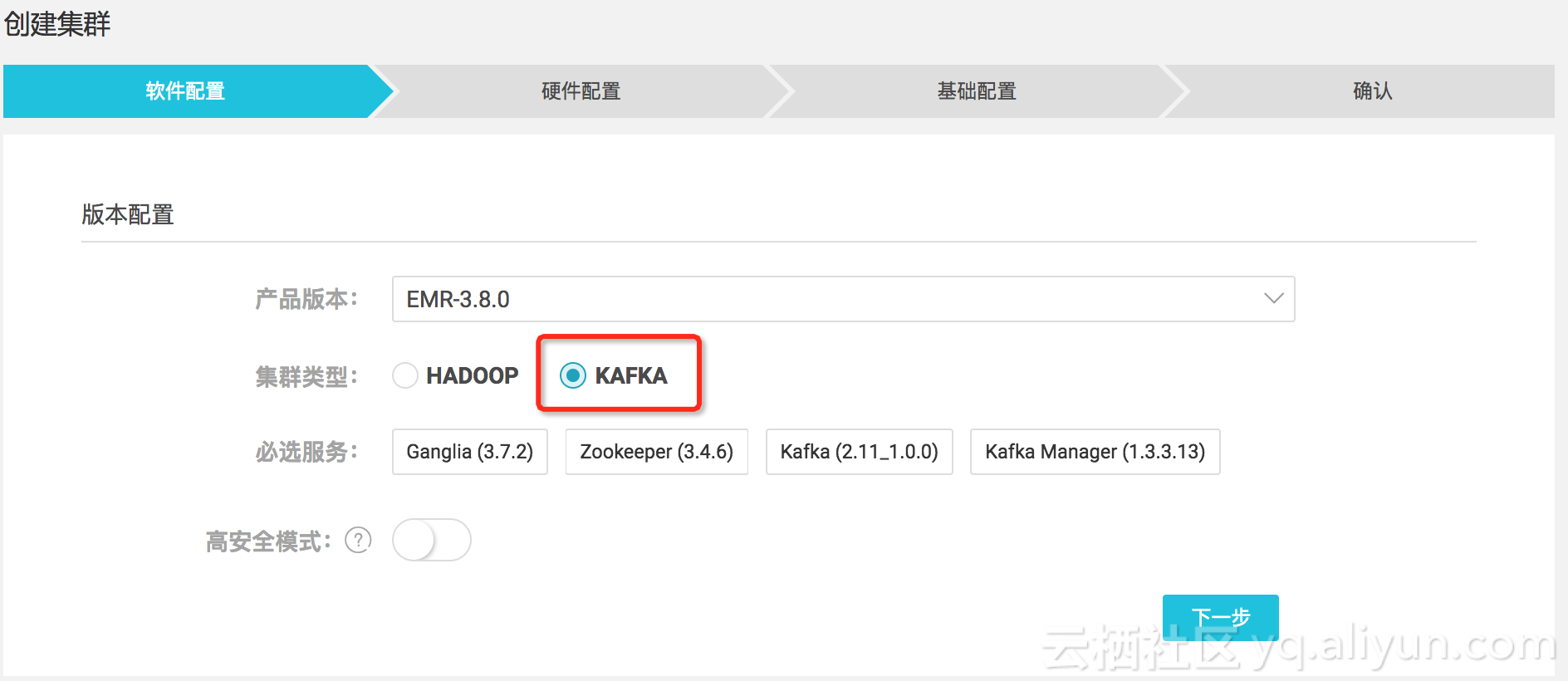

用 HBase 做高性能键值查询?
最近碰到几家用户在使用 HBase 或者试图使用 HBase 来做高性能查询,场景也比较类似,就是从几十亿甚至上百亿记录中按键值找出相关记录来。按说,这种 key-value 式的数据库很适合用键值查询,HBase 看起来就是个不错的选择。 然而,已经实施过的用户却反映:效果非常差! 其实,这是预料之中的结果,因为 HBase 根本不适合做这件事! 从实现原理上看,key-value 式的数据库无非也就是按 key 建了索引来查找。而索引技术,无论是传统数据库用的 B 树还是 NoSQL 数据库常用的 LSM 树,其本质都是利用键值有序,把遍历查找变成二分(或 n- 分)查找,在查找性能上并没有根本差异。LSM 树的优势在于一定程度克服了 B 树在更新时要面对的复杂的平衡调整,并利用了硬件的特点,对于并发高频写入的操作更为擅长,在读取方面却反而有所牺牲。而对于很少更新的历史数据,用 NoSQL 数据库在按键值查找时,和传统关系数据库相比,并不会有优势,大概率还会有劣势。 不过,对于只要找出一条记录的情况,这个优势或劣势是察觉不到的,就算差了 10 倍,也不过是 10 毫秒和 100 毫...