1 环境准备
1 准备三台cenots7环境,设置好ip hostname。
192.168.1.94 es1
192.168.1.92 es2
192.168.1.93 es3
并将这些信息添加到/etc/hosts,确保能够通过hostname访问
2 下载elasticsearch以及jdk
https://www.elastic.co/downloads/elasticsearch
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
请都选择rpm版本下载,复制到三太服务器上。
3 安装jdk以及elasticsearch
在三台服务都要执行
rpm -i jdk-8u181-linux-x64.rpm
rpm -i elasticsearch-6.3.2.rpm
systemctl enable elasticsearch.service
systemctl start elasticsearch.service
systemctl disable firewalld
systemctl stop firewalld
添加elasticsearch服务自动启动,以及关闭防火墙,这为了方便起见直接关闭防火墙。
2配置
1 es1配置
vi /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster-dev
node.name: es1
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["es1", "es2"]
编辑后保存
cluster.name为集群名称,注意别和其他集群同名,否则可能会加错集群。
node.name当前节点的hostname
path.data 为数据的目录
path.logs为es本身的log目录
network.host 为绑定的ip,0.0.0.0就是对所有的ip开放
http.port 9200为es restapi的端口号。9300 为集群间通信端口。
discovery.zen.ping.unicast.hosts: ["es3", "es2"] 为 #添加集群中的主机地址,会自动发现并自动选择master主节点 ,注意由于集群是可能动态扩展的,在使用中会动态加节点,但是这里只要写当前的集群节点就可以了。后面会做演示
systemctl restart elasticsearch.service
重启服务后打开http://192.168.1.94:9200/_cluster/state?pretty
![a0968c768152f008847d7a0639abfcc20dd.jpg]()
可以看到当前集群只有一个节点es1,并且为主节点。
2 es2配置
vi /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster-dev
node.name: es2
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["es1", "es2"]
systemctl restart elasticsearch.service
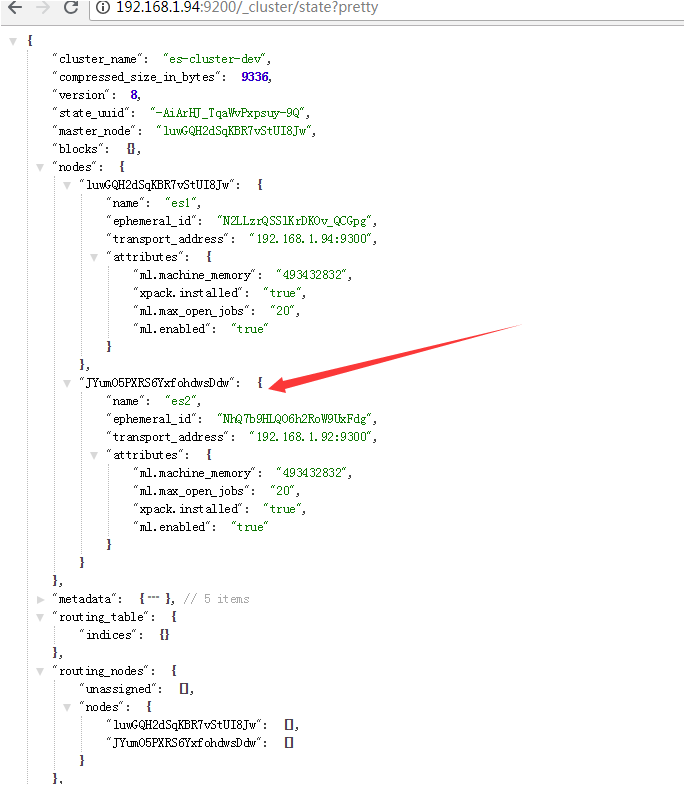
重启服务后打开http://192.168.1.94:9200/_cluster/state?pretty
![6314ef11f2e701ad5f20b949d211caf5a5a.jpg]()
es2已经加入集群
3 es3配置
vi /etc/elasticsearch/elasticsearch.yml
cluster.name: es-cluster-dev
node.name: es3
path.data: /var/lib/elasticsearch
path.logs: /var/log/elasticsearch
network.host: 0.0.0.0
http.port: 9200
discovery.zen.ping.unicast.hosts: ["es3", "es2"]
注意es3的配置集群主机地址并没有es1的信息,而且这个时候es1,es2也没有es3新加入节点的配置信息,但是这并不妨碍集群的创建。
systemctl restart elasticsearch.service
重启服务后打开http://192.168.1.94:9200/_cluster/state?pretty
![1d19291814000fc3b38d475772a3104f71d.jpg]()
es3已经加入集群
3 kibana安装
https://www.elastic.co/downloads/kibana
下载rpm版本直接rpm -i kibana.rpm
修改/etc/kibana/kibana.yml中的
server.host: 0.0.0.0
kibana直接通过localhost:9200来连接elasticsearch所以此操作只要在三个节点任一一个节点操作就可以了。
index的集群副本配置
index.number_of_replicas
最大值为节点总数-1,否则改索引的就会变成yello状态。改值的表示需要额外保存的副本数量,以防止数据数据的丢失,可以动态调整。
4 关闭服务
将es1关闭
![3cd164cbff31bec0b549e8a530148b38d02.jpg]()
可以看到es1已经从集群中退出
此时从另外节点上查询数据任然可以
![195ee4575f7cd6b39f58d9649523781c1d8.jpg]()
继续关闭服务器,在设置了合理的number_of_replicas数量下,数据查询依然是完整的。